F-distribution
Probability density function | |
Cumulative distribution function | |
| Parameters | d1, d2 > 0 deg. of freedom |
|---|---|
| Support | x ∈ [0, +∞) |
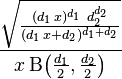 | |
| CDF |  |
| Mean |  for d2 > 2 |
| Mode | 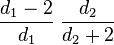 for d1 > 2 |
| Variance |  for d2 > 4 |
| Skewness | 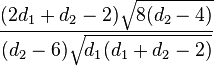 for d2 > 6 |
| Ex. kurtosis | see text |
| MGF | does not exist, raw moments defined in text and in [1][2] |
| CF | see text |
In probability theory and statistics, the F-distribution is a continuous probability distribution.[1][2][3][4] It is also known as Snedecor's F distribution or the Fisher-Snedecor distribution (after R.A. Fisher and George W. Snedecor). The F-distribution arises frequently as the null distribution of a test statistic, most notably in the analysis of variance; see F-test.
Definition
If a random variable X has an F-distribution with parameters d1 and d2, we write X ~ F(d1, d2). Then the probability density function for X is given by
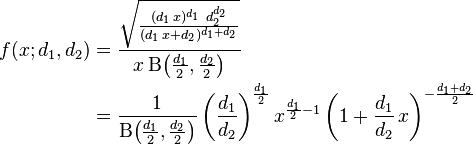
for real x ≥ 0. Here  is the beta function. In many applications, the parameters d1 and d2 are positive integers, but the distribution is well-defined for positive real values of these parameters.
is the beta function. In many applications, the parameters d1 and d2 are positive integers, but the distribution is well-defined for positive real values of these parameters.
The cumulative distribution function is
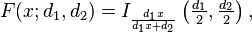
where I is the regularized incomplete beta function.
The expectation, variance, and other details about the F(d1, d2) are given in the sidebox; for d2 > 8, the excess kurtosis is
 .
.
The k-th moment of an F(d1, d2) distribution exists and is finite only when 2k < d2 and it is equal to [5]
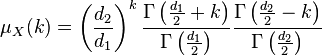
The F-distribution is a particular parametrization of the beta prime distribution, which is also called the beta distribution of the second kind.
The characteristic function is listed incorrectly in many standard references (e.g., [2]). The correct expression [6] is

where U(a, b, z) is the confluent hypergeometric function of the second kind.
Characterization
A random variate of the F-distribution with parameters d1 and d2 arises as the ratio of two appropriately scaled chi-squared variates:[7]

where
- U1 and U2 have chi-squared distributions with d1 and d2 degrees of freedom respectively, and
- U1 and U2 are independent.
In instances where the F-distribution is used, for example in the analysis of variance, independence of U1 and U2 might be demonstrated by applying Cochran's theorem.
Equivalently, the random variable of the F-distribution may also be written

where s12 and s22 are the sums of squares S12 and S22 from two normal processes with variances σ12 and σ22 divided by the corresponding number of χ2 degrees of freedom, d1 and d2 respectively.(see discussion)
In a Frequentist context, a scaled F-distribution therefore gives the probability p(s12/s22 | σ12, σ22), with the F distribution itself, without any scaling, applying where σ12 is being taken equal to σ22. This is the context in which the F-distribution most generally appears in F-tests: where the null hypothesis is that two independent normal variances are equal, and the observed sums of some appropriately selected squares are then examined to see whether their ratio is significantly incompatible with this null hypothesis.
The quantity X has the same distribution in Bayesian statistics, if an uninformative rescaling-invariant Jeffreys prior is taken for the prior probabilities of σ12 and σ22.[8] In this context, a scaled F-distribution thus gives the posterior probability p(σ22/σ12|s12, s22), where now the observed sums s12 and s22 are what are taken as known.
Generalization
A generalization of the (central) F-distribution is the noncentral F-distribution.
Related distributions and properties
- If
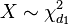 and
and  are independent, then
are independent, then 
- If
 (Beta distribution) then
(Beta distribution) then 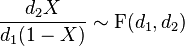
- Equivalently, if X ~ F(d1, d2), then
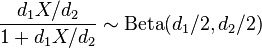 .
. - If X ~ F(d1, d2) then
 has the chi-squared distribution
has the chi-squared distribution 
- F(d1, d2) is equivalent to the scaled Hotelling's T-squared distribution
 .
. - If X ~ F(d1, d2) then X−1 ~ F(d2, d1).
- If X ~ t(n) then
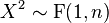
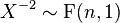
- F-distribution is a special case of type 6 Pearson distribution
- If X and Y are independent, with X, Y ~ Laplace(μ, b) then

- If X ~ F(n, m) then
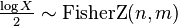 (Fisher's z-distribution)
(Fisher's z-distribution) - The noncentral F-distribution simplifies to the F-distribution if λ = 0.
- The doubly noncentral F-distribution simplifies to the F-distribution if

- If
 is the quantile p for X ~ F(d1, d2) and
is the quantile p for X ~ F(d1, d2) and  is the quantile 1−p for Y ~ F(d2, d1), then
is the quantile 1−p for Y ~ F(d2, d1), then
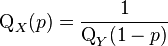 .
.
See also
References
- ↑ 1.0 1.1 Johnson, Norman Lloyd; Samuel Kotz, N. Balakrishnan (1995). Continuous Univariate Distributions, Volume 2 (Second Edition, Section 27). Wiley. ISBN 0-471-58494-0.
- ↑ 2.0 2.1 2.2 Abramowitz, Milton; Stegun, Irene A., eds. (1965), "Chapter 26", Handbook of Mathematical Functions with Formulas, Graphs, and Mathematical Tables, New York: Dover, p. 946, ISBN 978-0486612720, MR 0167642.
- ↑ NIST (2006). Engineering Statistics Handbook - F Distribution
- ↑ Mood, Alexander; Franklin A. Graybill, Duane C. Boes (1974). Introduction to the Theory of Statistics (Third Edition, p. 246-249). McGraw-Hill. ISBN 0-07-042864-6.
- ↑ Taboga, Marco. "The F distribution".
- ↑ Phillips, P. C. B. (1982) "The true characteristic function of the F distribution," Biometrika, 69: 261-264 JSTOR 2335882
- ↑ M.H. DeGroot (1986), Probability and Statistics (2nd Ed), Addison-Wesley. ISBN 0-201-11366-X, p. 500
- ↑ G.E.P. Box and G.C. Tiao (1973), Bayesian Inference in Statistical Analysis, Addison-Wesley. p.110
External links
- Table of critical values of the F-distribution
- Earliest Uses of Some of the Words of Mathematics: entry on F-distribution contains a brief history
- Free calculator for F-testing
| |||||||||||