Energy distance
Energy distance is a statistical distance between probability distributions. If X and Y are independent random vectors in Rd with cumulative distribution functions F and G respectively, then the energy distance between the distributions F and G is defined to be

where X, X' are independent and identically distributed (iid), Y, Y' are iid,  is expected value, and || . || denotes the length of a vector. Energy distance characterizes the equality of distributions: D(F,G) = 0 if and only if X and Y are identically distributed.
is expected value, and || . || denotes the length of a vector. Energy distance characterizes the equality of distributions: D(F,G) = 0 if and only if X and Y are identically distributed.
Energy distance for statistical applications was introduced in 1985 by Gábor J. Székely, who proved that for real-valued random variables this distance is exactly twice Harald Cramér's distance:[1]
-
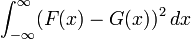 .
.
For a simple proof of this equivalence, see Székely and Rizzo (2005).[2] In higher dimensions, however, the two distances are different because the energy distance is rotation invariant while Cramér's distance is not. (Notice that Cramér's distance is not the same as the distribution-free Cramer-von-Mises criterion.)
Generalization to metric spaces
One can generalize the notion of energy distance to probability distributions on metric spaces. Let 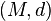 be a metric space with its Borel sigma algebra
be a metric space with its Borel sigma algebra 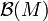 . Let
. Let 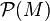 denote the collection of all probability measures on the measurable space
denote the collection of all probability measures on the measurable space  . If μ and ν are probability measures in , then the energy distance of μ and ν can be defined as
. If μ and ν are probability measures in , then the energy distance of μ and ν can be defined as
![D(\mu ,\nu )=2{\mathbb E}[d(X,Y)]-{\mathbb E}[d(X,X')]-{\mathbb E}[d(Y,Y')].](/2014-wikipedia_en_all_02_2014/I/media/c/9/8/d/c98da5201e68d48a64a3b12b72d229b9.png)
This is not necessarily non-negative, however. If 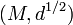 is isometric to a subset of a Hilbert space, then
is isometric to a subset of a Hilbert space, then 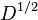 is a pseudometric, and conversely.[3] This condition is expressed by saying that has negative type. Negative type is not sufficient for
is a pseudometric, and conversely.[3] This condition is expressed by saying that has negative type. Negative type is not sufficient for  to be a metric; the latter condition is expressed by saying that has strong negative type. In this situation, the energy distance is zero if and only if X and Y are identically distributed. An example of a metric of negative type but not of strong negative type is the plane with the taxicab metric. All Euclidean spaces and even separable Hilbert spaces have strong negative type.[4]
In the literature on kernel methods for machine learning, these generalized notions of energy distance are studied under the name of maximum mean discrepancy.[5]
to be a metric; the latter condition is expressed by saying that has strong negative type. In this situation, the energy distance is zero if and only if X and Y are identically distributed. An example of a metric of negative type but not of strong negative type is the plane with the taxicab metric. All Euclidean spaces and even separable Hilbert spaces have strong negative type.[4]
In the literature on kernel methods for machine learning, these generalized notions of energy distance are studied under the name of maximum mean discrepancy.[5]
Energy statistics
A related statistical concept, the notion of E-statistic or energy-statistic was introduced by Gábor J. Székely in the 1980s when he was giving colloquium lectures in Budapest, Hungary and at MIT, Yale, and Columbia. This concept is based on the notion of Newton’s potential energy.[6] The idea is to consider statistical observations as heavenly bodies governed by a statistical potential energy which is zero only when an underlying statistical null hypothesis is true. Energy statistics are functions of distances between statistical observations.
Testing for equal distributions
Consider the null hypothesis that two random variables, X and Y, have the same probability distributions: μ = v . For statistical samples from X and Y:
- x1,…,xn and y1,…,ym,
the following arithmetic averages of distances are computed between the X and the Y samples:
- A:= (1/nm)∑|xi – yj|, B:= (1/n2)∑|xi – xj|, C:= (1/m2)∑|yi – yj|.
The E-statistic of the underlying null hypothesis is defined as follows:
- Εn,m(X,Y):= 2A – B – C.
One can prove [2][6] that Εn,m(X,Y) ≥ 0 and that the corresponding population value, E(X,Y):= D(μ,ν), is zero if and only if X and Y have the same distribution (μ=ν). Under this null hypothesis the test statistic

converges in distribution to a quadratic form of independent standard normal random variables. Under the alternative hypothesis T tends to infinity. This makes it possible to construct a consistent statistical test, the energy test for equal distributions.[7]
The E-coefficient of inhomogeneity can also be introduced. This is always between 0 and 1 and is defined as
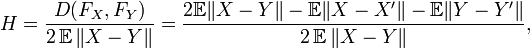
where denotes the expected value. H = 0 exactly when X and Y have the same distribution.
Goodness-of-fit
A multivariate goodness-of-fit measure is defined for distributions in arbitrary dimension (not restricted by sample size). The energy goodness-of-fit statistic is
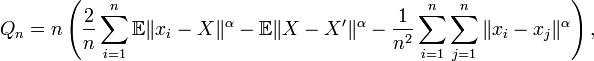
where X and X' are independent and identically distributed according to the hypothesized distribution, and 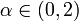 . The only required condition is that X has finite
. The only required condition is that X has finite  moment under the null hypothesis. Under the null hypothesis
moment under the null hypothesis. Under the null hypothesis 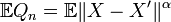 , and the asymptotic distribution of Qn is a quadratic form of centered Gaussian random variables. Under an alternative hypothesis, Qn tends to infinity stochastically, and thus determines a statistically consistent test. For most applications the exponent 1 (Euclidean distance) can be applied. The important special case of testing multivariate normality[2] is implemented in the energy package for R. Tests are also developed for heavy tailed distributions such as Pareto (power law), or stable distributions by application of exponents in (0,1).
, and the asymptotic distribution of Qn is a quadratic form of centered Gaussian random variables. Under an alternative hypothesis, Qn tends to infinity stochastically, and thus determines a statistically consistent test. For most applications the exponent 1 (Euclidean distance) can be applied. The important special case of testing multivariate normality[2] is implemented in the energy package for R. Tests are also developed for heavy tailed distributions such as Pareto (power law), or stable distributions by application of exponents in (0,1).
Applications
Applications include
- Hierarchical clustering (a generalization of Ward's method)[8][9]
- Testing multivariate normality[2]
- Testing the multi-sample hypothesis of equal distributions,[10][11][12]
- Change point detection[13]
- Multivariate independence:
- distance correlation,[14]
- Brownian covariance.[15]
- Scoring rules:
- Gneiting and Raftery[16] apply energy distance to develop a new and very general type of proper scoring rule for probabilistic predictions, the energy score.
Applications of energy statistics are implemented in the open source energy package[17] for R.
References
- ↑ Cramér, H. (1928) On the composition of elementary errors, Skandinavisk Aktuarietidskrift, 11, 141–180.
- ↑ 2.0 2.1 2.2 2.3 Székely, G. J., Rizzo, M. L. (2005). "A new test for multivariate normality". Journal of Multivariate Analysis 93 (1): 58–80. doi:10.1016/j.jmva.2003.12.002. Unknown parameter
|unused_data=ignored (help) Reprint - ↑ Klebanov, L. B. (2005) N-distances and their Applications, Karolinum Press, Charles University, Prague.
- ↑ Lyons, R. (2011) Distance covariance in metric spaces
- ↑ Sejdinovic, D., Gretton, A., Sriperumbudur, B. and Fukumizu, K. (2012) Hypothesis testing using pairwise distances and associated kernels, Proc. of the 29th International Conference on Machine Learning, Edinburgh, Scotland, UK, 2012.
- ↑ 6.0 6.1 Székely, G.J. (2002) E-statistics: The Energy of Statistical Samples, Technical Report BGSU No 02-16.
- ↑ G. J. Szekely and M. L. Rizzo (2004). Testing for Equal Distributions in High Dimension, InterStat, Nov. (5). Reprint.
- ↑ Székely, G. J. and Rizzo, M. L. (2005) Hierarchical Clustering via Joint Between-Within Distances: Extending Ward's Minimum Variance Method, Journal of Classification, 22(2) 151–183
- ↑ Varin, T., Bureau, R., Mueller, C. and Willett, P. (2009). "Clustering files of chemical structures using the Szekely-Rizzo generalization of Ward's method". Journal of Molecular Graphics and Modelling 28 (2): 187–195. doi:10.1016/j.jmgm.2009.06.006. PMID 19640752. Unknown parameter
|unused_data=ignored (help) "eprint". - ↑ M. L. Rizzo and G. J. Székely (2010). DISCO Analysis: A Nonparametric Extension of Analysis of Variance, Annals of Applied Statistics Vol. 4, No. 2, 1034–1055. PDF
- ↑ Szekely, G. J. and Rizzo, M. L. (2004) Testing for Equal Distributions in High Dimension, InterStat, Nov. (5). Reprint.
- ↑ Ledlie, Jonathan and Pietzuch, Peter and Seltzer, Margo, (2006). Stable and Accurate Network Coordinates,. "Proceedings of the 26th IEEE International Conference on Distributed Computing Systems,". Sovetskaia meditsina. ICDCS '06, (IEEE Computer Society,) (3): 74–83,. doi:10.1109/ICDCS.2006.79. ISBN 0-7695-2540-7. PMID 1154085. Unknown parameter
|address=ignored (|location=suggested) (help); Unknown parameter|unused_data=ignored (help) PDF - ↑ Albert Y. Kim, Caren Marzban, Donald B. Percival, Werner Stuetzle (2009). "Using labeled data to evaluate change detectors in a multivariate streaming environment". Signal Processing 89 (12): 2529–2536. doi:10.1016/j.sigpro.2009.04.011. ISSN 0165-1684. Unknown parameter
|unused_data=ignored (help) Preprint:TR534. - ↑ Székely, G. J., Rizzo M. L. and Bakirov, N. K. (2007). "Measuring and testing independence by correlation of distances", The Annals of Statistics, 35, 2769–2794. PDF
- ↑ Székely, G. J. and Rizzo, M. L. (2009). "Brownian distance covariance", The Annals of Applied Statistics, 3/4, 1233–1308. PDF
- ↑ T. Gneiting and A. E. Raftery (2007). "Strictly Proper Scoring Rules, Prediction, and Estimation". Journal of the American Statistical Association 102 (477): 359–378. doi:10.1198/016214506000001437. Unknown parameter
|unused_data=ignored (help) Reprint - ↑ energy: R package version 1.2-0. .