Extended precision
| Floating-point precisions |
|---|
| IEEE 754 |
| Other |
Extended precision refers to floating point number formats that provide greater precision and more exponent range than the basic floating point formats.[1] Extended precision formats support a basic format by minimizing roundoff and overflow errors in intermediate values of expressions on the base format. In contrast to extended precision, arbitrary-precision arithmetic refers to implementations of much larger numeric types (with a storage count that usually is not a power of two) using special software (or, rarely, hardware).
Extended precision implementations
IBM extended precision formats
The IBM 1130 offered two floating point formats: a 32-bit "standard precision" format and a 40-bit "extended precision" format. Standard precision format contained a 24-bit two's complement significand while extended precision utilized a 32-bit two's complement significand. The latter format could make full use of the cpu's 32-bit integer operations. The characteristic in both formats was an 8-bit field containing the power of two biased by 128. Floating-point arithmetic operations were performed by software, and double precision was not supported at all. The extended format occupied three 16-bit words, with the extra space simply ignored.[2]
The IBM System/360 supports a 32-bit "short" floating point format and a 64-bit "long" floating point format.[3] The 360/85 and follow-on System/370 added support for a 128-bit "extended" format.[4] These formats are still supported in the current design, where they are now called the "hexadecimal floating point" (HFP) formats.
IEEE 754 extended precision formats
The IEEE 754 floating point standard recommends that implementations provide extended precision formats. The standard specifies the minimum requirements for an extended format but does not specify an encoding.[5] The encoding is the implementor's choice.[6]
The x86 and x86-64 and Itanium processors support an 80-bit "double extended" extended precision format with a 64-bit significand. The Intel 8087 math coprocessor was the first x86 device which supported floating point arithmetic in hardware. It was designed to support a 32-bit "single precision" format and a 64-bit "double precision" format for encoding and interchanging floating point numbers. The double extended format was designed not to store data at higher precision as such, but rather primarily to allow for the computation of double results more reliably and accurately by minimising overflow and roundoff-errors in intermediate calculations:[7][8][9] for example, many floating point algorithms (e.g. exponentiation) suffer from significant precision loss when computed using the most direct implementations. To mitigate such issues the internal registers in the 8087 were designed to hold intermediate results in an 80-bit "extended precision" format. The 8087 would automatically convert numbers to this format when loading floating point registers from memory and would also convert results back to the more conventional formats when storing the registers back into memory. To enable intermediate subexpressions results to be saved in extended precision scratch variables and continued across programming language statements, and otherwise interrupted calculations to resume where they were interrupted, it was necessary to provide instructions which would transfer values between these internal registers and memory without performing any conversion, which therefore enabled access to the extended format for calculations[10]- also reviving the issue of the accuracy of functions of such numbers, but at a higher precision.
The Floating Point Unit on all subsequent x86 processors have supported this format. As a result software can be developed which takes advantage of the higher precision provided by this format. Prof. W. Kahan, a primary designer of the x87 arithmetic and initial IEEE 754 standard proposal notes on the development of the x87 floating point- "An Extended format as wide as we dared (80 bits) was included to serve the same support role as the 13-decimal internal format serves in Hewlett-Packard’s 10- decimal calculators".[11] Moreover, Kahan notes that 64 bits was the widest significand across which carry propagation could be done without increasing the cycle time on the 8087,[12] and that the x87 extended precision was designed to be extensible to higher precision in future processors: "For now the 10-byte Extended format is a tolerable compromise between the value of extra-precise arithmetic and the price of implementing it to run fast; very soon two more bytes of precision will become tolerable, and ultimately a 16-byte format... That kind of gradual evolution towards wider precision was already in view when IEEE Standard 754 for Floating-Point Arithmetic was framed.".[13]
The Motorola 6888x math coprocessors and the Motorola 68040 and 68060 processors support this same 64-bit significand extended precision type (similar to the Intel format although padded to a 96-bit format with 16 unused bits inserted between the exponent and significand fields[14]). The follow-on Coldfire processors do not support this 96-bit extended precision format.[15]
The x86 and Motorola 68881 80-bit formats meet the requirements of the IEEE 754 double extended format,[16] as does the IEEE 754 128-bit format.
x86 Extended Precision Format
The x86 Extended Precision Format is an 80-bit format first implemented in the Intel 8087 math coprocessor and is supported by all processors that are based on the x86 design which incorporate a floating point unit. This 80-bit format uses one bit for the sign of the significand, 15 bits for the exponent field (i.e. the same range as the 128-bit quadruple precision IEEE 754 format) and 64 bits for the significand. The exponent field is biased by 16383, meaning that 16383 has to be subtracted from the value in the exponent field to compute the actual power of 2.[17] An exponent field value of 32767 (all fifteen bits 1) is reserved so as to enable the representation of special states such as infinity and Not a Number. If the exponent field is zero, the value is a denormal number and the exponent of 2 is -16382.[18]

In the following table, "s" is the value of the sign bit (0 means positive, 1 means negative), "e" is the value of the exponent field interpreted as a positive integer, and "m" is the significand interpreted as a positive binary number where the binary point is located between bits 63 and 62. The "m" field is the combination of the integer and fraction parts in the above diagram.
| Exponent | Significand | Meaning | |
|---|---|---|---|
| All Zeros | Bit 63 | Bits 62-0 | |
| Zero | Zero | Zero. The sign bit gives the sign of the zero. | |
| Non-zero | Denormal. The value is (-1)s × <var>m</var> × 2-16382 | ||
| One | Anything | Pseudo Denormal. The 80387 and later properly interpret this value but will not generate it.
The value is (-1)s × <var>m</var> × 2-16382 | |
| All Ones | Bits 63,62 | Bits 61-0 | |
| 00 | Zero | Pseudo-Infinity. The sign bit gives the sign of the infinity. The 8087 and 80287 treat this as Infinity. The 80387 and later treat this as an invalid operand. | |
| Non-zero | Pseudo Not a Number. The sign bit is meaningless. The 8087 and 80287 treat this as a Signaling Not a Number. The 80387 and later treat this as an invalid operand. | ||
| 01 | Anything | Pseudo Not a Number. The sign bit is meaningless. The 8087 and 80287 treat this as a Signaling Not a Number. The 80387 and later treat this as an invalid operand. | |
| 10 | Zero | Infinity. The sign bit gives the sign of the infinity. The 8087 and 80287 treat this as a Signaling Not a Number. The 8087 and 80287 coprocessors used the pseudo-infinity representation for infinities. | |
| Non-zero | Signalling Not a Number, the sign bit is meaningless. | ||
| 11 | Zero | Floating-point Indefinite, the result of invalid calculations such as square root of a negative number, logarithm of a negative number, 0/0, infinity / infinity, infinity times 0, and others when the processor has been configured to not generate exceptions for invalid operands. The sign bit is meaningless. This is a special case of a Quiet Not a Number. | |
| Non-zero | Quiet Not a Number, the sign bit is meaningless. The 8087 and 80287 treat this as a Signaling Not a Number. | ||
| All other values | Bit 63 | Bits 62-0 | |
| Zero | Anything | Unnormal. Only generated on the 8087 and 80287. The 80387 and later treat this as an invalid operand.
The value is (-1)s × <var>m</var> × 2<var>e</var>-16383 | |
| One | Anything | Normalized value.
The value is (-1)s × <var>m</var> × 2<var>e</var>-16383 | |
In contrast to the single and double-precision formats, this format does not utilize an implicit/hidden bit. Rather, bit 63 contains the integer part of the significand and bits 62-0 hold the fractional part. Bit 63 will be 1 on all normalized numbers. There were several advantages to this design when the 8087 was being developed:
- Calculations can be completed a little faster if all bits of the significand are present in the register.
- A 64-bit significand provides sufficient precision to avoid loss of precision when the results are converted back to double precision format in the vast number of cases.
- This format provides a mechanism for indicating precision loss due to underflow which can be carried through further operations. For example, the calculation 2×10-4930 × 3×10-10 × 4×1020 generates the intermediate result 6×10-4940 which is a denormal and also involves precision loss. The product of all of the terms is 24×10-4920 which can be represented as a normalized number. The 80287 could complete this calculation and indicate the loss of precision by returning an "unnormal" result (exponent not 0, bit 63 = 0).[19][20] Processors since the 80387 no longer generate unnormals and do not support unnormal inputs to operations. They will generate a denormal if an underflow occurs but will generate a normalized result if subsequent operations on the denormal can be normalized.[21]
Introduction to use
The 80-bit floating point format was widely available by 1984,[22] after the development of C, Fortran and similar computer languages, which initially offered only the common 32- and 64-bit floating point sizes. On the x86 design most C compilers now support 80-bit extended precision via the long double type, and this was specified in the C99 / C11 standards (IEC 60559 floating-point arithmetic (Annex F)). Compilers on x86 for other languages often support extended precision as well, sometimes via nonstandard extensions: for example, Turbo Pascal offers an extended type, and several Fortran compilers have a REAL*10 type (analogous to REAL*4 and REAL*8). Such compilers also typically include extended-precision mathematical subroutines, such as square root and trigonometric functions, in their standard libraries.
Working range
The 80-bit floating point format has a range (including subnormals) from approximately 3.65×10−4951 to 1.18×104932. Although log10(264) ≅ 19.266, this format is usually described as giving approximately eighteen significant digits of precision. The use of decimal when talking about binary is unfortunate because most decimal fractions are recurring sequences in binary just as 2/3 is in decimal. Thus, a value such as 10.15 is represented in binary as equivalent to 10·1499996185 etc. in decimal for REAL*4 but 10·15000000000000035527etc. in REAL*8: interconversion will involve approximation except for those few decimal fractions that represent an exact binary value, such as 0.625. For REAL*10, the decimal string is 10.1499999999999999996530553etc. The last 9 digit is the eighteenth fractional digit and thus the twentieth significant digit of the string. Bounds on conversion between decimal and binary for the 80-bit format can be given as follows: if a decimal string with at most 18 significant digits is correctly rounded to an 80-bit IEEE 754 binary floating point value (as on input) then converted back to the same number of significant decimal digits (as for output), then the final string will exactly match the original; while, conversely, if an 80-bit IEEE 754 binary floating point value is correctly converted and (nearest) rounded to a decimal string with at least 21 significant decimal digits then converted back to binary format it will exactly match the original. [16] These approximations are particularly troublesome when specifying the best value for constants in formulae to high precision, as might be calculated via arbitrary precision arithmetic.
Need for the 80-bit format
A notable example of the need for a minimum of 64 bits of precision in the significand of the extended precision format is the need to avoid precision loss when performing exponentiation on double precision values.[23][24][25][26] The x86 floating point units do not provide an instruction that directly performs exponentiation. Instead they provide a set of instructions that a program can use in sequence to perform exponentiation using the equation:
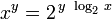
In order to avoid precision loss, the intermediate results "log2 <var>x</var>" and "y log2 <var>x</var>" must be computed with much higher precision because effectively both the exponent and the significand fields of <var>x</var> must fit into the significand field of the intermediate result. Subsequently the significand field of the intermediate result is split between the exponent and significand fields of the final result when 2intermediate result is calculated. The following discussion describes this requirement in more detail.
An IEEE 754 double precision value can be represented as:

where s is the sign of the exponent (either 0 or 1), E is the unbiased exponent which is an integer that ranges from 0 to 1023, and M is the significand which is a 53-bit value that falls in the range 1 ≤ M < 2. Negative numbers and zero can be ignored because the logarithm of these values is undefined. For purposes of this discussion M does not have 53 bits of precision because it is constrained to be greater than or equal to one i.e. the hidden bit does not count towards the precision (Note that in situations where M is less than 1, the value is actually a denormal and therefore may have already suffered precision loss. This situation is beyond the scope of this article).
Taking the log of this representation of a double precision number and simplifying results in the following:
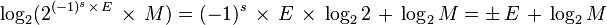
This result demonstrates that when taking base-2 logarithm of a number, the sign of the exponent of the original value becomes the sign of the logarithm, the exponent of the original value becomes the integer part of the significand of the logarithm, and the significand of the original value is transformed into the fractional part of the significand of the logarithm.
Because E is an integer in the range 0 to 1023, up to 10 bits to the left of the radix point are needed to represent the integer part of the logarithm. Because M falls in the range 1 ≤ M < 2, the value of log2 M will fall in the range 0 ≤ log2 M < 1 so at least 52 bits are needed to the right of the radix point to represent the fractional part of the logarithm. Combining 10 bits to the left of the radix point with 52 bits to the right of the radix point means that the significand part of the logarithm must be computed to at least 62 bits of precision. In practice values of M less than  require 53 bits to the right of the radix point and values of M less than
require 53 bits to the right of the radix point and values of M less than ![{\sqrt[ {4}]{2}}](/2014-wikipedia_en_all_02_2014/I/media/b/b/e/d/bbed5c0cb24e50ec62fc424f7b80f157.png) require 54 bits to the right of the radix point to avoid precision loss. Balancing this requirement for added precision to the right of the radix point, exponents less than 512 only require 9 bits to the left of the radix point and exponents less than 256 require only 8 bits to the left of the radix point.
require 54 bits to the right of the radix point to avoid precision loss. Balancing this requirement for added precision to the right of the radix point, exponents less than 512 only require 9 bits to the left of the radix point and exponents less than 256 require only 8 bits to the left of the radix point.
The final part of the exponentiation calculation is computing 2intermediate result. The "intermediate result" consists of an integer part "I" added to a fractional part "F". If the intermediate result is negative then a slight adjustment is needed to get a positive fractional part because both "I" and "F" are negative numbers.
For positive intermediate results:
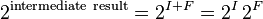
For negative intermediate results:
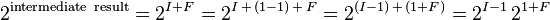
Thus the integer part of the intermediate result ("I" or "I-1") plus a bias becomes the exponent of the final result and transformed positive fractional part of the intermediate result: 2F or 21+F becomes the significand of the final result. In order to supply 52 bits of precision to the final result, the positive fractional part must be maintained to at least 52 bits.
In summary, the exact number of bits of precision needed in the significand of the intermediate result is somewhat data dependent but 64 bits is sufficient to avoid precision loss in the vast majority of exponentiation computations involving double precision numbers.
The number of bits needed for the exponent of the extended precision format follows from the requirement that the product of two double precision numbers should not overflow when computed using the extended format. The largest possible exponent of a double precision value is 1023 so the exponent of the largest possible product of two double precision numbers is 2047 (an 11-bit value). Adding in a bias to account for negative exponents means that the exponent field must be at least 12 bits wide.
Combining these requirements: 1 bit for the sign, 12 bits for the biased exponent, and 64 bits for the significand means that the extended precision format would need at least 77 bits. Engineering considerations resulted in the final definition of the 80-bit format (in particular the IEEE 754 standard requires the exponent range of an extended precision format to match that of the next largest, quad, precision format which is 15 bits).[24]
See also
- IBM Floating Point Architecture
- IEEE 754
References
- ↑ IEEE 754 (2008, ¶ 2.1.21) defines extended precision format as "A format that extends a supported basic format by providing wider precision and range."
- ↑ IBM 1130 Subroutine Library 9th ed. IBM Corporation. 1974. p. 93.
- ↑ IBM System/360 Principles of Operation (9th ed.). IBM Corporation. 1970., p 41
- ↑ IBM System/370 Principles of Operation (7th ed.). IBM Corporation. 1980., pp 9-2 thru 9-3
- ↑ IEEE Computer Society (August 29, 2008), IEEE Standard for Floating-Point Arithmetic, IEEE, doi:10.1109/IEEESTD.2008.4610935, IEEE Std 754-2008, § 3.7
- ↑ Kevin Brewer. "Kevin’s Report". IEEE-754 Reference Material. Retrieved 2012-02-19.
- ↑ x87 designer Kahan notes: "This format is intended mainly to help programmers enhance the integrity of their Single and Double software, and to attenuate degradation by roundoff in Double matrix computations of larger dimensions, and can easily be used in such a way that substituting Quadruple for Extended need never invalidate its use." William Kahan (1 October 1997). "Lecture Notes on the Status of IEEE Standard 754 for Binary Floating-Point Arithmetic". p. 5.
- ↑ Bo Einarsson (2005). Accuracy and reliability in scientific computing. SIAM. pp. 9–. ISBN 978-0-89871-815-7. Retrieved 3 May 2013.
- ↑ Intel corp. (March 2012). "Intel® 64 and IA-32 Architectures Software Developer’s Manual. Vol. 1 sec. 8.2".
- ↑ "High-level languages will use extended (invisibly) to evaluate intermediate subexpressions, and later may provide extended as a declarable data type." (page 70) Jerome T. Coonen (January 1980). "An Implementation Guide to a Proposed Standard for Floating-Point Arithmetic". IEEE Computer: 68–79.
- ↑ William Kahan (22 November 1983). "Mathematics Written in Sand - the hp-15C, Intel 8087, etc.".
- ↑ David Goldberg (March 1991). "What every computer scientist should know about floating-point arithmetic. ACM Computing Surveys, volume 23, issue 1". p. 192.
- ↑ Higham, Nicholas (2002). "Designing stable algorithms" in Accuracy and Stability of Numerical Algorithms (2 ed). SIAM. p. 43.
- ↑ Motorola MC68000 Family Programmer's Reference Manual. Freescale Semiconductor. 1992. pp. 1–16.
- ↑ ColdFire Family Programmer’s Reference Manual. Freescale semiconductor. 2005. pp. 7–7.
- ↑ 16.0 16.1 William Kahan (1 October 1997). "Lecture Notes on the Status of IEEE Standard 754 for Binary Floating-Point Arithmetic".
- ↑ Intel 80C187 datasheet
- ↑ Intel® 64 and IA-32 Architectures Developer's Manual: Vol. 1. Intel Corporation. pp. 4–6 thru 4–9 and 4–18 thru 4–21.
- ↑ Palmer, John F.; Morse, Stephen P. (1984). The 8087 Primer. Wiley Press. p. 14. ISBN 0-471-87569-4.
- ↑ Morse, Stephen P.; Albert, Douglas J. (1986). The 80286 Architecture. Wiley Press. pp. 91–111. ISBN 0-471-83185-9.
- ↑ Intel® 64 and IA-32 Architectures Developer's Manual: Vol. 1. Intel Corporation. pp. 8–21 thru 8–22.
- ↑ Charles Severance (20 February 1998). "An Interview with the Old Man of Floating-Point".
- ↑ Palmer, John F.; Morse, Stephen P. (1984). The 8087 Primer. Wiley Press. p. 16. ISBN 0-471-87569-4.
- ↑ 24.0 24.1 Morse, Stephen P.; Albert, Douglas J. (1986). The 80286 Architecture. Wiley Press. pp. 96–98. ISBN 0-471-83185-9.
- ↑ Hough, David (March 1981). "Applications of the proposed IEEE 754 standard for floating point arithmetic". IEEE Computer 14 (3): 70–74. doi:10.1109/C-M.1981.220381.
- ↑ "The presence of at least as many extra bits of precision in extended as in the exponent field of the basic format it supports greatly simplifies the accurate computation of the transcendental functions, inner products, and the power function yx." (page 70) Jerome T. Coonen (January 1980). "An Implementation Guide to a Proposed Standard for Floating-Point Arithmetic". IEEE Computer: 68–79.