Exact test
In statistics, an exact (significance) test is a test where all assumptions upon which the derivation of the distribution of the test statistic is based are met, as opposed to an approximate test, in which the approximation may be made as close as desired by making the sample size big enough. This will result in a significance test that will have a false rejection rate always equal to the significance level of the test. For example an exact test at significance level 5% will in the long run reject true null hypotheses exactly 5% of the time.
Parametric tests, such as those described in exact statistics, are exact tests when the parametric assumptions are fully met, but in practice the use of the term exact (significance) test is reserved for those tests that do not rest on parametric assumptions – non-parametric tests. However, in practice most implementations of non-parametric test software use asymptotical algorithms for obtaining the significance value, which makes the implementation of the test non-exact.
So when the result of a statistical analysis is said to be an “exact test” or an “exact p-value”, it ought to imply that the test is defined without parametric assumptions and evaluated without using approximate algorithms. In principle however it could also mean that a parametric test has been employed in a situation where all parametric assumptions are fully met, but it is in most cases impossible to prove this completely in a real world situation. Exceptions when it is certain that parametric tests are exact include tests based on the binomial or Poisson distributions. Sometimes permutation test is used as a synonym for exact test, but although all permutation tests are exact tests, not all exact tests are permutation tests.
Definition
The basic equation underlying permutation tests is
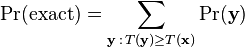
where:
- x is the outcome actually observed,
- Pr(y) is the probability under the null hypothesis of a potentially observed outcome y,
- T(y) is the value of the test statistic for an outcome y, with larger values of T representing cases which notionally represent greater departures from the null hypothesis,
and where the sum ranges over all outcomes y (including the observed one) that have the same value of the test statistic obtained for the observed sample x, or a larger one .
Example: Pearson's chi-squared test versus an exact test
A simple example of the occasion for this concept may be seen by observing that Pearson's chi-squared test is an approximate test. Suppose Pearson's chi-squared test is used to ascertain whether a six-sided die is "fair", i.e. gives each of the six outcomes equally often. If the die is thrown n times, then one "expects" to see each outcome n/6 times. The test statistic is
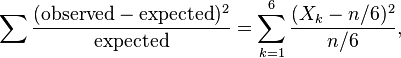
where Xk is the number of times outcome k is observed. If the null hypothesis of "fairness" is true, then the probability distribution of the test statistic can be made as close as desired to the chi-squared distribution with 5 degrees of freedom by making the sample size n big enough. But if n is small, then the probabilities based on chi-squared distributions may not be very close approximations. Finding the exact probability that this test statistic exceeds a certain value then requires combinatorial enumeration of all outcomes of the experiment that result in such a large value of the test statistic. Moreover, it becomes questionable whether the same test statistic ought to be used. A likelihood-ratio test might be preferred as being more powerful, and the test statistic might not be a monotone function of the one above.
Example: Fisher's exact test
Fisher's exact test is exact because the sampling distribution (conditional on the marginals) is known exactly. Compare Pearson's chi-squared test, which (although it tests the same null) is not exact because the distribution of the test statistic is correct only asymptotically.
See also
References
- Fisher, R. A. (1954) Statistical Methods for research workers. Oliver and Boyd.
- Mehta, C. R.; Patel, N. R. (1997) "Exact inference in categorical data", unpublished preprint.
- Mehta, C.R. ; Patel, N.R. (1998). "Exact Inference for Categorical Data". In P. Armitage and T. Colton, eds., Encyclopedia of Biostatistics, Chichester: John Wiley, pp. 1411–1422.
- Corcoran, C. D.; Senchaudhuri, P.; Mehta, C. R.; Patel, N. R. (2005). "Exact Inference for Categorical Data". Encyclopedia of Biostatistics. doi:10.1002/0470011815.b2a10019. ISBN 047084907X.