Bra–ket notation
In quantum mechanics, bra–ket notation is a standard notation for describing quantum states, composed of angle brackets and vertical bars. It can also be used to denote abstract vectors and linear functionals in mathematics. It is so called because the inner product (or dot product on a complex vector space) of two states is denoted by a ⟨bra|ket⟩,
 ,
,
consisting of a left part, ⟨φ|, called the bra /brɑː/, and a right part, |ψ⟩, called the ket /kɛt/. The notation was introduced in 1939 by Paul Dirac[1] and is also known as Dirac notation, though the notation has precursors in Grassmann's use of the notation [φ|ψ] for his inner products nearly 100 years previously.[2][3]
Bra–ket notation is widespread in quantum mechanics: almost every phenomenon that is explained using quantum mechanics—including a large portion of modern physics — is usually explained with the help of bra–ket notation. Part of the appeal of the notation is the abstract representation-independence it encodes, together with its versatility in producing a specific representation (e.g. x, or p, or eigenfunction base) without much ado, or excessive reliance on the nature of the linear spaces involved. The overlap expression ⟨φ|ψ⟩ is typically interpreted as the probability amplitude for the state ψ to collapse into the state ϕ.
Vector spaces
Background: Vector spaces
In physics, basis vectors allow any Euclidean vector to be represented geometrically using angles and lengths, in different directions, i.e. in terms of the spatial orientations. It is simpler to see the notational equivalences between ordinary notation and bra–ket notation; so, for now, consider a vector A starting at the origin and ending at an element of 3-d Euclidean space; the vector then is specified by this end-point, a triplet of elements in the field of real numbers, symbolically dubbed as A ∈ ℝ3.
The vector A can be written using any set of basis vectors and corresponding coordinate system. Informally basis vectors are like "building blocks of a vector": they are added together to compose a vector, and the coordinates are the numerical coefficients of basis vectors in each direction. Two useful representations of a vector are simply a linear combination of basis vectors, and column matrices. Using the familiar Cartesian basis, a vector A may be written as


respectively, where ex, ey, ez denotes the Cartesian basis vectors (all are orthogonal unit vectors) and Ax, Ay, Az are the corresponding coordinates, in the x, y, z directions. In a more general notation, for any basis in 3-d space one writes
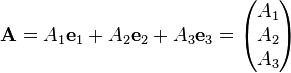
Generalizing further, consider a vector A in an N dimensional vector space over the field of complex numbers ℂ, symbolically stated as A ∈ ℂN. The vector A is still conventionally represented by a linear combination of basis vectors or a column matrix:

though the coordinates are now all complex-valued.
Even more generally, A can be a vector in a complex Hilbert space. Some Hilbert spaces, like ℂN, have finite dimension, while others have infinite dimension. In an infinite-dimensional space, the column-vector representation of A would be a list of infinitely many complex numbers.
Ket notation for vectors
Rather than boldtype, over arrows, underscores etc. conventionally used elsewhere;  , Dirac's notation for a vector uses vertical bars and angular brackets: |A⟩. When this notation is used, these vectors are called "ket", read as "ket-A".[4] This applies to all vectors, the resultant vector and the basis. The previous vectors are now written
, Dirac's notation for a vector uses vertical bars and angular brackets: |A⟩. When this notation is used, these vectors are called "ket", read as "ket-A".[4] This applies to all vectors, the resultant vector and the basis. The previous vectors are now written
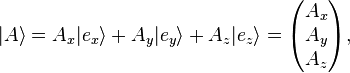
or in a more easily generalized notation,
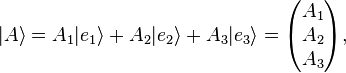
The last one may be written in short as
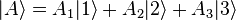
Notice how any symbols, letters, numbers, or even words — whatever serves as a convenient label — can be used as the label inside a ket. In other words, the symbol |A⟩ has a specific and universal mathematical meaning, but just the "A" by itself does not. Nevertheless, for convenience, there is usually some logical scheme behind the labels inside kets, such as the common practice of labeling energy eigenkets in quantum mechanics with a list of their quantum numbers.
Inner products and bras
An inner product is a generalization of the dot product. The inner product of two vectors is a complex number. Bra–ket notation uses a specific notation for inner products:
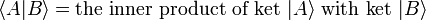
For example, in three-dimensional complex Euclidean space,
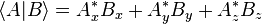
where 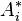 denotes the complex conjugate of Ai. A special case is the inner product of a vector with itself, which is the square of its norm (magnitude):
denotes the complex conjugate of Ai. A special case is the inner product of a vector with itself, which is the square of its norm (magnitude):

Bra–ket notation splits this inner product (also called a "bracket") into two pieces, the "bra" and the "ket":
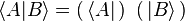
where ⟨A| is called a bra, read as "bra-A", and |B⟩ is a ket as above.
The purpose of "splitting" the inner product into a bra and a ket is that both the bra ⟨A| and the ket |B⟩ are meaningful on their own, and can be used in other contexts besides within an inner product. There are two main ways to think about the meanings of separate bras and kets:
Bras and kets as row and column vectors
For a finite-dimensional vector space, using a fixed orthonormal basis, the inner product can be written as a matrix multiplication of a row vector with a column vector:
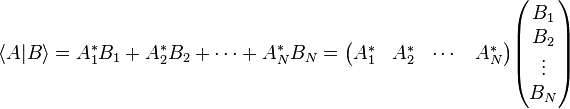
Based on this, the bras and kets can be defined as:
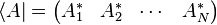

and then it is understood that a bra next to a ket implies matrix multiplication.
The conjugate transpose (also called Hermitian conjugate) of a bra is the corresponding ket and vice versa:
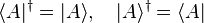
because if one starts with the bra
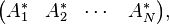
then performs a complex conjugation, and then a matrix transpose, one ends up with the ket
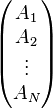
Bras as linear operators on kets
A more abstract definition, which is equivalent but more easily generalized to infinite-dimensional spaces, is to say that bras are linear functionals on kets, i.e. operators that input a ket and output a complex number. The bra operators are defined to be consistent with the inner product.
In mathematics terminology, the vector space of bras is the dual space to the vector space of kets, and corresponding bras and kets are related by the Riesz representation theorem.
Non-normalizable states and non-Hilbert spaces
Bra–ket notation can be used even if the vector space is not a Hilbert space.
In quantum mechanics, it is common practice to write down kets which have infinite norm, i.e. non-normalisable wavefunctions. Examples include states whose wavefunctions are Dirac delta functions or infinite plane waves. These do not, technically, belong to the Hilbert space itself. However, the definition of "Hilbert space" can be broadened to accommodate these states (see the Gelfand–Naimark–Segal construction or rigged Hilbert spaces). The bra–ket notation continues to work in an analogous way in this broader context.
For a rigorous treatment of the Dirac inner product of non-normalizable states, see the definition given by D. Carfì.[5][6] For a rigorous definition of basis with a continuous set of indices and consequently for a rigorous definition of position and momentum basis, see.[7] For a rigorous statement of the expansion of an S-diagonalizable operator, or observable, in its eigenbasis or in another basis, see.[8]
Banach spaces are a different generalization of Hilbert spaces. In a Banach space B, the vectors may be notated by kets and the continuous linear functionals by bras. Over any vector space without topology, we may also notate the vectors by kets and the linear functionals by bras. In these more general contexts, the bracket does not have the meaning of an inner product, because the Riesz representation theorem does not apply.
Usage in quantum mechanics
The mathematical structure of quantum mechanics is based in large part on linear algebra:
- Wave functions and other quantum states can be represented as vectors in a complex Hilbert space. (The exact structure of this Hilbert space depends on the situation.) In bra–ket notation, for example, an electron might be in the "state" |ψ⟩. (Technically, the quantum states are rays of vectors in the Hilbert space, as c|ψ⟩ corresponds to the same state for any nonzero complex number c.)
- Quantum superpositions can be described as vector sums of the constituent states. For example, an electron in the state |1⟩+i |2⟩ is in a quantum superposition of the states |1⟩ and |2⟩.
- Measurements are associated with linear operators (called observables) on the Hilbert space of quantum states.
- Dynamics are also described by linear operators on the Hilbert space. For example, in the Schrödinger picture, there is a linear time evolution operator U with the property that if an electron is in state |ψ⟩ right now, then in one second it will be in the state U|ψ⟩, the same U for every possible |ψ⟩.
- Wave function normalization is scaling a wave function so that its norm is 1.
Since virtually every calculation in quantum mechanics involves vectors and linear operators, it can involve, and often does involve, bra–ket notation. A few examples follow:
Spinless position–space wave function


The Hilbert space of a spin-0 point particle is spanned by a "position basis"  , where the label r extends over the set of all points in position space. Since there are uncountably infinitely many vectors in the basis, this is an uncountably infinite-dimensional Hilbert space. The dimensions of the Hilbert space (usually infinite) and position space (usually 1, 2 or 3) are not to be conflated.
, where the label r extends over the set of all points in position space. Since there are uncountably infinitely many vectors in the basis, this is an uncountably infinite-dimensional Hilbert space. The dimensions of the Hilbert space (usually infinite) and position space (usually 1, 2 or 3) are not to be conflated.
Starting from any ket |Ψ⟩ in this Hilbert space, we can define a complex scalar function of r, known as a wavefunction:
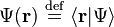 .
.
On the left side, Ψ(r) is a function mapping any point in space to a complex number; on the right side, |Ψ⟩ = ∫d3r Ψ(r) |r⟩ is a ket.
It is then customary to define linear operators acting on wavefunctions in terms of linear operators acting on kets, by
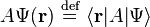 .
.
For instance, the momentum operator p has the following form,
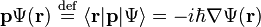 .
.
One occasionally encounters a sloppy expression like
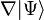 ,
,
though this is something of a (common) abuse of notation. The differential operator must be understood to be an abstract operator, acting on kets, that has the effect of differentiating wavefunctions once the expression is projected into the position basis,
 ,
,
even though, in the momentum basis, the operator amounts to a mere multiplication operator (by iħp).
Overlap of states
In quantum mechanics the expression ⟨φ|ψ⟩ is typically interpreted as the probability amplitude for the state ψ to collapse into the state φ. Mathematically, this means the coefficient for the projection of ψ onto φ. It is also described as the projection of state ψ onto state φ.
Changing basis for a spin-1/2 particle
A stationary spin-½ particle has a two-dimensional Hilbert space. One orthonormal basis is:

where  is the state with a definite value of the spin operator Sz equal to +1/2 and
is the state with a definite value of the spin operator Sz equal to +1/2 and 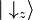 is the state with a definite value of the spin operator Sz equal to −1/2.
is the state with a definite value of the spin operator Sz equal to −1/2.
Since these are a basis, any quantum state of the particle can be expressed as a linear combination (i.e., quantum superposition) of these two states:
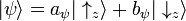
where aψ, bψ are complex numbers.
A different basis for the same Hilbert space is:
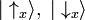
defined in terms of Sx rather than Sz.
Again, any state of the particle can be expressed as a linear combination of these two:
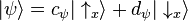
In vector form, you might write

depending on which basis you are using. In other words, the "coordinates" of a vector depend on the basis used.
There is a mathematical relationship between aψ, bψ,cψ, dψ; see change of basis.
Misleading uses
There are a few conventions and abuses of notation that are generally accepted by the physics community, but which might confuse the non-initiated.
It is common among physicists to use the same symbol for labels and constants in the same equation. It supposedly becomes easier to identify that the constant is related to the labeled object, and is claimed that the divergent nature of each will eliminate any ambiguity and no further differentiation is required. For example, α̂|α⟩= α|α⟩, where the symbol α is used simultaneously as the name of the operator α̂, its eigenvector |α⟩ and the associated eigenvalue α.
Something similar occurs in component notation of vectors. While Ψ (uppercase) is traditionally associated with wavefunctions, ψ (lowercase) may be used to denote a label, a wave function or complex constant in the same context, usually differentiated only by a subscript.
The main abuses are including operations inside the vector labels. This is usually done for a fast notation of scaling vectors. E.g. if the vector |α⟩ is scaled by 1/√2, it might be denoted by 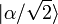 , which makes no sense since α is a label, not a function or a number, so you can't perform operations on it.
, which makes no sense since α is a label, not a function or a number, so you can't perform operations on it.
This is especially common when denoting vectors as tensor products, where part of the labels are moved outside the designed slot. E.g. 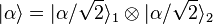 . Here
part of the labeling that should state that all three vectors are different was moved outside the kets, as subscripts 1 and 2. And a further abuse occurs, since α is meant to refer to the norm of the first vector – which is a label is denoting a value.
. Here
part of the labeling that should state that all three vectors are different was moved outside the kets, as subscripts 1 and 2. And a further abuse occurs, since α is meant to refer to the norm of the first vector – which is a label is denoting a value.
Linear operators
Linear operators acting on kets
A linear operator is a map that inputs a ket and outputs a ket. (In order to be called "linear", it is required to have certain properties.) In other words, if A is a linear operator and |ψ⟩ is a ket, then A|ψ⟩ is another ket.
In an N-dimensional Hilbert space, |ψ⟩ can be written as an N×1 column vector, and then A is an N×N matrix with complex entries. The ket A|ψ⟩ can be computed by normal matrix multiplication.
Linear operators are ubiquitous in the theory of quantum mechanics. For example, observable physical quantities are represented by self-adjoint operators, such as energy or momentum, whereas transformative processes are represented by unitary linear operators such as rotation or the progression of time.
Linear operators acting on bras
Operators can also be viewed as acting on bras from the right hand side. Specifically, if A is a linear operator and ⟨φ| is a bra, then ⟨φ|A is another bra defined by the rule
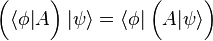 ,
,
(in other words, a function composition). This expression is commonly written as (cf. energy inner product)
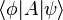 .
.
In an N-dimensional Hilbert space, ⟨φ| can be written as a 1×N row vector, and A (as in the previous section) is an N×N matrix. Then the bra ⟨φ|A can be computed by normal matrix multiplication.
If the same state vector appears on both bra and ket side,
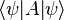 ,
,
then this expression gives the expectation value, or mean or average value, of the observable represented by operator A for the physical system in the state |ψ⟩.
Outer products
A convenient way to define linear operators on H is given by the outer product: if ⟨φ| is a bra and |ψ⟩ is a ket, the outer product
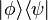
denotes the rank-one operator that maps the ket |ρ⟩ to the ket |φ⟩⟨ψ|ρ⟩ (where ⟨ψ|ρ⟩ is a scalar multiplying the vector |φ⟩).
For a finite-dimensional vector space, the outer product can be understood as simple matrix multiplication:

The outer product is an N×N matrix, as expected for a linear operator.
One of the uses of the outer product is to construct projection operators. Given a ket |ψ⟩ of norm 1, the orthogonal projection onto the subspace spanned by |ψ⟩ is

Hermitian conjugate operator
Just as kets and bras can be transformed into each other (making  into
into  ) the element from the dual space corresponding with
) the element from the dual space corresponding with  is
is 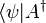 where A† denotes the Hermitian conjugate (or adjoint) of the operator A. In other words,
where A† denotes the Hermitian conjugate (or adjoint) of the operator A. In other words,
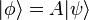 if and only if
if and only if 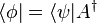 .
.
If A is expressed as an N×N matrix, then A† is its conjugate transpose.
Self-adjoint operators, where A=A†, play an important role in quantum mechanics; for example, an observable is always described by a self-adjoint operator. If A is a self-adjoint operator, then is always a real number (not complex). This implies that expectation values of observables are real.
Properties
Bra–ket notation was designed to facilitate the formal manipulation of linear-algebraic expressions. Some of the properties that allow this manipulation are listed herein. In what follows, c1 and c2 denote arbitrary complex numbers, c* denotes the complex conjugate of c, A and B denote arbitrary linear operators, and these properties are to hold for any choice of bras and kets.
Linearity
- Since bras are linear functionals,

- By the definition of addition and scalar multiplication of linear functionals in the dual space,[9]
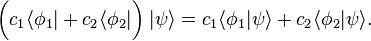
Associativity
Given any expression involving complex numbers, bras, kets, inner products, outer products, and/or linear operators (but not addition), written in bra–ket notation, the parenthetical groupings do not matter (i.e., the associative property holds). For example:

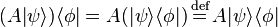
and so forth. The expressions on the right (with no parentheses whatsoever) are allowed to be written unambiguously because of the equalities on the left. Note that the associative property does not hold for expressions that include non-linear operators, such as the antilinear time reversal operator in physics.
Hermitian conjugation
Bra–ket notation makes it particularly easy to compute the Hermitian conjugate (also called dagger, and denoted †) of expressions. The formal rules are:
- The Hermitian conjugate of a bra is the corresponding ket, and vice-versa.
- The Hermitian conjugate of a complex number is its complex conjugate.
- The Hermitian conjugate of the Hermitian conjugate of anything (linear operators, bras, kets, numbers) is itself—i.e.,
- (x†)† = x.
- Given any combination of complex numbers, bras, kets, inner products, outer products, and/or linear operators, written in bra–ket notation, its Hermitian conjugate can be computed by reversing the order of the components, and taking the Hermitian conjugate of each.
These rules are sufficient to formally write the Hermitian conjugate of any such expression; some examples are as follows:
- Kets:
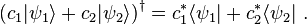
- Inner products:
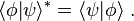
- Matrix elements:

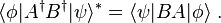
- Outer products:
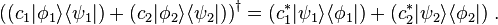
Composite bras and kets
Two Hilbert spaces V and W may form a third space V⊗W by a tensor product. In quantum mechanics, this is used for describing composite systems. If a system is composed of two subsystems described in V and W respectively, then the Hilbert space of the entire system is the tensor product of the two spaces. (The exception to this is if the subsystems are actually identical particles. In that case, the situation is a little more complicated.)
If |ψ⟩ is a ket in V and |φ⟩ is a ket in W, the direct product of the two kets is a ket in V⊗W. This is written in various notations:

See quantum entanglement and the EPR paradox for applications of this product.
The unit operator
Consider a complete orthonormal system (basis),  , for a Hilbert space H, with respect to the norm from an inner product
, for a Hilbert space H, with respect to the norm from an inner product  . From basic functional analysis we know that any ket |ψ⟩ can also be written as
. From basic functional analysis we know that any ket |ψ⟩ can also be written as
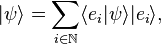
with 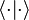 the inner product on the Hilbert space.
the inner product on the Hilbert space.
From the commutativity of kets with (complex) scalars now follows that
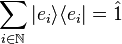
must be the identity operator, which sends each vector to itself. This can be inserted in any expression without affecting its value, for example
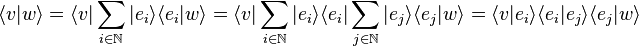 ,
,
where, in the last identity, the Einstein summation convention has been used.
In quantum mechanics, it often occurs that little or no information about the inner product  of two arbitrary (state) kets is present, while it is still possible to say something about the expansion coefficients
of two arbitrary (state) kets is present, while it is still possible to say something about the expansion coefficients  and
and  of those vectors with respect to a specific (orthonormalized) basis. In this case, it is particularly useful to insert the unit operator into the bracket one time or more.
of those vectors with respect to a specific (orthonormalized) basis. In this case, it is particularly useful to insert the unit operator into the bracket one time or more.
For more information, see Resolution of the identity, 1 = ∫dx |x⟩⟨x| = ∫dp |p⟩⟨p|, where |p⟩ = ∫dx eixp/ħ|x⟩/√2πħ; since ⟨x' |x⟩= δ(x − x' ), plane waves follow, ⟨x|p⟩= exp(ixp/ħ)/√2πħ.
Notation used by mathematicians
The object physicists are considering when using the "bra–ket" notation is a Hilbert space (a complete inner product space).
Let 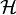 be a Hilbert space and
be a Hilbert space and 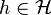 is a vector in . What physicists would denote as |h⟩ is the vector itself. That is
is a vector in . What physicists would denote as |h⟩ is the vector itself. That is
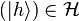 .
.
Let 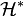 be the dual space of . This is the space of linear functionals on . The isomorphism
be the dual space of . This is the space of linear functionals on . The isomorphism 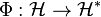 is defined by
is defined by 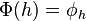 where for all
where for all 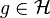 we have
we have
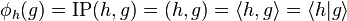 ,
,
where 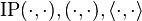 and
are just different notations for expressing an inner product between two elements in a Hilbert space (or for the first three, in any inner product space). Notational confusion arises when identifying
and
are just different notations for expressing an inner product between two elements in a Hilbert space (or for the first three, in any inner product space). Notational confusion arises when identifying  and
and 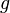 with
with 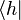 and
and  respectively. This is because of literal symbolic substitutions. Let
respectively. This is because of literal symbolic substitutions. Let 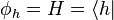 and let
and let 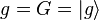 . This gives
. This gives
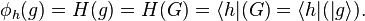
One ignores the parentheses and removes the double bars. Some properties of this notation are convenient since we are dealing with linear operators and composition acts like a ring multiplication.
Moreover, mathematicians usually write the dual entity not at the first place, as the physicists do, but at the second one, and they don't use the *-symbol, but an overline (which the physicists reserve for averages and Dirac conjugation) to denote conjugate-complex numbers, i.e. for scalar products mathematicians usually write

whereas physicists would write for the same quantity
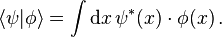
See also
References and notes
- ↑ PAM Dirac (1939). "A new notation for quantum mechanics". Mathematical Proceedings of the Cambridge Philosophical Society 35 (3). pp. 416–418. doi:10.1017/S0305004100021162.
- ↑ H. Grassmann (1862). Extension Theory. History of Mathematics Sources. American Mathematical Society, London Mathematical Society, 2000 translation by Lloyd C. Kannenberg.
- ↑ Cajori, Florian (1929). A History Of Mathematical Notations Volume II. Open Court Publishing. p. 134. ISBN 978-0-486-67766-8
- ↑ Quantum Mechanics Demystified, D. McMahon, Mc Graw Hill (USA), 2006, ISBN(10-) 0-07-145546 9
- ↑ Carfì, David (April 2003). "Dirac-orthogonality in the space of tempered distributions". Journal of Computational and Applied Mathematics 153 (1–2): 99–107. Bibcode:2003JCoAM.153...99C. doi:10.1016/S0377-0427(02)00634-9.
- ↑ Carfì, David (April 2003). "Some properties of a new product in the space of tempered distributions". Journal of Computational and Applied Mathematics 153 (1–2): 109–118. Bibcode:2003JCoAM.153..109C. doi:10.1016/S0377-0427(02)00635-0.
- ↑ Carfì, David (2007). "TOPOLOGICAL CHARACTERIZATIONS OF S-LINEARITY". AAPP-PHYSICAL, MATHEMATICAL AND NATURAL SCIENCES 85 (2): 1–16. doi:10.1478/C1A0702005.
- ↑ Carfì, David (2005). "S-DIAGONALIZABLE OPERATORS IN QUANTUM MECHANICS". Glasnik Matematicki 40 (2): 261–301. doi:10.3336/gm.40.2.08.
- ↑ Lecture notes by Robert Littlejohn, eqns 12 and 13
Further reading
- Feynman, Leighton and Sands (1965). The Feynman Lectures on Physics Vol. III. Addison-Wesley. ISBN 0-201-02115-3.
External links
- Richard Fitzpatrick, "Quantum Mechanics: A graduate level course", The University of Texas at Austin.
- 1. Ket space
- 2. Bra space
- 3. Operators
- 4. The outer product
- 5. Eigenvalues and eigenvectors
- Robert Littlejohn, Lecture notes on "The Mathematical Formalism of Quantum mechanics", including bra–ket notation.