Drift plus penalty
This article describes the drift-plus-penalty method for optimization of queueing networks and other stochastic systems.
Introduction to the drift-plus-penalty method
The drift-plus-penalty method refers to a technique for stabilizing a queueing network while also minimizing the time average of a network penalty function. It can be used to optimize performance objectives such as time average power, throughput, and throughput utility. [1] [2] In the special case when there is no penalty to be minimized, and when the goal is to design a stable routing policy in a multi-hop network, the method reduces to backpressure routing. [3] [4] The drift-plus-penalty method can also be used to minimize the time average of a stochastic process subject to time average constraints on a collection of other stochastic processes. [5] This is done by defining an appropriate set of virtual queues. It can also be used to produce time averaged solutions to convex optimization problems. [6] [7]
Methodology
The drift-plus-penalty method applies to queueing systems that operate in discrete time with time slots t in {0, 1, 2, ...}. First, a non-negative function L(t) is defined as a scalar measure of the state of all queues at time t. The function L(t) is typically defined as the sum of the squares of all queue sizes at time t, and is called a Lyapunov function. The Lyapunov drift is defined:
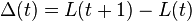
Every slot t, the current queue state is observed and control actions are taken to greedily minimize a bound on the following drift-plus-penalty expression:

where p(t) is the penalty function and V is a non-negative weight. The V parameter can be chosen to ensure the time average of p(t) is arbitrarily close to optimal, with a corresponding tradeoff in average queue size. Like backpressure routing, this method typically does not require knowledge of the probability distributions for job arrivals and network mobility.[5]
Origins and applications
When V=0, the method reduces to greedily minimizing the Lyapunov drift. This results in the backpressure routing algorithm originally developed by Tassiulas and Ephremides (also called the max-weight algorithm).[3] [8] The Vp(t) term was added to the drift expression by Neely [9] and Neely, Modiano, Li [2] for stabilizing a network while also maximizing a throughput utility function. For this, the penalty p(t) was defined as -1 times a reward earned on slot t. This drift-plus-penalty technique was later used to minimize average power[1] and optimize other penalty and reward metrics.[4][5]
The theory was developed primarily for optimizing communication networks, including wireless networks, ad-hoc mobile networks, and other computer networks. However, the mathematical techniques can be applied to optimization and control for other stochastic systems, including renewable energy allocation in smart power grids [10] [11] [12] and inventory control for product assembly systems. [13]
How it works
This section shows how to use the drift-plus-penalty method to minimize the time average of a function p(t) subject to time average constraints on a collection of other functions. The analysis below is based on the material in.[5]
The stochastic optimization problem
Consider a discrete time system that evolves over normalized time slots t in {0, 1, 2, ...}. Define p(t) as a function whose time average should be minimized, called a penalty function. Suppose that minimization of the time average of p(t) must be done subject to time-average constraints on a collection of K other functions:


Every slot t, the network controller observes a new random event. It then makes a control action based on knowledge of this event. The values of p(t) and y_i(t) are determined as functions of the random event and the control action on slot t:

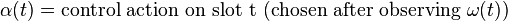


The small case notation p(t), y_i(t) and upper case notation P(), Y_i() is used to distinguish the penalty values from the function that determines these values based on the random event and control action for slot t. The random event  is assumed to take values in some abstract set of events
is assumed to take values in some abstract set of events  . The control action
. The control action  is assumed to be chosen within some abstract set
is assumed to be chosen within some abstract set  that contains the control options. The sets and are arbitrary and can be either finite or infinite. For example, could be a finite list of abstract elements, an uncountably infinite (and possibly non-convex) collection of real-valued vectors, and so on. The functions P(), Y_i() are also arbitrary and do not require continuity or convexity assumptions.
that contains the control options. The sets and are arbitrary and can be either finite or infinite. For example, could be a finite list of abstract elements, an uncountably infinite (and possibly non-convex) collection of real-valued vectors, and so on. The functions P(), Y_i() are also arbitrary and do not require continuity or convexity assumptions.
As an example in the context of communication networks, the random event can be a vector that contains the slot t arrival information for each node and the slot t channel state information for each link. The control action can be a vector that contains the routing and transmission decisions for each node. The functions P() and Y_i() can represent power expenditures or throughputs associated with the control action and channel condition for slot t.
For simplicity of exposition, assume the P() and Y_i() functions are bounded. Further assume the random event process is independent and identically distributed (i.i.d.) over slots t with some possibly unknown probability distribution. The goal is to design a policy for making control actions over time to solve the following problem:
![{\text{Minimize: }}\lim _{{t\rightarrow \infty }}{\frac {1}{t}}\sum _{{\tau =0}}^{{t-1}}E[p(\tau )]](/2014-wikipedia_en_all_02_2014/I/media/b/5/9/b/b59b55440c08f7a67ef4c261702782ab.png)
![{\text{Subject to: }}\lim _{{t\rightarrow \infty }}{\frac {1}{t}}\sum _{{\tau =0}}^{{t-1}}E[y_{i}(\tau )]\leq 0{\text{ }}\forall i\in \{1,...,K\}](/2014-wikipedia_en_all_02_2014/I/media/e/8/2/b/e82bcecc18eec8f83808165c425f924c.png)
It is assumed throughout that this problem is feasible. That is, it is assumed that there exists an algorithm that can satisfy all of the K desired constraints.
The above problem poses each constraint in the standard form of a time average expectation of an abstract process y_i(t) being non-positive. There is no loss of generality with this approach. For example, suppose one desires the time average expectation of some process a(t) to be less than or equal to a given constant c. Then a new penalty function y(t) = a(t) - c can be defined, and the desired constraint is equivalent to the time average expectation of y(t) being non-positive. Likewise, suppose there are two processes a(t) and b(t) and one desires the time average expectation of a(t) to be less than or equal to that of b(t). This constraint is written in standard form by defining a new penalty function y(t) = a(t) - b(t). The above problem seeks to minimize the time average of an abstract penalty function p(t). This can be used to maximize the time average of some desirable reward function r(t) by defining p(t) = -r(t).
Virtual queues
For each constraint i in {1, ..., K}, define a virtual queue with dynamics over slots t in {0, 1, 2, ...} as follows:
![(Eq.1){\text{ }}Q_{i}(t+1)=\max[Q_{i}(t)+y_{i}(t),0]](/2014-wikipedia_en_all_02_2014/I/media/c/2/f/3/c2f35396f17feb9a2f44f80214f69b7f.png)
Initialize Q_i(0)=0 for all i in {1, ..., K}. This update equation is identical to that of a virtual discrete time queue with backlog Q_i(t) and with y_i(t) being the difference between new arrivals and new service opportunities on slot t. Intuitively, stabilizing these virtual queues ensures the time averages of the constraint functions are less than or equal to zero, so the desired constraints are satisfied. To see this precisely, note that (Eq. 1) implies:
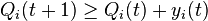
Therefore:

Summing the above over the first t slots and using the law of telescoping sums implies:

Dividing by t and taking expectations implies:
![{\frac {1}{t}}\sum _{{\tau =0}}^{{t-1}}E[y_{i}(\tau )]\leq {\frac {E[Q_{i}(t)]}{t}}](/2014-wikipedia_en_all_02_2014/I/media/f/d/a/f/fdaf65c0090a21925ff9429db797186e.png)
Therefore, the desired constraints of the problem are satisfied whenever the following holds for all i in {1, ..., K}:
![\lim _{{t\rightarrow \infty }}{\frac {E[Q_{i}(t)]}{t}}=0](/2014-wikipedia_en_all_02_2014/I/media/9/3/e/7/93e7bab983a42508d901ff3fda9b9629.png)
A queue Q_i(t) that satisfies the above limit equation is said to be mean rate stable.[5]
The drift-plus-penalty expression
To stabilize the queues, define the Lyapunov function L(t) as a measure of the total queue backlog on slot t:
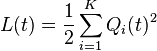
Squaring the queueing equation (Eq. 1) results in the following bound for each queue i in {1, ..., K}:
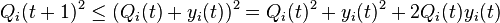
Therefore,

It follows that

Now define B as a positive constant that upper bounds the first term on the right-hand-side of the above inequality. Such a constant exists because the y_i(t) values are bounded. Then:

Adding Vp(t) to both sides results in the following bound on the drift-plus-penalty expression:
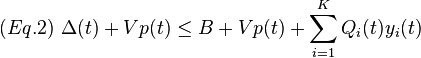
The drift-plus-penalty algorithm (defined below) makes control actions every slot t that greedily minimize the right-hand-side of the above inequality. Intuitively, taking an action that minimizes the drift alone would be beneficial in terms of queue stability but would not minimize time average penalty. Taking an action that minimizes the penalty alone would not necessarily stabilize the queues. Thus, taking an action to minimize the weighted sum incorporates both objectives of queue stability and penalty minimization. The weight V can be tuned to place more or less emphasis on penalty minimization, which results in a performance tradeoff.[5]
Drift-plus-penalty algorithm
Let be the abstract set of all possible control actions. Every slot t, observe the random event and the current queue values:

Given these observations for slot t, greedily choose a control action 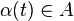 to minimize the following expression (breaking ties arbitrarily):
to minimize the following expression (breaking ties arbitrarily):

Then update the queues for each i in {1, ..., K} according to (Eq. 1). Repeat this procedure for slot t+1.[5]
Note that the random event and queue backlogs observed on slot t act as given constants when selecting the control action for the slot t minimization. Thus, each slot involves a deterministic search for the minimizing control action over the set A. A key feature of this algorithm is that it does not require knowledge of the probability distribution of the random event process.
Approximate scheduling
The above algorithm involves finding a minimum of a function over an abstract set A. In general cases, the minimum might not exist, or might be difficult to find. Thus, it is useful to assume the algorithm is implemented in an approximate manner as follows: Define C as a non-negative constant, and assume that for all slots t, the control action is chosen in the set A to satisfy:
![VP(\alpha (t),\omega (t))+\sum _{{i=1}}^{K}Q_{i}(t)Y_{i}(\alpha (t),\omega (t))\leq C+\inf _{{\alpha \in A}}[VP(\alpha ,\omega (t))+\sum _{{i=1}}^{K}Q_{i}(t)Y_{i}(\alpha ,\omega (t))]](/2014-wikipedia_en_all_02_2014/I/media/a/9/e/d/a9ed9ecf89e0b05634afe00b58237efe.png)
Such a control action is called a C-additive approximation.[5] The case C = 0 corresponds to exact minimization of the desired expression on every slot t.
Performance analysis
This section shows the algorithm results in a time average penalty that is within O(1/V) of optimality, with a corresponding O(V) tradeoff in average queue size.[5]
Average penalty analysis
Define an 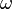 -only policy to be a stationary and randomized policy for choosing the control action based on the observed only. That is, an -only policy specifies, for each possible random event
-only policy to be a stationary and randomized policy for choosing the control action based on the observed only. That is, an -only policy specifies, for each possible random event  , a conditional probability distribution for selecting a control action given that
, a conditional probability distribution for selecting a control action given that 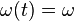 . Such a policy makes decisions independent of current queue backlog. Assume there exists an -only policy
. Such a policy makes decisions independent of current queue backlog. Assume there exists an -only policy  that satisfies the following:
that satisfies the following:
![(Eq.3){\text{ }}E[P(\alpha ^{*}(t),\omega (t))]=p^{*}={\text{ optimal time average penalty for the problem}}](/2014-wikipedia_en_all_02_2014/I/media/4/c/8/0/4c80a8d43652da99b7357cff4935a662.png)
![(Eq.4){\text{ }}E[Y_{i}(\alpha ^{*}(t),\omega (t))]\leq 0{\text{ }}\forall i\in \{1,...,K\}](/2014-wikipedia_en_all_02_2014/I/media/a/c/6/d/ac6d3290c81c71b60c96720768ab9863.png)
The expectations above are with respect to the random variable for slot t, and the random control action chosen on slot t after observing . Such a policy can be shown to exist whenever the desired control problem is feasible and the event space for and action space for are finite, or when mild closure properties are satisfied.[5]
Let represent the action taken by a C-additive approximation of the drift-plus-penalty algorithm of the previous section, for some non-negative constant C. To simplify terminology, we call this action the drift-plus-penalty action, rather than the C-additive approximate drift-plus-penalty action. Let represent the -only decision:
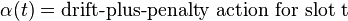

Assume the drift-plus-penalty action is used on each and every slot. By (Eq. 2), the drift-plus-penalty expression under this action satisfies the following for each slot t:




where the last inequality follows because action comes within an additive constant C of minimizing the preceding expression over all other actions in the set A, including . Taking expectations of the above inequality gives:
![E[\Delta (t)+Vp(t)]](/2014-wikipedia_en_all_02_2014/I/media/4/7/f/d/47fd6d9604ea026db145909b714de7a0.png)
![\leq B+C+VE[P(\alpha ^{*}(t),\omega (t))]+\sum _{{i=1}}^{K}E[Q_{i}(t)Y_{i}(\alpha ^{*}(t),\omega (t))]](/2014-wikipedia_en_all_02_2014/I/media/5/a/a/9/5aa9f5a6dc240af9f638b6757ac3aec0.png)
![=B+C+VE[P(\alpha ^{*}(t),\omega (t))]+\sum _{{i=1}}^{K}E[Q_{i}(t)]E[Y_{i}(\alpha ^{*}(t),\omega (t))]](/2014-wikipedia_en_all_02_2014/I/media/8/6/1/8/861855147caa0a2749b180a3a9e93e4a.png)

where the second-to-last equality follows because  are independent of
are independent of  , and the last inequality follows by (Eq.3)-(Eq.4). Notice that the action was never actually implemented. Its existence was used only for comparison purposes to reach the final inequality. Summing the above inequality over the first t>0 slots gives:
, and the last inequality follows by (Eq.3)-(Eq.4). Notice that the action was never actually implemented. Its existence was used only for comparison purposes to reach the final inequality. Summing the above inequality over the first t>0 slots gives:
![\sum _{{\tau =0}}^{{t-1}}E[\Delta (\tau )+Vp(\tau )]\leq (B+C+Vp^{*})t](/2014-wikipedia_en_all_02_2014/I/media/7/5/e/2/75e27485ce0ee1c928f813fef8326382.png)
Using the fact that  together with the law of telescoping sums gives:
together with the law of telescoping sums gives:
![E[L(t)]-E[L(0)]+V\sum _{{\tau =0}}^{{t-1}}E[p(\tau )]\leq (B+C+Vp^{*})t](/2014-wikipedia_en_all_02_2014/I/media/b/3/9/3/b393119095392fc5d550f03144da02f1.png)
Using the fact that L(t) is non-negative and assuming L(0) is identically zero gives:
![V\sum _{{\tau =0}}^{{t-1}}E[p(\tau )]\leq (B+C+Vp^{*})t](/2014-wikipedia_en_all_02_2014/I/media/9/b/7/e/9b7e888a96443a2a0e322fcd7ef42f0a.png)
Dividing the above by Vt yields the following result, which holds for all slots t>0:
![{\frac {1}{t}}\sum _{{\tau =0}}^{{t-1}}E[p(\tau )]\leq p^{*}+(B+C)/V](/2014-wikipedia_en_all_02_2014/I/media/8/1/2/6/81265f2d03ef64670f4def5b514f1a39.png)
Thus, the time average expected penalty can be made arbitrarily close to the optimal value p* by choosing V suitably large. It can be shown that all virtual queues are mean rate stable, and so all desired constraints are satisfied.[5] The parameter V affects the size of the queues, which determines the speed at which the time average constraint functions converge to a non-positive number. A more detailed analysis on the size of the queues is given in the next subsection.
Average queue size analysis
Assume now there exists an -only policy , possibly different from the one that satisfies (Eq. 3)-(Eq.4), that satisfies the following for some  :
:
![(Eq.5){\text{ }}E[Y_{i}(\alpha ^{*}(t),\omega (t))]\leq -\epsilon {\text{ }}\forall i\in \{1,...,K\}](/2014-wikipedia_en_all_02_2014/I/media/8/5/c/6/85c6938ee226dbc120c319fb2d9ba72c.png)
An argument similar to the one in the previous section shows:

Now assume there are upper and lower bounds on the penalty function P(), so that:

Then the above inequality reduces to:

Taking expectations of the above and using (Eq. 5) gives:
![E[\Delta (t)]+Vp_{{min}}\leq B+C+Vp_{{max}}+\sum _{{i=1}}^{K}E[Q_{i}(t)](-\epsilon )](/2014-wikipedia_en_all_02_2014/I/media/a/7/4/e/a74ea5c82630acf7c0a1b4aca7acebb4.png)
A telescoping series argument similar to the one in the previous section can thus be used to show the following for all t>0:[5]
![{\frac {1}{t}}\sum _{{\tau =0}}^{{t-1}}\sum _{{i=1}}^{K}E[Q_{i}(\tau )]\leq {\frac {B+C+V(p_{{max}}-p_{{min}})}{\epsilon }}](/2014-wikipedia_en_all_02_2014/I/media/b/f/f/e/bffeaf6d0b35f5ca3b790fefcd78e543.png)
This shows that average queue size is indeed O(V).
Probability 1 convergence
The above analysis considers time average expectations. Related probability 1 performance bounds for infinite horizon time average queue size and penalty can be derived using the drift-plus-penalty method together with martingale theory.[14]
Treatment of queueing systems
The above analysis considers constrained optimization of time averages in a stochastic system that did not have any explicit queues. Each time average inequality constraint was mapped to a virtual queue according to (Eq. 1). In the case of optimizing a queueing network, the virtual queue equations in (Eq. 1) are replaced by the actual queueing equations.
Convex functions of time averages
A related problem is the minimization of a convex function of time averages subject to constraints, such as:


where f() and g_i() are convex functions, and where the time averages are defined:
![\overline {y}_{i}=\lim _{{t\rightarrow \infty }}{\frac {1}{t}}\sum _{{\tau =0}}^{{t-1}}E[y_{i}(\tau )]](/2014-wikipedia_en_all_02_2014/I/media/f/1/c/0/f1c071b99264c2b04f53520137f0d99c.png)
Such problems of optimizing convex functions of time averages can be transformed into problems of optimizing time averages of functions via auxiliary variables (see Chapter 5 of the Neely textbook).[2][5] The latter problems can then be solved by the drift-plus-penalty method as described in previous subsections. An alternative primal-dual method makes decisions similar to drift-plus-penalty decisions, but uses a penalty defined by partial derivatives of the objective function f().[5] [15] [16] The primal-dual approach can also be used to find local optimums in cases when the function f() is non-convex.[5]
Delay tradeoffs and related work
The mathematical analysis in the previous section shows that the drift-plus-penalty method produces a time average penalty that is within O(1/V) of optimality, with a corresponding O(V) tradeoff in average queue size. This method, together with the O(1/V), O(V) tradeoff, was developed in Neely[9] and Neely, Modiano, Li [2] in the context of maximizing network utility subject to stability.
A related algorithm for maximizing network utility was developed by Eryilmaz and Srikant. [17] The Eryilmaz and Srikant work resulted in an algorithm very similar to the drift-plus-penalty algorithm, but used a different analytical technique. That technique was based on Lagrange multipliers. A direct use of the Lagrange multiplier technique results in a worse tradeoff of O(1/V), O(V^2). However, the Lagrange multiplier analysis was later strengthened by Huang and Neely to recover the original O(1/V), O(V) tradeoffs, while showing that queue sizes are tightly clustered around the Lagrange multiplier of a corresponding deterministic optimization problem. [18] This clustering result can be used to modify the drift-plus-penalty algorithm to enable improved O(1/V), O(log^2(V)) tradeoffs. The modifications can use either place-holder backlog[18] or Last-in-First-Out (LIFO) scheduling. [19] [20]
When implemented for non-stochastic functions, the drift-plus-penalty method is similar to the dual subgradient method of convex optimization theory, with the exception that its output is a time average of primal variables, rather than the primal variables themselves.[4][6] A related primal-dual technique for maximizing utility in a stochastic queueing network was developed by Stolyar using a fluid model analysis. [15] [16] The Stolyar analysis does not provide analytical results for a performance tradeoff between utility and queue size. A later analysis of the primal-dual method for stochastic networks proves a similar O(1/V), O(V) utility and queue size tradeoff, and also shows local optimality results for minimizing non-convex functions of time averages, under an additional convergence assumption.[5] However, this analysis does not specify how much time is required for the time averages to converge to something close to their infinite horizon limits. Related primal-dual algorithms for utility maximization without queues were developed by Agrawal and Subramanian [21] and Kushner and Whiting [22] .
Extensions to non-i.i.d. event processes
The drift-plus-penalty algorithm is known to ensure similar performance guarantees for more general ergodic processes , so that the i.i.d. assumption is not crucial to the analysis. The algorithm can be shown to be robust to non-ergodic changes in the probabilities for . In certain scenarios, it can be shown to provide desirable analytical guarantees, called universal scheduling guarantees, for arbitrary processes.[5]
Extensions to variable frame length systems
The drift-plus-penalty method can be extended to treat systems that operate over variable size frames.[23]
[24]
In that case, the frames are labeled with indices r in {0, 1, 2, ...} and the frame durations are denoted {T[0], T[1], T[2], ...}, where T[r] is a non-negative real number for each frame r. Let ![\Delta [r]](/2014-wikipedia_en_all_02_2014/I/media/4/9/7/4/4974371a2ab41e1138c35fbea50d3f19.png) and
and ![p[r]](/2014-wikipedia_en_all_02_2014/I/media/c/8/7/4/c87401640aeb34fdc580abab66250485.png) be the drift between frame r and r+1, and the total penalty incurred during frame r, respectively. The extended algorithm takes a control action over each frame r to minimize a bound on the following ratio of conditional expectations:
be the drift between frame r and r+1, and the total penalty incurred during frame r, respectively. The extended algorithm takes a control action over each frame r to minimize a bound on the following ratio of conditional expectations:
![{\frac {E[\Delta [r]+Vp[r]|Q[r]]}{E[T[r]|Q[r]]}}](/2014-wikipedia_en_all_02_2014/I/media/b/8/1/0/b810f3b5f25ba109478d4f59e24e9a94.png)
where Q[r] is the vector of queue backlogs at the beginning of frame r. In the special case when all frames are the same size and are normalized to 1 slot length, so that T[r]=1 for all r, the above minimization reduces to the standard drift-plus-penalty technique. This frame-based method can be used for constrained optimization of Markov decision problems (MDPs) and for other problems involving systems that experience renewals. [23] [24]
Application to convex programming
Let x = (x_1, ..., x_N) be an N-dimensinal vector of real numbers, and define the hyper-rectangle A by:

where x_{min, i}, x_{max, i} are given real numbers that satisfy 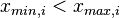 for all i. Let P(x) and
for all i. Let P(x) and  for i in {1, ..., K} be continuous and convex functions of the x vector over all x in A. Consider the following convex programming problem:
for i in {1, ..., K} be continuous and convex functions of the x vector over all x in A. Consider the following convex programming problem:

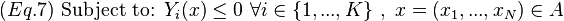
This can be solved by the drift-plus-penalty method as follows: Consider the special case of a deterministic system with no random event process . Define the control action as:
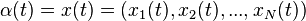
and define the action space as the N-dimensional hyper-rectangle A. Define penalty and constraint functions as:


Define the following time averages:



Now consider the following time average optimization problem:


By Jensen's inequality the following holds for all slots t>0:

From this, it can be shown that an optimal solution to the time-average problem (Eq. 8)-(Eq. 9) can be achieved by solutions of the type x(t) = x* for all slots t, where x* is a vector that solves the convex program (Eq. 6)-(Eq. 7). Further, any time-averaged vector  corresponding to a solution of the time-average problem (Eq. 8)-(Eq. 9) must solve the convex program (Eq. 6)-(Eq. 7). Therefore, the original convex program (Eq. 6)-(Eq. 7) can be solved (to within any desired accuracy) by taking the time average of the decisions made when the drift-plus-penalty algorithm is applied to the corresponding time-averaged problem (Eq. 8)-(Eq. 9). The drift-plus-penalty algorithm for problem (Eq. 8)-(Eq. 9) reduces to the following:
corresponding to a solution of the time-average problem (Eq. 8)-(Eq. 9) must solve the convex program (Eq. 6)-(Eq. 7). Therefore, the original convex program (Eq. 6)-(Eq. 7) can be solved (to within any desired accuracy) by taking the time average of the decisions made when the drift-plus-penalty algorithm is applied to the corresponding time-averaged problem (Eq. 8)-(Eq. 9). The drift-plus-penalty algorithm for problem (Eq. 8)-(Eq. 9) reduces to the following:
Drift-plus-penalty algorithm for convex programming
Every slot t, choose vector  to minimize the expression:
to minimize the expression:

Then update the queues according to:
![Q_{i}(t+1)=\max[Q_{i}(t)+Y_{i}(x(t)),0]{\text{ }}\forall i\in \{1,...,K\}](/2014-wikipedia_en_all_02_2014/I/media/3/4/3/1/3431825cdb68bbb35ca676b244f70b2e.png)
The time average vector 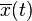 converges to an O(1/V) approximation to the convex program.[6]
converges to an O(1/V) approximation to the convex program.[6]
This algorithm is similar to the standard dual subgradient algorithm of optimization theory, using a fixed stepsize of 1/V. [25] However, a key difference is that the dual subgradient algorithm is typically analyzed under restrictive strict convexity assumptions that are needed for the primal variables x(t) to converge. There are many important cases where these variables do not converge to the optimal solution, and never even get near the optimal solution (this is the case for most linear programs, as shown below). On the other hand, the drift-plus-penalty algorithm does not require strict convexity assumptions. It ensures that the time averages of the primals converge to a solution that is within O(1/V) of optimality, with O(V) bounds on queue sizes (it can be shown that this translates into an O(V^2) bound on convergence time).[6]
Drift-plus-penalty algorithm for linear programming
Consider the special case of a linear program. Specifically, suppose:


for given real-valued constants (c_1, …, c_N), (a_{in}), (b_1, …, b_K). Then the above algorithm reduces to the following: Every slot t and for each variable n in {1, …, N}, choose x_n(t) in [x_{min,n}, x_{max,n}] to minimize the expression:
![[Vc_{n}+\sum _{{i=1}}^{K}Q_{i}(t)a_{{in}}]x_{n}(t)](/2014-wikipedia_en_all_02_2014/I/media/a/1/2/9/a129f386e83bbe4e093d7e6b86c243a8.png)
Then update queues Q_i(t) as before. This amounts to choosing each variable x_i(t) according to the simple bang-bang control policy:


Since the primal variables x_i(t) are always either x_{min,i} or x_{max,i}, they can never converge to the optimal solution if the optimal solution is not a vertex point of the hyper-rectangle A. However, the time-averages of these bang-bang decisions indeed converge to an O(1/V) approximation of the optimal solution. For example, suppose that x_{min,1}=0, x_{max,1}=1, and suppose that all optimal solutions to the linear program have x_1 = 3/4. Then roughly 3/4 of the time the bang-bang decision for the first variable will be x_1(t)=1, and the remaining time it will be x_1(t) = 0.[7]
Related links
References
- ↑ 1.0 1.1 M. J. Neely, "Energy Optimal Control for Time Varying Wireless Networks," IEEE Transactions on Information Theory, vol. 52, no. 7, pp. 2915-2934, July 2006.
- ↑ 2.0 2.1 2.2 2.3 M. J. Neely, E. Modiano, and C. Li, "Fairness and Optimal Stochastic Control for Heterogeneous Networks," Proc. IEEE INFOCOM, March 2005.
- ↑ 3.0 3.1 L. Tassiulas and A. Ephremides, "Stability Properties of Constrained Queueing Systems and Scheduling Policies for Maximum Throughput in Multihop Radio Networks, IEEE Transactions on Automatic Control, vol. 37, no. 12, pp. 1936-1948, Dec. 1992.
- ↑ 4.0 4.1 4.2 L. Georgiadis, M. J. Neely, and L. Tassiulas, "Resource Allocation and Cross-Layer Control in Wireless Networks," Foundations and Trends in Networking, vol. 1, no. 1, pp. 1-149, 2006.
- ↑ 5.0 5.1 5.2 5.3 5.4 5.5 5.6 5.7 5.8 5.9 5.10 5.11 5.12 5.13 5.14 5.15 5.16 M. J. Neely. Stochastic Network Optimization with Application to Communication and Queueing Systems, Morgan & Claypool, 2010.
- ↑ 6.0 6.1 6.2 6.3 M. J. Neely, "Distributed and Secure Computation of Convex Programs over a Network of Connected Processors," DCDIS Conf, Guelph, Ontario, July 2005
- ↑ 7.0 7.1 S. Supittayapornpong and M. J. Neely, "Quality of Information Maximization for Wireless Networks via a Fully Separable Quadratic Policy," arXiv:1211.6162v2, Nov. 2012.
- ↑ L. Tassiulas and A. Ephremides, "Dynamic Server Allocation to Parallel Queues with Randomly Varying Connectivity," IEEE Transactions on Information Theory, vol. 39, no. 2, pp. 466-478, March 1993.
- ↑ 9.0 9.1 M. J. Neely. Dynamic Power Allocation and Routing for Satellite and Wireless Networks with Time Varying Channels. Ph.D. Dissertation, Massachusetts Institute of Technology, LIDS. November 2003.
- ↑ R. Urgaonkar, B. Urgaonkar, M. J. Neely, A. Sivasubramaniam, "Optimal Power Cost Management Using Stored Energy in Data Centers," Proc. SIGMETRICS 2011.
- ↑ M. Baghaie, S. Moeller, B. Krishnamachari, "Energy Routing on the Future Grid: A Stochastic Network Optimization Approach," Proc. International Conf. on Power System Technology (POWERCON), Oct. 2010.
- ↑ M. J. Neely, A. S. Tehrani, and A. G. Dimakis, "Efficient Algorithms for Renewable Energy Allocation to Delay Tolerant Consumers," 1st IEEE International Conf. on Smart Grid Communications, 2010.
- ↑ M. J. Neely and L. Huang, "Dynamic Product Assembly and Inventory Control for Maximum Profit," Proc. IEEE Conf. on Decision and Control, Atlanta, GA, Dec. 2010.
- ↑ M. J. Neely, "Queue Stability and Probability 1 Convergence via Lyapunov Optimization," Journal of Applied Mathematics, vol. 2012, doi:10.1155/2012/831909.
- ↑ 15.0 15.1 A. Stolyar, "Maximizing Queueing Network Utility subject to Stability: Greedy Primal-Dual Algorithm," Queueing Systems, vol. 50, no. 4, pp. 401-457, 2005.
- ↑ 16.0 16.1 A. Stolyar, "Greedy Primal-Dual Algorithm for Dynamic Resource Allocation in Complex Networks," Queueing Systems, vol. 54, no. 3, pp. 203-220, 2006.
- ↑ A. Eryilmaz and R. Srikant, "Fair Resource Allocation in Wireless Networks using Queue-Length-Based Scheduling and Congestion Control," Proc. IEEE INFOCOM, March 2005.
- ↑ 18.0 18.1 L. Huang and M. J. Neely, "Delay Reduction via Lagrange Multipliers in Stochastic Network Optimization," IEEE Trans. on Automatic Contro, vol. 56, no. 4, pp. 842-857, April 2011.
- ↑ S. Moeller, A. Sridharan, B. Krishnamachari, and O. Gnawali, "Routing without Routes: The Backpressure Collection Protocol," Proc. IPSN 2010.
- ↑ L. Huang, S. Moeller, M. J. Neely, and B. Krishnamachari, "LIFO-Backpressure Achieves Near Optimal Utility-Delay Tradeoff," IEEE/ACM Transactions on Networking, to appear.
- ↑ R. Agrawal and V. Subramanian, "Optimality of certain channel aware scheduling policies," Proc. 40th Annual Allerton Conf. on Communication, Control, and Computing, Monticello, IL, Oct. 2002.
- ↑ H. Kushner and P. Whiting, "Asymptotic Properties of Proportional-Fair Sharing Algorithms," Proc. 40th Annual Allerton Conf. on Communication, Control, and Computing, Monticello, IL, Oct. 2002.
- ↑ 23.0 23.1 C. Li and M. J. Neely, "Network utility maximization over partially observable Markovian channels," Performance Evaluation, dx.doi.org/10.1016/j.peva.2012.10.003.
- ↑ 24.0 24.1 M. J. Neely, "Dynamic Optimization and Learning for Renewal Systems," IEEE Transactions on Automatic Control, vol. 58, no. 1, pp. 32-46, Jan. 2013.
- ↑ D. P. Bertsekas and A. Nedic and A. E. Ozdaglar. Convex Analysis and Optimization, Boston: Athena Scientific, 2003.
Primary Sources
- M. J. Neely. Stochastic Network Optimization with Application to Communication and Queueing Systems, Morgan & Claypool, 2010.