Functional dependency
In relational database theory, a functional dependency is a constraint between two sets of attributes in a relation from a database.
Given a relation R, a set of attributes X in R is said to functionally determine another set of attributes Y, also in R, (written X → Y) if, and only if, each X value is associated with precisely one Y value; R is then said to satisfy the functional dependency X → Y. Equivalently, the projection  is a function, i.e. Y is a function of X.[1][2] In simple words, if the values for the X attributes are known (say they are x), then the values for the Y attributes corresponding to x can be determined by looking them up in any tuple of R containing x. Customarily X is called the determinant set and Y the dependent set. A functional dependency FD: X → Y is called trivial if Y is a subset of X.
is a function, i.e. Y is a function of X.[1][2] In simple words, if the values for the X attributes are known (say they are x), then the values for the Y attributes corresponding to x can be determined by looking them up in any tuple of R containing x. Customarily X is called the determinant set and Y the dependent set. A functional dependency FD: X → Y is called trivial if Y is a subset of X.
The determination of functional dependencies is an important part of designing databases in the relational model, and in database normalization and denormalization. A simple application of functional dependencies is Heath’s theorem; it says that a relation R over an attribute set U and satisfying a functional dependency X → Y can be safely split in two relations having the lossless-join decomposition property, namely into  where Z = U − XY are the rest of the attributes. (Unions of attribute sets are customarily denoted by mere juxtapositions in database theory.) An important notion in this context is a candidate key, defined as a minimal set of attributes that functionally determine all of the attributes in a relation. The functional dependencies, along with the attribute domains, are selected so as to generate constraints that would exclude as much data inappropriate to the user domain from the system as possible.
where Z = U − XY are the rest of the attributes. (Unions of attribute sets are customarily denoted by mere juxtapositions in database theory.) An important notion in this context is a candidate key, defined as a minimal set of attributes that functionally determine all of the attributes in a relation. The functional dependencies, along with the attribute domains, are selected so as to generate constraints that would exclude as much data inappropriate to the user domain from the system as possible.
A notion of logical implication is defined for functional dependencies in the following way: a set of functional dependencies  logically implies another set of dependencies
logically implies another set of dependencies  , if any relation R satisfying all dependencies from also satisfies all dependencies from ; this is usually written
, if any relation R satisfying all dependencies from also satisfies all dependencies from ; this is usually written 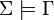 . The notion of logical implication for functional dependencies admits a sound and complete finite axiomatization, known as Armstrong's axioms.
. The notion of logical implication for functional dependencies admits a sound and complete finite axiomatization, known as Armstrong's axioms.
Examples
Cars
Suppose one is designing a system to track vehicles and the capacity of their engines. Each vehicle has a unique vehicle identification number (VIN). One would write VIN → EngineCapacity because it would be inappropriate for a vehicle's engine to have more than one capacity. (Assuming, in this case, that vehicles only have one engine.) However, EngineCapacity → VIN, is incorrect because there could be many vehicles with the same engine capacity.
This functional dependency may suggest that the attribute EngineCapacity be placed in a relation with candidate key VIN. However, that may not always be appropriate. For example, if that functional dependency occurs as a result of the transitive functional dependencies VIN → VehicleModel and VehicleModel → EngineCapacity then that would not result in a normalized relation.
Lectures
This example illustrates the concept of functional dependency. The situation modelled is that of college students visiting one or more lectures in each of which they are assigned a teaching assistant (TA). Let's further assume that every student is in some semester and is identified by a unique integer ID.
| StudentID | Semester | Lecture | TA |
|---|---|---|---|
| 1234 | 6 | Numerical Methods | Azhar |
| 2380 | 4 | Numerical Methods | Peter |
| 1234 | 6 | Visual Computing | Ahmed |
| 1201 | 4 | Numerical Methods | Peter |
| 1201 | 4 | Physics II | Simone |
We notice that whenever two rows in this table feature the same StudentID, they also necessarily have the same Semester values. This basic fact can be expressed by a functional dependency:
- StudentID → Semester.
Other nontrivial functional dependencies can be identified, for example:
- {StudentID, Lecture} → TA
- {StudentID, Lecture} → {TA, Semester}
The latter expresses the fact that the set {StudentID, Lecture} is a superkey of the relation.
Properties and axiomatization of functional dependencies
Given that X, Y, and Z are sets of attributes in a relation R, one can derive several properties of functional dependencies. Among the most important are the following, usually called Armstrong's axioms:[3]
- Reflexivity: If Y is a subset of X, then X → Y
- Augmentation: If X → Y, then XZ → YZ
- Transitivity: If X → Y and Y → Z, then X → Z
"Reflexivity" can be weakened to just 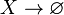 , i.e. it is an actual axiom, where the other two are proper inference rules, more precisely giving rise to the following rules of syntactic consequence:[4]
, i.e. it is an actual axiom, where the other two are proper inference rules, more precisely giving rise to the following rules of syntactic consequence:[4]


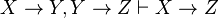 .
.
These three rules are a sound and complete axiomatization of functional dependencies. This axiomatization is sometimes described as finite because the number of inference rules is finite,[5] with the caveat that the axiom and rules of inference are all schemata, meaning that the X, Y and Z range over all ground terms (attribute sets).[4]
From these rules, we can derive these secondary rules:[3]
- Union: If X → Y and X → Z, then X → YZ
- Decomposition: If X → YZ, then X → Y and X → Z
- Pseudotransitivity: If X → Y and WY → Z, then WX → Z
The union and decomposition rules can be combined in a logical equivalence stating that X → YZ, holds iff X → Y and X → Z. This is sometimes called the splitting/combining rule.[6]
Another rule that is sometimes handy is:[7]
- Composition: If X → Y and Z → W, then XZ → YW
Equivalent sets of functional dependencies are called covers of each other. Every set of functional dependencies has a canonical cover.
Applications to normalization
Heath's theorem
An important property (yielding an immediate application) of functional dependencies is that if R is a relation with columns named from some set of attributes U and R satisfies some functional dependency X → Y then  where Z = U − XY. Intuitively, if a functional dependency X → Y holds in R, then the relation can be safely split in two relations alongside the column X (which is a key for
where Z = U − XY. Intuitively, if a functional dependency X → Y holds in R, then the relation can be safely split in two relations alongside the column X (which is a key for  ) ensuring that when the two parts are joined back no data is lost, i.e. a functional dependency provides a simple way to construct a lossless-join decomposition of R in two smaller relations. This fact is sometimes called Heath’s theorem; it is one of the early results in database theory.[8]
) ensuring that when the two parts are joined back no data is lost, i.e. a functional dependency provides a simple way to construct a lossless-join decomposition of R in two smaller relations. This fact is sometimes called Heath’s theorem; it is one of the early results in database theory.[8]
Heath’s theorem effectively says we can pull out the values of Y from the big relation R and store them into one, 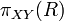 , which has no value repetitions in the row for X and is effectively a lookup table for Y keyed by X and consequently has only one place to update the Y corresponding to each X unlike the "big" relation R where there are potentially many copies of each X, each one with its copy of Y which need to be kept synchronized on updates. (This elimination of redundancy is an advantage in OLTP contexts, where many changes are expected, but not so much in OLAP contexts, which involve mostly queries.) Heath’s decomposition leaves only X to act as a foreign key in the remainder of the big table
, which has no value repetitions in the row for X and is effectively a lookup table for Y keyed by X and consequently has only one place to update the Y corresponding to each X unlike the "big" relation R where there are potentially many copies of each X, each one with its copy of Y which need to be kept synchronized on updates. (This elimination of redundancy is an advantage in OLTP contexts, where many changes are expected, but not so much in OLAP contexts, which involve mostly queries.) Heath’s decomposition leaves only X to act as a foreign key in the remainder of the big table 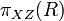 .
.
Functional dependencies however should not be confused with inclusion dependencies, which are the formalism for foreign keys; even though they are used for normalization, functional dependencies express constraints over one relation (schema), whereas inclusion dependencies express constraints between relation schemas in a database schema.Furthermore, the two notions do not even intersect in the classification of dependencies: functional dependencies are equality-generating dependencies whereas inclusion dependencies are tuple-generating dependencies. Enforcing referential constraints after relation schema decomposition (normalization) requires a new formalism, i.e. inclusion dependencies. In the decomposition resulting from Heath's theorem, there's nothing preventing the insertion of tuples in having some value of X not found in .
Normal forms
Normal forms are database normalization levels which determine the "goodness" of a table. Generally, the third normal form is considered to be a "good" standard for a relational database.[citation needed]
Normalization aims to free the database from update, insertion and deletion anomalies. It also ensures that when a new value is introduced into the relation, it has minimal effect on the database, and thus minimal effect on the applications using the database.[citation needed]
Irreducible function depending set
A functional depending set S is irreducible if the set has the following three properties:
- Each right set of a functional dependency of S contains only one attribute.
- Each left set of a functional dependency of S is irreducible. It means that reducing any one attribute from left set will change the content of S (S will lose some information).
- Reducing any functional dependency will change the content of S.
Sets of Functional Dependencies(FD) with these properties are also called canonical or minimal.
See also
- Chase (algorithm)
- Inclusion dependency
- Join dependency
- Multivalued dependency (MVD)
- Database normalization
- First normal form
References
- ↑ Terry Halpin (2008). Information Modeling and Relational Databases (2nd ed.). Morgan Kaufmann. p. 140. ISBN 978-0-12-373568-3.
- ↑ Chris Date (2012). Database Design and Relational Theory: Normal Forms and All That Jazz. O'Reilly Media, Inc. p. 21. ISBN 978-1-4493-2801-6.
- ↑ 3.0 3.1 Abraham Silberschatz; Henry Korth; S. Sudarshan (2010). Database System Concepts (6th ed.). McGraw-Hill. p. 339. ISBN 978-0-07-352332-3.
- ↑ 4.0 4.1 M. Y. Vardi. Fundamentals of dependency theory. In E. Borger, editor, Trends in Theoretical Computer Science, pages 171–224. Computer Science Press, Rockville, MD, 1987. ISBN 0881750840
- ↑ Abiteboul, Serge; Hull, Richard B.; Vianu, Victor (1995), Foundations of Databases, Addison-Wesley, pp. 164–168, ISBN 0-201-53771-0
- ↑ Hector Garcia-Molina; Jeffrey D. Ullman; Jennifer Widom (2009). Database systems: the complete book (2nd ed.). Pearson Prentice Hall. p. 73. ISBN 978-0-13-187325-4.
- ↑ S. K. Singh (2009) [2006]. Database Systems: Concepts, Design & Applications. Pearson Education India. p. 323. ISBN 978-81-7758-567-4.
- ↑ Heath, I. J. (1971). "Unacceptable file operations in a relational data base". Proceedings of the 1971 ACM SIGFIDET (now SIGMOD) Workshop on Data Description, Access and Control - SIGFIDET '71. pp. 19–33. doi:10.1145/1734714.1734717. cited in:
- Ronald Fagin and Moshe Y. Vardi (1986). "The Theory of Data Dependencies - A Survey". In Michael Anshel and William Gewirtz. Mathematics of Information Processing: [short Course Held in Louisville, Kentucky, January 23-24, 1984]. American Mathematical Soc. p. 23. ISBN 978-0-8218-0086-7.
- C. Date (2005). Database in Depth: Relational Theory for Practitioners. O'Reilly Media, Inc. p. 142. ISBN 978-0-596-10012-4.
External links
- Gary Burt (summer, 1999). "CS 461 (Database Management Systems) lecture notes". University of Maryland Baltimore County Department of Computer Science and Electrical Engineering.
- Jeffrey D. Ullman. "CS345 Lecture Notes" (PostScript). Stanford University.
- Osmar Zaiane (June 9, 1998). "Chapter 6: Integrity constraints". CMPT 354 (Database Systems I) lecture notes. Simon Fraser University Department of Computing Science.