Behrens–Fisher distribution
In statistics, the Behrens–Fisher distribution, named after Ronald Fisher and W. V. Behrens, is a parameterized family of probability distributions arising from the solution of the Behrens–Fisher problem proposed first by Behrens and several years later by Fisher. The Behrens–Fisher problem is that of statistical inference concerning the difference between the means of two normally distributed populations when the ratio of their variances is not known (and in particular, it is not known that their variances are equal).
Definition
The Behrens–Fisher distribution is the distribution of a random variable of the form

where T1 and T2 are independent random variables each with a Student's t-distribution, with respective degrees of freedom ν1 = n1 − 1 and ν2 = n2 − 1, and θ is a constant. Thus the family of Behrens–Fisher distributions is parametrized by ν1, ν2, and θ.
Derivation
Suppose it were known that the two population variances are equal, and samples of sizes n1 and n2 are taken from the two populations:
![{\begin{aligned}X_{{1,1}},\ldots ,X_{{1,n_{1}}}&\sim \operatorname {i.i.d.}N(\mu _{1},\sigma ^{2}),\\[6pt]X_{{2,1}},\ldots ,X_{{2,n_{2}}}&\sim \operatorname {i.i.d.}N(\mu _{2},\sigma ^{2}).\end{aligned}}](/2014-wikipedia_en_all_02_2014/I/media/3/5/9/c/359c8536904dfe5d5f3a170f09ac4774.png)
where "i.i.d" are independent and identically distributed random variables and N denotes the normal distribution. The two sample means are
![{\begin{aligned}{\bar {X}}_{1}&=(X_{{1,1}}+\cdots +X_{{1,n_{1}}})/n_{1}\\[6pt]{\bar {X}}_{2}&=(X_{{2,1}}+\cdots +X_{{2,n_{2}}})/n_{2}\end{aligned}}](/2014-wikipedia_en_all_02_2014/I/media/9/8/1/3/9813813138299d24dcd0577d1e888427.png)
The usual "pooled" unbiased estimate of the common variance σ2 is then

where S12 and S22 are the usual unbiased (Bessel-corrected) estimates of the two population variances.
Under these assumptions, the pivotal quantity

has a t-distribution with n1 + n2 − 2 degrees of freedom. Accordingly, one can find a confidence interval for μ2 − μ1 whose endpoints are

where A is an appropriate percentage point of the t-distribution.
However, in the Behrens–Fisher problem, the two population variances are not known to be equal, nor is their ratio known. Fisher considered[citation needed] the pivotal quantity
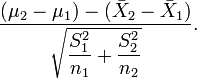
This can be written as

where

are the usual one-sample t-statistics and

and one takes θ to be in the first quadrant. The algebraic details are as follows:
![{\begin{aligned}{\frac {(\mu _{2}-\mu _{1})-({\bar X}_{2}-{\bar X}_{1})}{\displaystyle {\sqrt {{\frac {S_{1}^{2}}{n_{1}}}+{\frac {S_{2}^{2}}{n_{2}}}}}}}&={\frac {\mu _{2}-{\bar {X}}_{2}}{\displaystyle {\sqrt {{\frac {S_{1}^{2}}{n_{1}}}+{\frac {S_{2}^{2}}{n_{2}}}}}}}-{\frac {\mu _{1}-{\bar {X}}_{1}}{\displaystyle {\sqrt {{\frac {S_{1}^{2}}{n_{1}}}+{\frac {S_{2}^{2}}{n_{2}}}}}}}\\[10pt]&=\underbrace {{\frac {\mu _{2}-{\bar {X}}_{2}}{S_{2}/{\sqrt {n_{2}}}}}}_{{{\text{This is }}T_{2}}}\cdot \underbrace {\left({\frac {S_{2}/{\sqrt {n_{2}}}}{\displaystyle {\sqrt {{\frac {S_{1}^{2}}{n_{1}}}+{\frac {S_{2}^{2}}{n_{2}}}}}}}\right)}_{{{\text{This is }}\cos \theta }}-\underbrace {{\frac {\mu _{1}-{\bar {X}}_{1}}{S_{1}/{\sqrt {n_{1}}}}}}_{{{\text{This is }}T_{1}}}\cdot \underbrace {\left({\frac {S_{1}/{\sqrt {n_{1}}}}{\displaystyle {\sqrt {{\frac {S_{1}^{2}}{n_{1}}}+{\frac {S_{2}^{2}}{n_{2}}}}}}}\right)}_{{{\text{This is }}\sin \theta }}.\qquad \qquad \qquad (1)\end{aligned}}](/2014-wikipedia_en_all_02_2014/I/media/b/6/b/7/b6b726a1e39b0e46f1c20617727a2fdc.png)
The fact that the sum of the squares of the expressions in parentheses above is 1 implies that they are the cosine and sine of some angle.
The Behren–Fisher distribution is actually the conditional distribution of the quantity (1) above, given the values of the quantities labeled cos θ and sin θ. In effect, Fisher conditions on ancillary information.
Fisher then found the "fiducial interval" whose endpoints are

where A is the appropriate percentage point of the Behrens–Fisher distribution. Fisher claimed[citation needed] that the probability that μ2 − μ1 is in this interval, given the data (ultimately the Xs) is the probability that a Behrens–Fisher-distributed random variable is between −A and A.
Fiducial intervals versus confidence intervals
Bartlett[citation needed] showed that this "fiducial interval" is not a confidence interval because it does not have a constant coverage rate. Fisher did not consider that a cogent objection to the use of the fiducial interval.[citation needed]
Further reading
- Kendall, Maurice G., Stuart, Alan (1973) The Advanced Theory of Statistics, Volume 2: Inference and Relationship, 3rd Edition, Griffin. ISBN 0-85264-215-6 (Chapter 21)