Binary Independence Model
The Binary Independence Model (BIM)[1][2] is a probabilistic information retrieval technique that makes some simple assumptions to make the estimation of document/query similarity probability feasible.
Definitions
The Binary Independence Assumption is that documents are binary vectors. That is, only the presence or absence of terms in documents are recorded. Terms are independently distributed in the set of relevant documents and they are also independently distributed in the set of irrelevant documents. The representation is an ordered set of Boolean variables. That is, the representation of a document or query is a vector with one Boolean element for each term under consideration. More specifically, a document is represented by a vector d = (x1, ..., xm) where xt=1 if term t is present in the document d and xt=0 if it's not. Many documents can have the same vector representation with this simplification. Queries are represented in a similar way. "Independence" signifies that terms in the document are considered independently from each other and no association between terms is modeled. This assumption is very limiting, but it has been shown that it gives good enough results for many situations. This independence is the "naive" assumption of a Naive Bayes classifier, where properties that imply each other are nonetheless treated as independent for the sake of simplicity. This assumption allows the representation to be treated as an instance of a Vector space model by considering each term as a value of 0 or 1 along a dimension orthogonal to the dimensions used for the other terms.
The probability P(R|d,q) that a document is relevant derives from the probability of relevance of the terms vector of that document P(R|x,q). By using the Bayes rule we get:
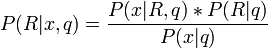
where P(x|R=1,q) and P(x|R=0,q) are the probabilities of retrieving a relevant or nonrelevant document, respectively. If so, then that document's representation is x. The exact probabilities can not be known beforehand, so use estimates from statistics about the collection of documents must be used.
P(R=1|q) and P(R=0|q) indicate the previous probability of retrieving a relevant or nonrelevant document respectively for a query q. If, for instance, we knew the percentage of relevant documents in the collection, then we could use it to estimate these probabilities. Since a document is either relevant or nonrelevant to a query we have that:
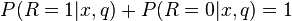
Query Terms Weighting
Given a binary query and the dot product as the similarity function
between a document and a query, the problem is to assign weights to the
terms in the query such that the retrieval effectiveness will be high. Let  and
and  be the probability that a relevant document and an irrelevant
document has the
be the probability that a relevant document and an irrelevant
document has the 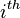 term respectively. Yu and Salton,[1] who first introduce BIM, propose that the weight of the
term is an increasing function of
term respectively. Yu and Salton,[1] who first introduce BIM, propose that the weight of the
term is an increasing function of  . Thus, if
. Thus, if 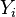 is higher than
is higher than 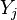 , the weight
of term
, the weight
of term  will be higher than that of term
will be higher than that of term  . Yu and Salton[1] showed that such a weight assignment to query terms yields better retrieval effectiveness than if query terms are equally weighted. Robertson and Sparck[2] later showed that if the term is assigned the weight of
. Yu and Salton[1] showed that such a weight assignment to query terms yields better retrieval effectiveness than if query terms are equally weighted. Robertson and Sparck[2] later showed that if the term is assigned the weight of  , then optimal retrieval effectiveness is obtained under the Binary Independence Assumption.
, then optimal retrieval effectiveness is obtained under the Binary Independence Assumption.
The Binary Independence Model was introduced by Yu and Salton.[1] The name Binary Independence Model was coined by Robertson and Sparck.[2]
Recent work
Wu et al.[3] proposed a new probabilistic retrieval model which weights terms according to their contexts in documents. The term weighting function they used is similar to the language model and the binary independence model.
Roelleke et al.[4] investigates the probabilistic relational implementations of BIM under the use of probabilistic relational algebra for the integration of Information Retrieval in databases. This work surges as a result of the interest shown by Surajit et al.[5] in applying the knowledge of probabilistic models for information retrieval in structured data, to investigate the problem of ranking the answers to a database query when many tuples are returned.
Zhao and Callan (2010)[6] showed a connection between , the probability of a term appearing in relevant documents, and the vocabulary mismatch problem. This leads to effective ways of predicting the probability for test queries without relevance judgments using training queries with known relevance judgments. Term weighting using this probability could potentially lead to 50-80% gain in retrieval performance over stronger baseline retrieval models such as Language Modeling with perfect estimates of the probability. Further developments following this line of idea points at the Boolean Conjunctive Normal Form expansion technique which could lead to 50-300% gain over unexpanded keyword retrieval.[7]
See also
- Bag of words model
Further reading
- Christopher D. Manning; Prabhakar Raghavan & Hinrich Schütze (2008), Introduction to Information Retrieval, Cambridge University Press
- Stefan Büttcher; Charles L. A. Clarke & Gordon V. Cormack (2010), Information Retrieval: Implementing and Evaluating Search Engines, MIT Press
References
- ↑ 1.0 1.1 1.2 1.3 Clement T. Yu, Gerard Salton: Precision Weighting - An Effective Automatic Indexing Method. J. ACM 23(1): 76-88 (1976)
- ↑ 2.0 2.1 2.2 S.E. Robertson and Sparck Jones, K.: Relevance weighting of search terms. Journal of the American Society for Information Science, 27: 129–146 (1976)
- ↑ H. C. Wu; R. W. P. Luk, K. F. Wong, K. L. Kwok, W. J. Li (2005), A retrospective study of probabilistic context-based retrieval
- ↑ Thomas Roelleke; Jun Wang (2007), Probabilistic Logical Modelling of the Binary Independence Retrieval model
- ↑ Surajit Chaudhuri; Gautam Das, Vagelis Hristidis, Gerhard Weikum (2006), Probabilistic information retrieval approach for ranking of database query results
- ↑ Zhao, L. and Callan, J., Term Necessity Prediction, Proceedings of the 19th ACM Conference on Information and Knowledge Management (CIKM 2010). Toronto, Canada, 2010.
- ↑ Zhao, L. and Callan, J., Automatic term mismatch diagnosis for selective query expansion, SIGIR 2012.