Behrens–Fisher problem
| Only approximate solutions are known |
In statistics, the Behrens–Fisher problem, named after Ronald Fisher and W. V. Behrens, is the problem of interval estimation and hypothesis testing concerning the difference between the means of two normally distributed populations when the variances of the two populations are not assumed to be equal, based on two independent samples.
Specification
One difficulty with discussing the Behrens–Fisher problem and proposed solutions, is that there are many different interpretations of what is meant by "the Behrens–Fisher problem". These differences involve not only what is counted as being a relevant solution, but even the basic statement of the context being considered.
Context
Let X1, ..., Xn and Y1, ..., Ym be i.i.d. samples from two populations which both come from the same location-scale family of distributions. The scale parameters are assumed to be unknown and not necessarily equal, and the problem is to assess whether the location parameters can reasonably be treated as equal. Lehmann[1] states that "the Behrens–Fisher problem" is used both for this general form of model when the family of distributions is arbitrary and for when the restriction to a normal distribution is made. While Lehmann discusses a number of approaches to the more general problem, mainly based on nonparametrics,[2] most other sources appear to use "the Behrens–Fisher problem" to refer only to the case where the distribution is assumed to be normal: most of this article makes this assumption.
Requirements of solutions
Solutions to the Behrens–Fisher problem have been presented that make use of either a classical or a Bayesian inference point of view and either solution would be notionally invalid judged from the other point of view. If consideration is restricted to classical statistical inference only, it is possible to seek solutions to the inference problem that are simple to apply in a practical sense, giving preference to this simplicity over any inaccuracy in the corresponding probability statements. Where exactness of the significance levels of statistical tests is required, there may be an additional requirement that the procedure should make maximum use of the statistical information in the dataset. It is well known that an exact test can be gained by randomly discarding data from the larger dataset until the sample sizes are equal, assembling data in pairs and taking differences, and then using an ordinary t-test to test for the mean-difference being zero: clearly this would not be "optimal" in any sense.
The task of specifying interval estimates for this problem is one where a frequentist approach fails to provide an exact solution, although some approximations are available. The Bayesian approach also fails to provide an answer that can be expressed as straightforward simple formulae, but modern computational methods of Bayesian analysis do allow essentially exact solutions to be found. Thus study of the problem can be used to elucidate the differences between the frequentist and Bayesian approaches to interval estimation.
Outline of different approaches
Behrens and Fisher approach
Ronald Fisher in 1935[3] introduced fiducial inference in order to apply it to this problem. He referred to an earlier paper by W. V. Behrens from 1929. Behrens and Fisher proposed to find the probability distribution of
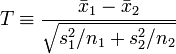
where 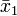 and
and 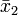 are the two sample means, and s1 and s2 are their standard deviations. See Behrens–Fisher distribution. Fisher approximated the distribution of this by ignoring the random variation of the relative sizes of the standard deviations,
are the two sample means, and s1 and s2 are their standard deviations. See Behrens–Fisher distribution. Fisher approximated the distribution of this by ignoring the random variation of the relative sizes of the standard deviations,

Fisher's solution provoked controversy because it did not have the property that the hypothesis of equal means would be rejected with probability α if the means were in fact equal. Many other methods of treating the problem have been proposed since.[citation needed]
Welch's approximate t solution
A widely used method—for example in statistical packages and in Microsoft Excel—is that of B. L. Welch,[4] who, like Fisher, was at University College London. The variance of the mean difference
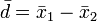
results in
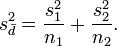
Welch (1938) approximated the distribution of 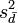 by the Type III Pearson distribution (a scaled chi-squared distribution) whose first two moments agree with that of . This applies to the following number of degrees of freedom (d.f.), which is generally non-integer:
by the Type III Pearson distribution (a scaled chi-squared distribution) whose first two moments agree with that of . This applies to the following number of degrees of freedom (d.f.), which is generally non-integer:

Under the null hypothesis of equal expectations, μ1 = μ2, the distribution of the Behrens-Fisher statistic T, which also depends on the variance ratio σ12/σ22, could now be approximated by Student's t distribution with these ν degrees of freedom. But this ν contains the population variances σi2, and these are unknown. The following estimate only replaces the population variances by the sample variances:
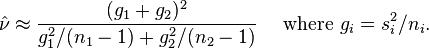
This 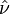 is a random variable. A t distribution with a random number of degrees of freedom does not exist. Nevertheless, the Behrens-Fisher T can be compared with a corresponding quantile of Student's t distribution with these estimated number of degrees of freedom, , which is generally non-integer. In this way, the boundary between acceptance and rejection region of the test statistic T is calculated based on the empirical variances si2, in a way that is a smooth function of these.
is a random variable. A t distribution with a random number of degrees of freedom does not exist. Nevertheless, the Behrens-Fisher T can be compared with a corresponding quantile of Student's t distribution with these estimated number of degrees of freedom, , which is generally non-integer. In this way, the boundary between acceptance and rejection region of the test statistic T is calculated based on the empirical variances si2, in a way that is a smooth function of these.
This method also does not give exactly the nominal rate, but is generally not too far off.[citation needed] However, if the population variances are equal, or if the samples are rather small and the population variances can be assumed to be approximately equal, it is more accurate to use the standard method,[citation needed] which is the two-sample t-test.
Other approaches
A number of different approaches to the general problem have been proposed, some of which claim to "solve" some version of the problem. Among these are,[5]
In Dudewicz’s comparison of selected methods,[5] it was found that the Dudewicz–Ahmed procedure is recommended for practical use.
Variants
A minor variant of the Behrens–Fisher problem has been studied.[9] In this instance the problem is, assuming that the two population-means are in fact the same, to make inferences about the common mean: for example, one could require a confidence interval for the common mean.
Generalisations
The immediate generalisation of the problem involves multivariate normal distributions with unknown covariance matrices, and is known as the Multivariate Behrens–Fisher problem.[10]
Notes
- ↑ Lehmann (1975) p.95
- ↑ Lehmann (1975) Section 7
- ↑ Fisher, 1935
- ↑ Welch (1938, 1947)
- ↑ 5.0 5.1 Dudewicz, Ma, Mai, and Su (2007)
- ↑ Chapman, D. G. (1950). "Some two sample tests". Annals of Mathematical Statistics 21 (4): 601–606. doi:10.1214/aoms/1177729755.
- ↑ Prokof’yev, V. N.; Shishkin, A. D. (1974). "Successive classification of normal sets with unknown variances". Radio Engng. Electron. Phys 19 (2): 141–143.
- ↑ Dudewicz & Ahmed (1998, 1999)
- ↑ Young, G.A., Smith, R.L. (2005) Essentials of Statistical Inference, CUP. ISBN 0-521-83971-8 (page 204)
- ↑ Belloni & Didier (2008)
References
- W. V. Behrens, "Ein beitrag zur Fehlerberechnung bei wenigen Beobachtungen", Landwirtschaftliche Jahrbücher 68 (1929), pp. 807–37. (transl: A contribution to error estimation with few observations. Journal of Agriculture Scientific Archives of the Royal Prussian State College-Economy, 68:807–837, 1929. Berlin - Prussian Ministry of Agriculture, Forests and Domains. Wiegandt and Hempel Publishers, Berlin, 1929) Hathi Trust, Original at University of California
- Bellon, A., Didier, G. (2008) "On the Behrens–Fisher Problem: A Globally Convergent Algorithm and a Finite-Sample Study of the Wald, LR and LM Tests" Annals of Statistics,36 (5), 2377–2408. doi:10.1214/07-AOS528 arXiv electronic reprint
- Chang CH, Pal N (2008) "A revisit to the Behrens-Fisher problem: Comparison of five test methods" Communications in Statistics-Simulation and Computation, 37 (6), 1064-1085. doi:10.1080/03610910802049599
- Dudewicz, E. J., S. U. Ahmed (1998) New exact and asymptotically optimal solution to the Behrens–Fisher problem, with tables. American Journal of Mathematical and Management Sciences, 18, 359–426.
- Dudewicz, E. J., S. U. Ahmed (1999) New exact and asymptotically optimal heteroscedastic statistical procedures and tables, II. American Journal of Mathematical and Management Sciences, 19, 157–180.
- Dudewicz, E. J., Y. Ma, S. E. Mai, and H. Su (2007) "Exact solutions to the Behrens–Fisher problem: Asymptotically optimal and finite sample efficient choice among." Journal of Statistical Planning and Inference, 137 (5), 1584–1605. doi:10.1016/j.jspi.2006.09.007
- Fisher, R. A. (1935) "The fiducial argument in statistical inference", Annals of Eugenics, 8, 391–398.
- Fisher, R. A. (1941) "The Asymptotic Approach to Behrens’ Integral with further Tables for the d Test of Significance", Annals of Eugenics, 11, 141–172.
- Fraser, D. A. S., Rousseau, J. (2008) Studentization and deriving accurate p-values. Biometrika, 95 (1), 1–16. doi:10.1093/biomet/asm093
- Lehmann, E. L. (1975) Nonparametrics: Statistical Methods Based on Ranks, Holden-Day ISBN 0-8162-4996-6, McGraw-Hill ISBN 0-07-037073-7
- Ruben, H. (2002)"A simple conservative and robust solution of the Behrens–Fisher problem", Sankhyā:The Indian Journal of Statistics, Series A, 64 (1),139–155.
- Pardo JA, Pardo MD (2007) "A simulation study of a new family of test statistics for the Behrens-Fisher problem" Kybernetes, 36 (5-6), 806-816. doi:10.1108/03684920710749866
- Sawilowsky, Shlomo S. (2002). Fermat, Schubert, Einstein, and Behrens–Fisher: The Probable Difference Between Two Means When σ1 ≠ σ2 Journal of Modern Applied Statistical Methods, 1(2).
- Welch, B. L. (1938) "The significance of the difference between two means when the population variances are unequal", Biometrika 29, 350–62.
- Welch, B. L. (1947), "The generalization of "Student's" problem when several different population variances are involved", Biometrika 34 (1–2): 28–35, doi:10.1093/biomet/34.1-2.28, MR 19277
- Voinov, V., Nikulin, M. (1995) "On the problem of means of weighted normal populations", "Questiio", 19 (2), 7–20.
- Zheng SR, Shi NZ, Ma WQ (2010) "Statistical inference on difference or ratio of means from heteroscedastic normal populations" Journal of Statistical Planning and Inference, 140 (5), 1236-1242. doi:10.1016/j.jspi.2009.11.010
External links
- Dong, B.L. (2004) The Behrens–Fisher Problem: An Empirical Likelihood Approach Econometrics Working Paper EWP0404, University of Victoria