Damerau–Levenshtein distance
In information theory and computer science, the Damerau–Levenshtein distance (named after Frederick J. Damerau and Vladimir I. Levenshtein[1][2][3]) is a distance (string metric) between two strings, i.e., finite sequence of symbols, given by counting the minimum number of operations needed to transform one string into the other, where an operation is defined as an insertion, deletion, or substitution of a single character, or a transposition of two adjacent characters. In his seminal paper,[4] Damerau not only distinguished these four edit operations but also stated that they correspond to more than 80% of all human misspellings. Damerau's paper considered only misspellings that could be corrected with at most one edit operation. The corresponding edit distance, i.e., dealing with multiple edit operations, known as the Levenshtein distance, was introduced by Levenshtein,[5] but it did not include transpositions in the set of basic operations. The name Damerau–Levenshtein distance is used[citation needed] to refer to the edit distance that allows multiple edit operations including transpositions, although it is not clear whether the term Damerau–Levenshtein distance is sometimes used in some sources[citation needed] as to take into account non-adjacent transpositions or not.
While the original motivation was to measure distance between human misspellings to improve applications such as spell checkers, Damerau–Levenshtein distance has also seen uses in biology to measure the variation between DNA.
Algorithm
Adding transpositions sounds simple, but in reality there is a serious complication. Presented here are two algorithms: the first,[6] simpler one, computes what is known as the optimal string alignment[citation needed] (sometimes called the restricted edit distance[citation needed]), while the second one[7] computes the Damerau–Levenshtein distance with adjacent transpositions. The difference between the two algorithms consists in that the optimal string alignment algorithm computes the number of edit operations needed to make the strings equal under the condition that no substring is edited more than once, whereas the second one presents no such restriction.
Take for example the edit distance between CA and ABC. The Damerau–Levenshtein distance LD(CA,ABC) = 2 because CA -> AC -> ABC, but the optimal string alignment distance OSA(CA,ABC) = 3 because if the operation CA -> AC is used, it is not possible to use AC -> ABC because that would require the substring to be edited more than once, which is not allowed in OSA, and therefore the shortest sequence of operations is CA -> A -> AB -> ABC. Note that for the optimal string alignment distance, the triangle inequality does not hold: OSA(CA,AC) + OSA(AC,ABC) < OSA(CA,ABC), and so it is not a true metric.
Firstly, let us consider a direct extension of the formula used to calculate Levenshtein distance. Below is pseudocode for a function OptimalStringAlignmentDistance that takes two strings, str1 of length lenStr1, and str2 of length lenStr2, and computes the optimal string alignment distance between them:
int OptimalStringAlignmentDistance(char str1[1..lenStr1], char str2[1..lenStr2]) // d is a table with lenStr1+1 rows and lenStr2+1 columns declare int d[0..lenStr1, 0..lenStr2] // i and j are used to iterate over str1 and str2 declare int i, j, cost // for loop is inclusive, need table 1 row/column larger than string length for i from 0 to lenStr1 d[i, 0] := i for j from 1 to lenStr2 d[0, j] := j // pseudo-code assumes string indices start at 1, not 0 // if implemented, make sure to start comparing at 1st letter of strings for i from 1 to lenStr1 for j from 1 to lenStr2 if str1[i] = str2[j] then cost := 0 else cost := 1 d[i, j] := minimum( d[i-1, j ] + 1, // deletion d[i , j-1] + 1, // insertion d[i-1, j-1] + cost // substitution ) if(i > 1 and j > 1 and str1[i] = str2[j-1] and str1[i-1] = str2[j]) then d[i, j] := minimum( d[i, j], d[i-2, j-2] + cost // transposition ) return d[lenStr1, lenStr2]
Basically this is the algorithm to compute Levenshtein distance with one additional recurrence:
if(i > 1 and j > 1 and str1[i] = str2[j-1] and str1[i-1] = str2[j]) then d[i, j] := minimum( d[i, j], d[i-2, j-2] + cost // transposition )
Here is the second algorithm that computes the true Damerau–Levenshtein distance with adjacent transpositions (ActionScript 3.0); this function requires as an additional parameter the size of the alphabet (C), so that all entries of the arrays are in 0..(C−1):
To devise a proper algorithm to calculate unrestricted Damerau–Levenshtein distance note that there always exists an optimal sequence of edit operations, where once-transposed letters are never modified afterwards. Thus, we need to consider only two symmetric ways of modifying a substring more than once: (1) transpose letters and insert an arbitrary number of characters between them, or (2) delete a sequence of characters and transpose letters that become adjacent after deletion. The straightforward implementation of this idea gives an algorithm of cubic complexity: 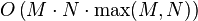 , where M and N are string lengths. Using the ideas of Lowrance and Wagner,[7] this naive algorithm can be improved to be
, where M and N are string lengths. Using the ideas of Lowrance and Wagner,[7] this naive algorithm can be improved to be  in the worst case.
in the worst case.
It is interesting that the bitap algorithm can be modified to process transposition. See the information retrieval section of for an example of such an adaptation.
Applications
Damerau–Levenshtein distance plays an important role in natural language processing. In natural languages, strings are short and the number of errors (misspellings) rarely exceeds 2. In such circumstances, restricted and real edit distance differ very rarely. Oommen and Loke even mitigated the limitation of the restricted edit distance by introducing generalized transpositions. Nevertheless, one must remember that the restricted edit distance usually does not satisfy the triangle inequality and, thus, cannot be used with metric trees.
DNA
Since DNA frequently undergoes insertions, deletions, substitutions, and transpositions, and each of these operations occurs on approximately the same timescale, the Damerau–Levenshtein distance is an appropriate metric of the variation between two strands of DNA. More common in DNA, protein, and other bioinformatics related alignment tasks is the use of closely related algorithms such as Needleman–Wunsch algorithm or Smith–Waterman algorithm.
Fraud detection
The algorithm can be used with any set of words, like vendor names. Since entry is manual by nature there is a risk of entering false vendor. A fraudster employee may enter one real vendor such as "Rich Heir Estate Services" versus a false vendor "Rich Hier State Services". The fraudster would then create a false bank account and have the company route checks to the real vendor and false vendor. The Damerau–Levenshtein algorithm will detect the transposed and dropped letter and bring attention of the items to a fraud examiner.
See also
- Approximate string matching
- Levenshtein automata
- Typosquatting
References
- ↑ Brill and Moore (2000). "An Improved Error Model for Noisy Channel Spelling Correction". Proceedings of the 38th Annual Meeting on Association for Computational Linguistics. pp. 286–293. doi:10.3115/1075218.1075255.
- ↑ Bard (2007). "Spelling-error tolerant, order-independent pass-phrases via the Damerau-Levenshtein string-edit distance metric". Proceedings of the fifth Australasian symposium on ACSW frontiers 68. pp. 117–124.
- ↑ Li et al. (2006). "Exploring distributional similarity based models for query spelling correction". Proceedings of the 21st International Conference on Computational Linguistics and the 44th annual meeting of the Association for Computational Linguistics. pp. 1025–1032. doi:10.3115/1220175.1220304.
- ↑ Damerau, Fred J. (March 1964), "A technique for computer detection and correction of spelling errors", Communications of the ACM (ACM) 7 (3): 171–176, doi:10.1145/363958.363994
- ↑ Vladimir I. Levenshtein. Binary codes capable of correcting deletions, insertions, and reversals. Soviet Physics Doklady, 1966.
- ↑ B. J. Oommen; R. K. S. Loke. Pattern recognition of strings with substitutions, insertions, deletions and generalized transpositions. doi:10.1016/S0031-3203(96)00101-X. CiteSeerX: 10.1.1.50.1459.
- ↑ 7.0 7.1 Lowrance, Roy; Wagner, Robert A. (April 1975), "An Extension of the String-to-String Correction Problem", JACM 22 (2): 177–183, doi:10.1145/321879.321880
Further reading
External links
- Python implementation of optimal string alignment distance
- pyxDamerauLevenshtein - fast Cython translation of the above pure Python implementation
- FREJ – an open source java library which implements approximate substring search using Damerau–Levenshtein distance.
- Ruby gem compiled implementation
- Ruby translation of above Python implementation.
- Matlab implementation
- Perl implementation
- NodeJS / JavaScript implementation
- C implementation
- C++ Damerau-Levenshtein UDF for MySQL implementation