Deming regression

In statistics, Deming regression, named after W. Edwards Deming, is an errors-in-variables model which tries to find the line of best fit for a two-dimensional dataset. It differs from the simple linear regression in that it accounts for errors in observations on both the x- and the y- axis. It is a special case of total least squares, which allows for any number of predictors and a more complicated error structure.
Deming regression is equivalent to the maximum likelihood estimation of an errors-in-variables model in which the errors for the two variables are assumed to be independent and normally distributed, and the ratio of their variances, denoted δ, is known.[1] In practice, this ratio might be estimated from related data-sources; however the regression procedure takes no account for possible errors in estimating this ratio.
The Deming regression is only slightly more difficult to compute compared to the simple linear regression. Many software packages used in clinical chemistry, such as Analyse-it, EP Evaluator, MedCalc and S-PLUS offer Deming regression.
The model was originally introduced by Adcock (1878) who considered the case δ = 1, and then more generally by Kummell (1879) with arbitrary δ. However their ideas remained largely unnoticed for more than 50 years, until they were revived by Koopmans (1937) and later propagated even more by Deming (1943). The latter book became so popular in clinical chemistry and related fields that the method was even dubbed Deming regression in those fields.[2]
Specification
Assume that the available data (yi, xi) are measured observations of the "true" values (yi*, xi*):

where errors ε and η are independent and the ratio of their variances is assumed to be known:
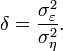
In practice the variance of the  and
and  parameters is often unknown which complicates the estimate of
parameters is often unknown which complicates the estimate of  but where the measurement method for and is the same they are likely to be equal so that
but where the measurement method for and is the same they are likely to be equal so that  for this case.
for this case.
We seek to find the line of "best fit" y* = β0 + β1x*, such that the weighted sum of squared residuals of the model is minimized:[3]
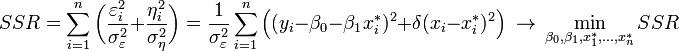
Solution
The solution can be expressed in terms of the second-degree sample moments. That is, we first calculate the following quantities (all sums go from i = 1 to n):

Finally, the least-squares estimates of model's parameters will be[4]
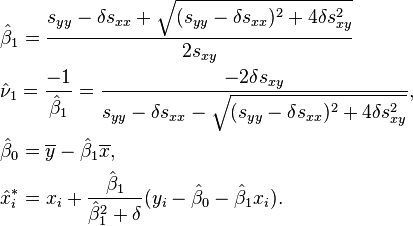
where 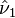 is slope of the line normal (perpendicular) to
is slope of the line normal (perpendicular) to  .
.
The case of equal error variances
When , Deming regression becomes orthogonal regression: it minimizes the sum of squared perpendicular distances from the data points to the regression line. In this case, denote each observation as a point zj in the complex plane (i.e., the point (xj, yj) is written as zj = xj + iyj where i is the imaginary unit). Denote as Z the sum of the squared differences of the data points from the centroid (also denoted in complex coordinates), which is the point whose horizontal and vertical locations are the averages of those of the data points. Then:[5]
- If Z = 0, then every line through the centroid is a line of best orthogonal fit.
- If Z ≠ 0, the orthogonal regression line goes through the centroid and is parallel to the vector from the origin to
 .
.
A trigonometric representation of the orthogonal regression line was given by Coolidge in 1913.[6]
Application
In the case of three non-collinear points in the plane, the triangle with these points as its vertices has a unique Steiner inellipse that is tangent to the triangle's sides at their midpoints. The major axis of this ellipse falls on the orthogonal regression line for the three vertices.[7]
Notes
References
- Adcock, R. J. (1878). "A problem in least squares". The Analyst (Annals of Mathematics) 5 (2): 53–54. doi:10.2307/2635758. JSTOR 2635758.
- Coolidge, J. L. (1913). "Two geometrical applications of the mathematics of least squares". The American Mathematical Monthly 20 (6): 187–190.
- Cornbleet, P.J.; Gochman, N. (1979). "Incorrect Least–Squares Regression Coefficients". Clin. Chem. 25 (3): 432–438. PMID 262186.
- Deming, W. E. (1943). Statistical adjustment of data. Wiley, NY (Dover Publications edition, 1985). ISBN 0-486-64685-8.
- Fuller, Wayne A. (1987). Measurement error models. John Wiley & Sons, Inc. ISBN 0-471-86187-1.
- Glaister, P. (March 2001). "Least squares revisited". The Mathematical Gazette 85: 104-107.
- Koopmans, T. C. (1937). Linear regression analysis of economic time series. DeErven F. Bohn, Haarlem, Netherlands.
- Kummell, C. H. (1879). "Reduction of observation equations which contain more than one observed quantity". The Analyst (Annals of Mathematics) 6 (4): 97–105. doi:10.2307/2635646. JSTOR 2635646.
- Linnet, K. (1993). "Evaluation of regression procedures for method comparison studies". Clinical Chemistry 39 (3): 424–432. PMID 8448852.
- Minda, D.; Phelps, S. (2008). "Triangles, ellipses, and cubic polynomials". American Mathematical Monthly 115 (8): 679–689. MR 2456092.