Binary lambda calculus
Binary lambda calculus (BLC) is a technique for using the lambda calculus to study Kolmogorov complexity, by working with a standard binary encoding of lambda terms, and a designated universal machine. Binary lambda calculus is a new idea introduced by John Tromp in 2004.[1]
Background
BLC is designed to provide a very simple and elegant concrete definition of descriptional complexity (Kolmogorov complexity).
Roughly speaking, the complexity of an object is the length of its shortest description.
To make this precise, we take descriptions to be bitstrings, and identify a description method with some computational device, or machine, that transforms descriptions into objects. Objects are usually also just bitstrings, but can have additional structure as well, e.g., pairs of strings.
Originally, Turing machines, the most well known formalism for computation, were used for this purpose. But they are somewhat lacking in ease of construction and composability. Another classical computational formalism, the Lambda calculus, offers distinct advantages in ease of use. The lambda calculus doesn't incorporate any notion of I/O though, so one needs to be designed.
Binary I/O
Adding a readbit primitive function to lambda calculus, as Chaitin did for LISP, would destroy its referential transparency, unless one distinguishes between an I/O action and its result, as Haskell does with its monadic I/O. But that requires a type system, an unnecessary complication.
Instead, BLC requires translating bitstrings into lambda terms, to which the machine (itself a lambda term) can be readily applied.
Bits 0 and 1 are translated into the standard lambda booleans B0 = True and B1 = False:
- True =
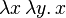
- False =
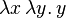
which can be seen to directly implement the if-then-else operator.
Now consider the pairing function

applied to two terms M and N
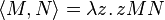 .
.
Applying this to a boolean yields the desired component of choice.
A string s = b0b1…bn−1 is represented by repeated pairing as
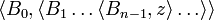 which is denoted as
which is denoted as  .
.
The z appearing in the above expression requires some further explanation.
Delimited versus undelimited
Descriptional complexity actually comes in two distinct flavors, depending on whether the input is considered to be delimited.
Knowing the end of your input makes it easier to describe objects. For instance, you can just copy the whole input to output. This flavor is called plain or simple complexity.
But in a sense it is additional information. A file system for instance needs to separately store the length of files. The C language uses the null character to denote the end of a string, but this comes at the cost of not having that character available within strings.
The other flavor is called prefix complexity, named after prefix codes, where the machine needs to figure out, from the input read so far, whether it needs to read more bits. We say that the input is self-delimiting. This works better for communication channels, since one can send multiple descriptions, one after the other, and still tell them apart.
In the I/O model of BLC, the flavor is dictated by the choice of z. If we keep it as a free variable, and demand that it appears as part of the output, then the machine must be working in a self-delimiting manner. If on the other hand we use a lambda term specifically designed to be easy to distinguish from any pairing, then the input becomes delimited. BLC chooses False for this purpose but gives it the more descriptive alternative name of Nil. Dealing with lists that may be Nil is straightforward: since
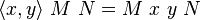 , and
, and
one can write functions M and N to deal with the two cases, the only caveat being that N will be passed to M as its third argument.
Universality
We can find a description method U such that for any other description method D, there is a constant c (depending only on D) such that no object takes more than c extra bits to describe with method U than with method D. And BLC is designed to make these constants relatively small. In fact the constant will be the length of a binary encoding of a D-interpreter written in BLC, and U will be a lambda term that parses this encoding and runs this decoded interpreter on the rest of the input. U won't even have to know whether the description is delimited or not; it works the same either way.
Having already solved the problem of translating bitstrings into lambda calculus, we now face the opposite problem: how to encode lambda terms into bitstrings?
Lambda encoding
First we need to write our lambda terms in a particular notation using what is known as De Bruijn indices. Our encoding is then defined recursively as follows
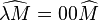
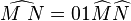
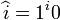
For instance, the pairing function  is written
is written 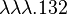 in De Bruijn format, which has encoding
in De Bruijn format, which has encoding  .
.
A closed lambda term is one in which all variables are bound, i.e. without any free variables.
In De Bruijn format, this means that an index i can only appear
within at least i nested lambdas.
The number of closed terms of size n bits is given by sequence ![]() A114852
of the On-Line Encyclopedia of Integer Sequences.
A114852
of the On-Line Encyclopedia of Integer Sequences.
The shortest possible closed term is the identity function 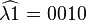 .
In delimited mode, this machine just copies its input to its output.
.
In delimited mode, this machine just copies its input to its output.
So what is this universal machine U? Here it is, in De Bruijn format (all indices are single digit):
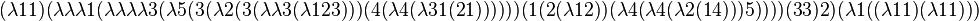
This is in binary:
- 0101000110100000000101011000000000011110000101111110011110
- 0001011100111100000011110000101101101110011111000011111000
- 0101111010011101001011001110000110110000101111100001111100
- 0011100110111101111100111101110110000110010001101000011010
- (only 232 bits long)
A detailed analysis of machine U may be found in.[1]
Complexity, concretely
In general, we can make complexity of an object conditional on several other objects that are provided as additional argument to the universal machine. Plain (or simple) complexity KS and prefix complexity KP are defined by


Theorems, concretely
The identity program  proves that
proves that

The program 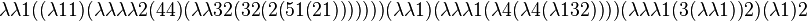 proves that
proves that
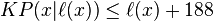
The program
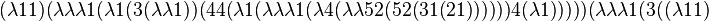
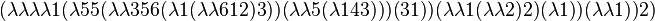
proves that

where  is the Levenstein code code for x defined by
is the Levenstein code code for x defined by

in which we identify numbers and bitstrings according to lexicographic order. This code has the nice property that for all k,
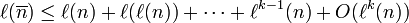
Furthermore, it makes lexicographic order of delimited numbers coincide with numeric order.
| Number | String | Delimited |
|---|---|---|
| 0 | 0 | |
| 1 | 0 | 10 |
| 2 | 1 | 110 0 |
| 3 | 00 | 110 1 |
| 4 | 01 | 1110 0 00 |
| 5 | 10 | 1110 0 01 |
| 6 | 11 | 1110 0 10 |
| 7 | 000 | 1110 0 11 |
| 8 | 001 | 1110 1 000 |
| 9 | 010 | 1110 1 001 |
Complexity of Sets
The complexity of a set of natural numbers is the complexity of its characteristic sequence, an infinite lambda term in the Infinitary Lambda Calculus.
The program
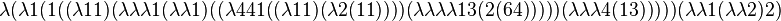
whose first 100 bits of output are

proves that
 (a prime)
(a prime)
while a simple variation proves

This is even shorter than Haskell's 23 byte long
nubBy(((>1).).gcd)[2..]
Symmetry of information
The program



proves that
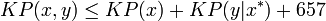
where  is a shortest program for x.
is a shortest program for x.
This inequality is the easy half of an equality (up to a constant) known as Symmetry of information. Proving the converse

involves simulating infinitely many programs in dovetailing fashion,
seeing which ones halt and output the pair of x (for which a shortest program is given) and any y,
and for each such program p, requesting a new codeword for y of length  .
The Kraft inequality ensures that this infinite enumeration of requests can be fulfilled,
and in fact codewords for y can be decoded on the fly, in tandem with the above enumeration.
Details of this fundamental result by Chaitin can be found in.[2]
.
The Kraft inequality ensures that this infinite enumeration of requests can be fulfilled,
and in fact codewords for y can be decoded on the fly, in tandem with the above enumeration.
Details of this fundamental result by Chaitin can be found in.[2]
A quine
The term 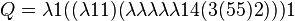 concatenates two copies of its input, proving that
concatenates two copies of its input, proving that

Applying it to its own encoding gives a 132 bit quine:

Compression
So far, we've seen surprisingly little in the way of actually compressing an object into a shorter description; in the last example, we were only breaking even.
For  though, we do actually compress
though, we do actually compress  by
by 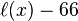 bits.
bits.
What could be the shortest program that produces a larger output?
The following is a good candidate: the program
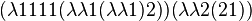 ,
of size 55 bits, uses Church numerals to output exactly
,
of size 55 bits, uses Church numerals to output exactly  ones.
That beats both gzip and bzip2, compressors that need 344 and 352 bits respectively, to describe the same output
(as a 8192 byte file with a single letter name).
ones.
That beats both gzip and bzip2, compressors that need 344 and 352 bits respectively, to describe the same output
(as a 8192 byte file with a single letter name).
Halting probability
The halting probability of the prefix universal machine is defined as the probability it will output any term that has a normal form (this includes all translated strings):

With some effort, we can determine the first 4 bits of this particular number of wisdom:

where probability .00012 = 2−4 is already contributed by programs 00100 and 00101 for terms True and False.
BLC8: byte sized I/O
While bit streams are nice in theory, they fare poorly in interfacing with the real world. The language BLC8 is a more practical variation on BLC in which programs operate on a stream of bytes, where each byte is represented as a delimited list of 8 bits in big-endian order.
BLC8 requires a more complicated universal machine:


The parser in U8 keeps track of both remaining bytes, and remaining bits in the current byte, discarding the latter when parsing is completed. Thus the size of U8, which is 355 bits as a BLC program, is 45 bytes in BLC8.
Brainfuck
The following BLC8 program


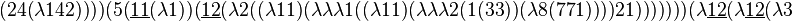
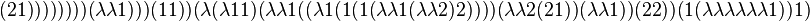
is an unbounded tape Brainfuck interpreter in 829 bits (under 104 bytes). The formatting obscures the occurrence of double digit indices: a 10 on line 1, a 15 on line 2, and an 11 and three 12s on line 3. These indices are marked with underlines to distinguish them from single digit indices.
This provides a nice example of the property that universal description methods differ by at most a constant in complexity. Writing a BLC8 interpreter in Brainfuck, which would provide a matching upper bound in the other direction, is left as an exercise for die-hard Brainfuck programmers.
The interpreter expects its input to consist of a Brainfuck program followed by a ] followed by the input for the Brainfuck program. The interpreter only looks at bits 0,1,4 of each character to determine which of ,-.+<>][ it is, so any characters other than those 8 should be stripped from a Brainfuck program.
Consuming more input than is available results in an error (the non-list result 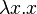 ).
).
This interpreter is a rough translation of the following version written in Haskell
import System.Environment(getArgs) import Control.Monad.State import Control.Monad.Writer import Control.Applicative hiding ((<|>),many) import Text.ParserCombinators.Parsec putc = do ( _, _,b, _) <- get; tell [b] getc = do ( left, right,_,b:input) <- get; put ( left, right, b,input) prev = do (l:left, right,b, input) <- get; put ( left,b:right, l,input) next = do ( left,r:right,b, input) <- get; put (b:left, right, r,input) decr = do ( left, right,b, input) <- get; put ( left, right,pred b,input) incr = do ( left, right,b, input) <- get; put ( left, right,succ b,input) loop body = do (_,_,b,_) <- get; when (b /= '\0') (body >> loop body) parseInstr = liftM loop (between (char '[') (char ']') parseInstrs) <|> prev <$ char '<' <|> next <$ char '>' <|> decr <$ char '-' <|> incr <$ char '+' <|> putc <$ char '.' <|> getc <$ char ',' <|> return () <$ noneOf "]" parseInstrs = liftM sequence_ (many parseInstr) main = do [name] <- getArgs source <- readFile name input <- getContents let init = ("", repeat '\0', '\0', input) putStrLn $ either show (execWriter . (`evalStateT` init)) (parse parseInstrs name source)
See also
References
- ↑ 1.0 1.1 John Tromp, Binary Lambda Calculus and Combinatory Logic, in Randomness And Complexity, from Leibniz To Chaitin, ed. Cristian S. Calude, World Scientific Publishing Company, October 2008. (The last reference, to an initial Haskell implementation, is dated 2004) (pdf version)
- ↑ G J Chaitin, Algorithmic information theory, Volume I in Cambridge Tracts in Theoretical Computer Science, Cambridge University Press, October 1987, (pdf version)
External links
- John's Lambda Calculus and Combinatory Logic Playground
- A Binary Lambda Calculus interpreter in C for the IOCCC