Cauchy distribution
Probability density function The purple curve is the standard Cauchy distribution | |
Cumulative distribution function | |
| Parameters |  location (real) location (real)γ > 0 scale (real) |
|---|---|
| Support |  |
![{\frac {1}{\pi \gamma \,\left[1+\left({\frac {x-x_{0}}{\gamma }}\right)^{2}\right]}}\!](/2014-wikipedia_en_all_02_2014/I/media/1/1/0/a/110abf1f3bbdd637b6ddd41296caa067.png) | |
| CDF |  |
| Mean | undefined |
| Median | |
| Mode | |
| Variance | undefined |
| Skewness | undefined |
| Ex. kurtosis | undefined |
| Entropy | 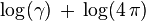 |
| MGF | does not exist |
| CF |  |
The Cauchy distribution, named after Augustin Cauchy, is a continuous probability distribution. It is also known, especially among physicists, as the Lorentz distribution (after Hendrik Lorentz), Cauchy–Lorentz distribution, Lorentz(ian) function, or Breit–Wigner distribution. The simplest Cauchy distribution is called the standard Cauchy distribution. It has the distribution of a random variable that is the ratio of two independent standard normal random variables. This has the probability density function

Its cumulative distribution function has the shape of an arctangent function arctan(x):

The Cauchy distribution is often used in statistics as the canonical example of a "pathological" distribution. Both its mean and its variance are undefined. (But see the section Explanation of undefined moments below.) The Cauchy distribution does not have finite moments of order greater than or equal to one; only fractional absolute moments exist.[1] The Cauchy distribution has no moment generating function.
Its importance in physics is the result of it being the solution to the differential equation describing forced resonance.[2] In mathematics, it is closely related to the Poisson kernel, which is the fundamental solution for the Laplace equation in the upper half-plane. In spectroscopy, it is the description of the shape of spectral lines which are subject to homogeneous broadening in which all atoms interact in the same way with the frequency range contained in the line shape. Many mechanisms cause homogeneous broadening, most notably collision broadening, and Chantler–Alda radiation.[3] In its standard form, it is the maximum entropy probability distribution for a random variate X for which[4]
![\operatorname {E}\!\left[\ln(1+X^{2})\right]=\ln(4)](/2014-wikipedia_en_all_02_2014/I/media/e/b/8/d/eb8d8efb6c1daf064b7b8667eeff1c9f.png)
Characterisation
Probability density function
The Cauchy distribution has the probability density function
![f(x;x_{0},\gamma )={\frac {1}{\pi \gamma \left[1+\left({\frac {x-x_{0}}{\gamma }}\right)^{2}\right]}}={1 \over \pi }\left[{\gamma \over (x-x_{0})^{2}+\gamma ^{2}}\right],](/2014-wikipedia_en_all_02_2014/I/media/c/2/0/c/c20c295d95a9bb416922020313ac0331.png)
where x0 is the location parameter, specifying the location of the peak of the distribution, and γ is the scale parameter which specifies the half-width at half-maximum (HWHM), alternatively 2γ is full width at half maximum (FWHM). γ is also equal to half the interquartile range and is sometimes called the probable error. Augustin-Louis Cauchy exploited such a density function in 1827 with an infinitesimal scale parameter, defining what would now be called a Dirac delta function.
The amplitude of the above Lorentzian function is given by
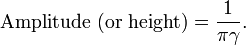
The special case when x0 = 0 and γ = 1 is called the standard Cauchy distribution with the probability density function
In physics, a three-parameter Lorentzian function is often used:
![f(x;x_{0},\gamma ,I)={\frac {I}{\left[1+\left({\frac {x-x_{0}}{\gamma }}\right)^{2}\right]}}=I\left[{\gamma ^{2} \over (x-x_{0})^{2}+\gamma ^{2}}\right],](/2014-wikipedia_en_all_02_2014/I/media/c/8/b/1/c8b180dc4c7de57b5368bc8e56ec5b9e.png)
where I is the height of the peak.
Cumulative distribution function
The cumulative distribution function is:
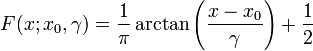
and the quantile function (inverse cdf) of the Cauchy distribution is
![Q(p;x_{0},\gamma )=x_{0}+\gamma \,\tan \left[\pi \left(p-{\tfrac {1}{2}}\right)\right].](/2014-wikipedia_en_all_02_2014/I/media/9/7/1/e/971ef3b71572a04317d498448355a605.png)
It follows that the first and third quartiles are (x0−γ, x0+γ), and hence the interquartile range is 2γ.
The derivative of the quantile function, the quantile density function, for the Cauchy distribution is:
![Q'(p;\gamma )=\gamma \,\pi \,{\sec }^{2}\left[\pi \left(p-{\tfrac {1}{2}}\right)\right].\!](/2014-wikipedia_en_all_02_2014/I/media/c/4/f/a/c4fa70133f7e8adbbc92a7202577ad65.png)
The differential entropy of a distribution can be defined in terms of its quantile density,[5] specifically
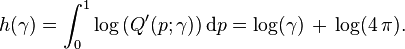
Properties
The Cauchy distribution is an example of a distribution which has no mean, variance or higher moments defined. Its mode and median are well defined and are both equal to x0.
When U and V are two independent normally distributed random variables with expected value 0 and variance 1, then the ratio U/V has the standard Cauchy distribution.
If X1, ..., Xn are independent and identically distributed random variables, each with a standard Cauchy distribution, then the sample mean (X1+ ... +Xn)/n has the same standard Cauchy distribution. To see that this is true, compute the characteristic function of the sample mean:
![\phi _{{\overline {X}}}(t)={\mathrm {E}}\left[e^{{i\overline {X}t}}\right]](/2014-wikipedia_en_all_02_2014/I/media/c/1/0/5/c1053ae045b8e90115cef35b2836b047.png)
where  is the sample mean. This example serves to show that the hypothesis of finite variance in the central limit theorem cannot be dropped. It is also an example of a more generalized version of the central limit theorem that is characteristic of all stable distributions, of which the Cauchy distribution is a special case.
is the sample mean. This example serves to show that the hypothesis of finite variance in the central limit theorem cannot be dropped. It is also an example of a more generalized version of the central limit theorem that is characteristic of all stable distributions, of which the Cauchy distribution is a special case.
The Cauchy distribution is an infinitely divisible probability distribution. It is also a strictly stable distribution.[6]
The standard Cauchy distribution coincides with the Student's t-distribution with one degree of freedom.
Like all stable distributions, the location-scale family to which the Cauchy distribution belongs is closed under linear transformations with real coefficients. In addition, the Cauchy distribution is the only univariate distribution which is closed under linear fractional transformations with real coefficients.[7] In this connection, see also McCullagh's parametrization of the Cauchy distributions.
Characteristic function
Let X denote a Cauchy distributed random variable. The characteristic function of the Cauchy distribution is given by
![\phi _{X}(t;x_{0},\gamma )={\mathrm {E}}\left[e^{{iXt}}\right]=\int _{{-\infty }}^{\infty }f(x;x_{{0}},\gamma )e^{{ixt}}\,dx=e^{{ix_{0}t-\gamma |t|}}.](/2014-wikipedia_en_all_02_2014/I/media/6/3/e/7/63e7eeccac20473b149be6a519d242cf.png)
which is just the Fourier transform of the probability density. [citation needed] The original probability density may be expressed in terms of the characteristic function, essentially by using the inverse Fourier transform:
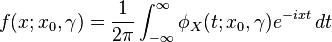
Observe that the characteristic function is not differentiable at the origin: this corresponds to the fact that the Cauchy distribution does not have an expected value.
Explanation of undefined moments
Mean
If a probability distribution has a density function f(x), then the mean is

The question is now whether this is the same thing as
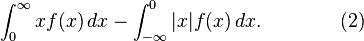
If at most one of the two terms in (2) is infinite, then (1) is the same as (2). But in the case of the Cauchy distribution, both the positive and negative terms of (2) are infinite. This means (2) is undefined. Moreover, if (1) is construed as a Lebesgue integral, then (1) is also undefined, because (1) is then defined simply as the difference (2) between positive and negative parts.
However, if (1) is constructed as an improper integral rather than a Lebesgue integral, then (2) is undefined, and (1) is not necessarily well-defined. We may take (1) to mean

and this is its Cauchy principal value, which is zero, but we could also take (1) to mean, for example,
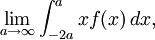
which is not zero, as can be seen easily by computing the integral.
Because the integrand is bounded and is not Lebesgue integrable, it is not even Henstock–Kurzweil integrable. Various results in probability theory about expected values, such as the strong law of large numbers, will not work in such cases.
Higher moments
The Cauchy distribution does not have finite moments of any order. Some of the higher raw moments do exist and have a value of infinity, for example the raw second moment:
![{\mathrm {E}}[X^{2}]\propto \int _{{-\infty }}^{{\infty }}{x^{2} \over 1+x^{2}}\,dx=\int _{{-\infty }}^{{\infty }}1-{1 \over 1+x^{2}}\,dx=\int _{{-\infty }}^{{\infty }}dx-\int _{{-\infty }}^{{\infty }}{1 \over 1+x^{2}}\,dx=\int _{{-\infty }}^{{\infty }}dx-\pi =\infty .](/2014-wikipedia_en_all_02_2014/I/media/5/8/b/9/58b9296e7691b65d8415e92c9d7c5091.png)
By re-arranging the formula, one can see that the second moment is essentially the infinite integral of a constant (here 1). Higher even-powered raw moments will also evaluate to infinity. Odd-powered raw moments, however, do not exist at all (i.e. are undefined), which is distinctly different from existing with the value of infinity. The odd-powered raw moments are undefined because their values are essentially equivalent to ∞ − ∞ since the two halves of the integral both diverge and have opposite signs. The first raw moment is the mean, which, being odd, does not exist. (See also the discussion above about this.) This in turn means that all of the central moments and standardized moments do not exist (are undefined), since they are all based on the mean. The variance — which is the second central moment — is likewise non-existent (despite the fact that the raw second moment exists with the value infinity).
The results for higher moments follow from Hölder's inequality, which implies that higher moments (or halves of moments) diverge if lower ones do.
Estimation of parameters
Because the parameters of the Cauchy distribution don't correspond to a mean and variance, attempting to estimate the parameters of the Cauchy distribution by using a sample mean and a sample variance will not succeed. For example, if n samples are taken from a Cauchy distribution, one may calculate the sample mean as:
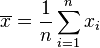
Although the sample values xi will be concentrated about the central value x0, the sample mean will become increasingly variable as more samples are taken, because of the increased likelihood of encountering sample points with a large absolute value. In fact, the distribution of the sample mean will be equal to the distribution of the samples themselves; i.e., the sample mean of a large sample is no better (or worse) an estimator of x0 than any single observation from the sample. Similarly, calculating the sample variance will result in values that grow larger as more samples are taken.
Therefore, more robust means of estimating the central value x0 and the scaling parameter γ are needed. One simple method is to take the median value of the sample as an estimator of x0 and half the sample interquartile range as an estimator of γ. Other, more precise and robust methods have been developed [8][9] For example, the truncated mean of the middle 24% of the sample order statistics produces an estimate for x0 that is more efficient than using either the sample median or the full sample mean.[10][11] However, because of the fat tails of the Cauchy distribution, the efficiency of the estimator decreases if more than 24% of the sample is used.[10][11]
Maximum likelihood can also be used to estimate the parameters x0 and γ. However, this tends to be complicated by the fact that this requires finding the roots of a high degree polynomial, and there can be multiple roots that represent local maxima.[12] Also, while the maximum likelihood estimator is asymptotically efficient, it is relatively inefficient for small samples.[13] The log-likelihood function for the Cauchy distribution for sample size n is:
![{\hat \ell }(\!x_{0},\gamma |\,x_{1},\dotsc ,x_{n})=n\log(\gamma )-\sum _{{i=1}}^{n}(\log[(\gamma )^{2}+(x_{i}-\!x_{0})^{2}])-n\log(\pi )](/2014-wikipedia_en_all_02_2014/I/media/e/8/d/e/e8de07a970c3f9a135054cd705f8b050.png)
Maximizing the log likelihood function with respect to x0 and γ produces the following system of equations:
![\sum _{{i=1}}^{n}{\frac {x_{i}-x_{0}}{\gamma ^{2}+[x_{i}-\!x_{0}]^{2}}}=0](/2014-wikipedia_en_all_02_2014/I/media/f/9/d/3/f9d3f417b0e37c62f1dade8fcb5e6463.png)
![\sum _{{i=1}}^{n}{\frac {\gamma ^{2}}{\gamma ^{2}+[x_{i}-x_{0}]^{2}}}-{\frac {n}{2}}=0](/2014-wikipedia_en_all_02_2014/I/media/4/3/9/5/439528d9d285178b25092ec35e51efa7.png)
Note that
![\sum _{{i=1}}^{n}{\frac {\gamma ^{2}}{\gamma ^{2}+[x_{i}-x_{0}]^{2}}}](/2014-wikipedia_en_all_02_2014/I/media/5/3/7/9/5379b84964f3df75dc62a00e76bb9706.png)
is a monotone function in γ and that the solution γ must satisfy
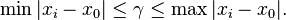
Solving just for x0 requires solving a polynomial of degree 2n−1,[12] and solving just for γ requires solving a polynomial of degree n (first for γ2, then x0). Therefore, whether solving for one parameter or for both parameters simultaneously, a numerical solution on a computer is typically required. The benefit of maximum likelihood estimation is asymptotic efficiency; estimating x0 using the sample median is only about 81% as asymptotically efficient as estimating x0 by maximum likelihood.[11][14] The truncated sample mean using the middle 24% order statistics is about 88% as asymptotically efficient an estimator of x0 as the maximum likelihood estimate.[11] When Newton's method is used to find the solution for the maximum likelihood estimate, the middle 24% order statistics can be used as an initial solution for x0.
Circular Cauchy distribution
If X is Cauchy distributed with median μ and scale parameter γ, then the complex variable
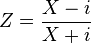
has unit modulus and is distributed on the unit circle with density:
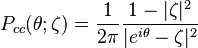
with respect to the angular variable θ = arg(z),[citation needed] where
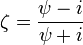
and ψ expresses the two parameters of the associated linear Cauchy distribution for x as a complex number:
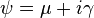
The distribution 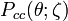 is called the circular Cauchy distribution[15][16](also the complex Cauchy distribution)[citation needed] with parameter ζ. The circular Cauchy distribution is related to the wrapped Cauchy distribution. If
is called the circular Cauchy distribution[15][16](also the complex Cauchy distribution)[citation needed] with parameter ζ. The circular Cauchy distribution is related to the wrapped Cauchy distribution. If 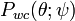 is a wrapped Cauchy distribution with the parameter ψ = μ + i γ representing the parameters of the corresponding "unwrapped" Cauchy distribution in the variable y where θ = y mod 2π, then
is a wrapped Cauchy distribution with the parameter ψ = μ + i γ representing the parameters of the corresponding "unwrapped" Cauchy distribution in the variable y where θ = y mod 2π, then
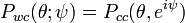
See also McCullagh's parametrization of the Cauchy distributions and Poisson kernel for related concepts.
The circular Cauchy distribution expressed in complex form has finite moments of all orders
![\operatorname {E}[Z^{r}]=\zeta ^{r},\quad \operatorname {E}[{\bar Z}^{r}]={\bar \zeta }^{r}](/2014-wikipedia_en_all_02_2014/I/media/3/5/4/6/3546346d4e98cf4cd233588bad7f5229.png)
for integer r ≥ 1. For |φ| < 1, the transformation
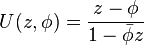
is holomorphic on the unit disk, and the transformed variable U(Z, φ) is distributed as complex Cauchy with parameter U(ζ, φ).
Given a sample z1, ..., zn of size n > 2, the maximum-likelihood equation

can be solved by a simple fixed-point iteration:
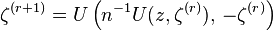
starting with ζ(0) = 0. The sequence of likelihood values is non-decreasing, and the solution is unique for samples containing at least three distinct values.[17]
The maximum-likelihood estimate for the median (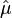 ) and scale parameter (
) and scale parameter (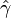 ) of a real Cauchy sample is obtained by the inverse transformation:
) of a real Cauchy sample is obtained by the inverse transformation:
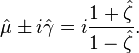
For n ≤ 4, closed-form expressions are known for 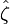 .[12] The density of the maximum-likelihood estimator at t in the unit disk is necessarily of the form:
.[12] The density of the maximum-likelihood estimator at t in the unit disk is necessarily of the form:

where
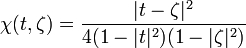 .
.
Formulae for p3 and p4 are available.[18]
Multivariate Cauchy distribution
A random vector X = (X1, ..., Xk)′ is said to have the multivariate Cauchy distribution if every linear combination of its components Y = a1X1 + ... + akXk has a Cauchy distribution. That is, for any constant vector a ∈ Rk, the random variable Y = a′X should have a univariate Cauchy distribution.[19] The characteristic function of a multivariate Cauchy distribution is given by:
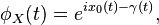
where x0(t) and γ(t) are real functions with x0(t) a homogeneous function of degree one and γ(t) a positive homogeneous function of degree one.[19] More formally:[19]
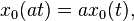
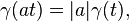
for all t.
An example of a bivariate Cauchy distribution can be given by:[20]
![f(x,y;x_{0},y_{0},\gamma )={1 \over 2\pi }\left[{\gamma \over ((x-x_{0})^{2}+(y-y_{0})^{2}+\gamma ^{2})^{{1.5}}}\right].](/2014-wikipedia_en_all_02_2014/I/media/7/e/e/9/7ee9d5b76f686bc1c3ac135943c44359.png)
Note that in this example, even though there is no analogue to a covariance matrix, x and y are not statistically independent.[20]
Analogously to the univariate density, the multidimensional Cauchy density also relates to the multivariate Student distribution. They are equivalent when the degrees of freedom parameter is equal to one. The density of a k dimension Student distribution with one degree of freedom becomes:
![f({{\mathbf x}};{{\mathbf \mu }},{{\mathbf \Sigma }},k)={\frac {\Gamma \left({\frac {1+k}{2}}\right)}{\Gamma ({\frac {1}{2}})\pi ^{{{\frac {k}{2}}}}\left|{{\mathbf \Sigma }}\right|^{{{\frac {1}{2}}}}\left[1+({{\mathbf x}}-{{\mathbf \mu }})^{T}{{\mathbf \Sigma }}^{{-1}}({{\mathbf x}}-{{\mathbf \mu }})\right]^{{{\frac {1+k}{2}}}}}}.](/2014-wikipedia_en_all_02_2014/I/media/4/7/8/4/4784ed77cbd5567f504c760a7a476aa7.png)
Properties and details for this density can be obtained by taking it as a particular case of the multivariate Student density.
Transformation properties
- If
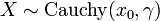 then
then 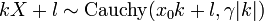
- If
 and
and  are independent, then[citation needed]
are independent, then[citation needed] 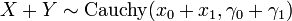
- If
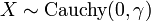 then
then 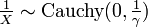
- McCullagh's parametrization of the Cauchy distributions:[citation needed] Expressing a Cauchy distribution in terms of one complex parameter
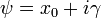 , define X ~ Cauchy(ψ) to mean X ~ Cauchy
, define X ~ Cauchy(ψ) to mean X ~ Cauchy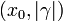 . If X ~ Cauchy(ψ) then:
. If X ~ Cauchy(ψ) then:
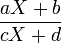 ~ Cauchy
~ Cauchy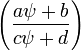
where a,b,c and d are real numbers.
- Using the same convention as above, if X ~ Cauchy(ψ) then:[citation needed]
 ~ CCauchy
~ CCauchy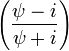
- where "CCauchy" is the circular Cauchy distribution.
Related distributions
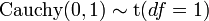 Student's t distribution
Student's t distribution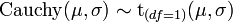 Non-standardized Student's t distribution
Non-standardized Student's t distribution- If
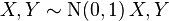 independent, then
independent, then 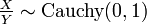
- If
 then
then 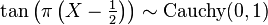
- If X ~ Log-Cauchy(0, 1) then ln(X) ~ Cauchy(0, 1)
- The Cauchy distribution is a limiting case of a Pearson distribution of type 4[citation needed]
- The Cauchy distribution is a special case of a Pearson distribution of type 7.[1]
- The Cauchy distribution is a stable distribution: if X ~ Stable(1, 0, γ, μ), then X ~ Cauchy(μ, γ).
- The Cauchy distribution is a singular limit of a Hyperbolic distribution[citation needed]
- The wrapped Cauchy distribution, taking values on a circle, is derived from the Cauchy distribution by wrapping it around the circle.
Relativistic Breit–Wigner distribution
In nuclear and particle physics, the energy profile of a resonance is described by the relativistic Breit–Wigner distribution, while the Cauchy distribution is the (non-relativistic) Breit–Wigner distribution.[citation needed]
See also
References
- ↑ 1.0 1.1 N. L. Johnson, S. Kotz, and N. Balakrishnan (1994). Continuous Univariate Distributions, Volume 1. New York: Wiley., Chapter 16.
- ↑ http://webphysics.davidson.edu/Projects/AnAntonelli/node5.html Note that the intensity, which follows the Cauchy distribution, is the square of the amplitude.
- ↑ E. Hecht (1987). Optics (2nd ed.). Addison-Wesley. p. 603.
- ↑ Park, Sung Y.; Bera, Anil K. (2009). "Maximum entropy autoregressive conditional heteroskedasticity model". Journal of Econometrics (Elsevier): 219–230. Retrieved 2011-06-02.
- ↑ Vasicek, Oldrich (1976). "A Test for Normality Based on Sample Entropy". Journal of the Royal Statistical Society, Series B 38 (1): 54–59.
- ↑ S.Kotz et al (2006). Encyclopedia of Statistical Sciences (2nd ed.). John Wiley & Sons. p. 778. ISBN 978-0-471-15044-2.
- ↑ F. B. Knight (1976). "A characterization of the Cauchy type". Proceedings of the American Mathematical Society 55: 130–135.
- ↑ Cane, Gwenda J. (1974). "Linear Estimation of Parameters of the Cauchy Distribution Based on Sample Quantiles". Journal of the American Statistical Association 69 (345): 243–245. JSTOR 2285535.
- ↑ Zhang, Jin (2010). "A Highly Efficient L-estimator for the Location Parameter of the Cauchy Distribution". Computational Statistics 25 (1): 97–105.
- ↑ 10.0 10.1 Rothenberg, Thomas J.; Fisher, Franklin, M.; Tilanus, C.B. (1966). "A note on estimation from a Cauchy sample". Journal of the American Statistical Association 59 (306): 460–463.
- ↑ 11.0 11.1 11.2 11.3 Bloch, Daniel (1966). "A note on the estimation of the location parameters of the Cauchy distribution". Journal of the American Statistical Association 61 (316): 852–855. JSTOR 2282794.
- ↑ 12.0 12.1 12.2 Ferguson, Thomas S. (1978). "Maximum Likelihood Estimates of the Parameters of the Cauchy Distribution for Samples of Size 3 and 4". Journal of the American Statistical Association 73 (361): 211. JSTOR 2286549.
- ↑ Cohen Freue, Gabriella V. (2007). "The Pitman estimator of the Cauchy location parameter". Journal of Statistical Planning and Inference 137: 1901.
- ↑ Barnett, V. D. (1966). "Order Statistics Estimators of the Location of the Cauchy Distribution". Journal of the American Statistical Association 61 (316): 1205. JSTOR 2283210.
- ↑ McCullagh, P., "Conditional inference and Cauchy models", Biometrika, volume 79 (1992), pages 247–259. PDF from McCullagh's homepage.
- ↑ K.V. Mardia (1972). Statistics of Directional Data. Academic Press.
- ↑ J. Copas (1975). "On the unimodality of the likelihood function for the Cauchy distribution". Biometrika 62: 701–704.
- ↑ P. McCullagh (1996). "Möbius transformation and Cauchy parameter estimation.". Annals of Statistics 24: 786–808. JSTOR 2242674.
- ↑ 19.0 19.1 19.2 Ferguson, Thomas S. (1962). "A Representation of the Symmetric Bivariate Cauchy Distribution". Journal of the American Statistical Association: 1256. JSTOR 2237984.
- ↑ 20.0 20.1 Molenberghs, Geert; Lesaffre, Emmanuel (1997). "Non-linear Integral Equations to Approximate Bivariate Densities with Given Marginals and Dependence Function". Statistica Sinica 7: 713–738.
External links
- Hazewinkel, Michiel, ed. (2001), "Cauchy distribution", Encyclopedia of Mathematics, Springer, ISBN 978-1-55608-010-4
- Earliest Uses: The entry on Cauchy distribution has some historical information.
- Weisstein, Eric W., "Cauchy Distribution", MathWorld.
- GNU Scientific Library – Reference Manual
| |||||||||||