UTF-16
UTF-16 (16-bit Unicode Transformation Format) is a character encoding for Unicode capable of encoding 1,112,064[1] numbers (called code points) in the Unicode code space from 0 to 0x10FFFF. It produces a variable-length result of either one or two 16-bit code units per code point.
The older UCS-2 (2-byte Universal Character Set) is a similar character encoding that was superseded by UTF-16 in version 2.0 of the Unicode standard in July 1996.[2] It produces a fixed-length format by simply using the code point as the 16-bit code unit and produces exactly the same result as UTF-16 for 96.9% of all the code points in the range 0-0xFFFF, including all characters that had been assigned a value at that time.
UTF-16 is officially defined in Annex C of the international standard ISO/IEC 10646.[3] It is also described in "The Unicode Standard" version 2.0 and higher, as well as in the IETF's RFC 2781.
Contents |
Description
The Unicode code space is divided into seventeen planes of 216 (65,536) code points each, though some code points have not yet been assigned character values, some are reserved for private use, and some are permanently reserved as non-characters. The code points in each plane have the hexadecimal values xx0000 to xxFFFF, where xx is a hex value from 00 to 10, signifying which plane the values belong to.
Code points U+0000 to U+D7FF and U+E000 to U+FFFF
The first plane (code points U+0000 to U+FFFF) contains the most frequently used characters and is called the Basic Multilingual Plane or BMP. Both UTF-16 and UCS-2 encode valid code points in this range as single 16-bit code units that are numerically equal to the corresponding code points. The code points in the BMP are the only code points that can be represented in UCS-2.
Code points U+10000 to U+10FFFF
Code points from the other planes (called Supplementary Planes) are encoded in UTF-16 by pairs of 16-bit code units called a surrogate pair, by the following scheme:
| hi \ lo | DC00 | DC01 | … | DFFF |
|---|---|---|---|---|
| D800 | 10000 | 10001 | … | 103FF |
| D801 | 10400 | 10401 | … | 107FF |
| ⋮ | ⋮ | ⋮ | ⋱ | ⋮ |
| DBFF | 10FC00 | 10FC01 | … | 10FFFF |
- 0x10000 is subtracted from the code point, leaving a 20 bit number in the range 0..0xFFFFF.
- The top ten bits (a number in the range 0..0x3FF) are added to 0xD800 to give the first code unit or high surrogate, which will be in the range 0xD800..0xDBFF. Because high surrogates are numerically lower than low surrogates, the Unicode Standard now often refers to these as "lead surrogates" to avoid confusion.
- The low ten bits (also in the range 0..0x3FF) are added to 0xDC00 to give the second code unit or low surrogate, which will be in the range 0xDC00..0xDFFF. Because low surrogates are numerically higher than high surrogates, the Unicode Standard now often refers to these as "trail surrogates" to avoid confusion.
Since the ranges for the high surrogates, low surrogates, and valid BMP characters are disjoint, searches are simplified: it is not possible for part of one character to match a different part of another character. It also means that UTF-16 is self-synchronizing: the start of the next character following a given code unit can be found by examining only that one code unit. UTF-8 shares these advantages, but many earlier encoding schemes did not allow unambiguous searching and could only be synchronized by re-parsing from the start of the string.
Because the most commonly used characters are all in the Basic Multilingual Plane, handling of surrogate pairs is often not thoroughly tested. This leads to persistent bugs and potential security holes, even in popular and well-reviewed application software.[4]
Code points U+D800..U+DFFF
UTF-16 offers no legal way to encode the code points used by surrogate pairs: they can appear legally only in pairs, with a high surrogate immediately followed by a low surrogate, to represent a code point in one of the Supplementary Planes. The Unicode standard permanently reserves the values U+D800..U+DFFF for UTF-16 encoding and these code points will never be assigned a character, so there should be no reason to encode them.
It is possible to encode these values in UCS-2 (by using the code point as the single code unit). It is also possible to illegally but unambiguously encode them in UTF-16 as long as they are not in a high+low pair, by using a code unit equal to the code point. The majority of UTF-16 encoder and decoder implementations translate between other encodings as though this were the case, although the standard states that such arrangements should be treated as encoding errors.
Byte order encoding schemes
UTF-16 and UCS-2 produce a sequence of 16-bit code units. Each unit thus takes two 8-bit bytes, and the order of the bytes may depend on the endianness (byte order) of the computer architecture.
To assist in recognizing the byte order of code units, UTF-16 allows a Byte Order Mark (BOM), a code unit with the value U+FEFF, to precede the first actual coded value.[5] (U+FEFF is the invisible Zero-width non-breaking space (ZWNBSP) character.)[6] If the endian architecture of the decoder matches that of the encoder, the decoder detects the 0xFEFF value, but an opposite-endian decoder interprets the BOM as the non-character value U+FFFE reserved for this purpose. This incorrect result provides a hint to perform byte-swapping for the remaining values. If the BOM is missing, the standard says that big-endian encoding should be assumed. (In practice, due to Windows using little-endian order by default, many applications also assume little-endian encoding by default.) If there is no BOM, one method of recognizing a UTF-16 encoding is searching for the space character (U+0020) which are very common in texts in most languages.
The standard also allows the byte order to be stated explicitly by specifying UTF-16BE or UTF-16LE as the encoding type. When the byte order is specified explicitly this way, a BOM is specifically not supposed to be prepended to the text, and a U+FEFF at the beginning should be handled as a ZWNBSP character. Many applications ignore the BOM code at the start of any Unicode encoding. Web browsers often use a BOM as a hint in determining the character encoding.[7]
For Internet protocols, IANA has approved "UTF-16", "UTF-16BE", and "UTF-16LE" as the names for these encodings. (The names are case insensitive.) The aliases UTF_16 or UTF16 may be meaningful in some programming languages or software applications, but they are not standard names in Internet protocols.
UCS-2 encoding is defined to be big-endian only. In practice most software defaults to little-endian, and handles a leading BOM to define the byte order just as in UTF-16. Although the similar designations UCS-2BE and UCS-2LE imitate the UTF-16 labels, they do not represent official encoding schemes.
Use in major operating systems and environments
UTF-16 is used for text in the OS API in Microsoft Windows 2000/XP/2003/Vista/CE.[8] Older Windows NT systems (prior to Windows 2000) only support UCS-2.[9] In Windows XP, no code point above U+FFFF is included in any font delivered with Windows for European languages.[10][11] Files and network data tend to be a mix of UTF-16, UTF-8, and legacy byte encodings. For instance the registry is a byte encoding, and Windows will often display filenames from remote systems as byte encodings, resulting in mojibake if in fact they are UTF-8.
UTF-16 is used by the Qualcomm BREW operating systems; the .NET environments; Mac OS X's Cocoa and Core Foundation frameworks; and the Qt cross-platform graphical widget toolkit.
Symbian OS used in Nokia S60 handsets and Sony Ericsson UIQ handsets uses UCS-2.
The Joliet file system, used in CD-ROM media, encodes file names using UCS-2BE (up to sixty-four Unicode characters per file).
The Python language environment officially only uses UCS-2 internally since version 2.0, but the UTF-8 decoder to "Unicode" produces correct UTF-16. Since Python 2.2, "wide" (UCS-4) builds of Unicode are supported, and "narrow" builds officially use UTF-16.[12] In Python 3.3, UTF-16 stops being used for the internal representation.[13]
Java originally used UCS-2, and added UTF-16 supplementary character support in J2SE 5.0. However, non-BMP characters require the individual surrogate halves to be entered individually, for example: "\uD834\uDD1E" for U+1D11E.[14]
In many languages quoted strings need a new syntax for quoting non-BMP characters, as the "\uXXXX" syntax explicitly limits itself to 4 hex digits. The most common (used by C#, D and several other languages) is to use an upper-case 'U' with 8 hex digits such as "\U0001D11E"[15] In Java 7 regular expressions, abstract code points can (and in character classes involving planes 1–16, must) be specified using the "\x{HHHHHH}" syntax used in ICU and Perl, where "H" may be 1–6 ASCII hex digits to cover the full range of Unicode.
These implementations all return the number of 16-bit code units rather than the number of Unicode code points when you use the equivalent of strlen() on their strings, and that indexing into a string returns the indexed code unit, not the indexed code point.[16][17][18] The term "character" is defined and used in multiple ways within the Unicode terminology,[19] so a count of them is not possible. Most of the confusion is due to obsolete ASCII-era documentation using the term "character" when a fixed-size "byte" was intended.
Examples
| code point | glyph* | character | UTF-16 code units (hex) | UTF-16BE code units (hex) | UTF-16LE code units (hex) |
|---|---|---|---|---|---|
| U+007A | z | LATIN SMALL LETTER Z | 007A | 00, 7A | 7A, 00 |
| U+6C34 | 水 | CJK UNIFIED IDEOGRAPH-6C34 (water) | 6C34 | 6C, 34 | 34, 6C |
| U+10000 | 𐀀 | LINEAR B SYLLABLE B008 A (first non-BMP code point) | D800, DC00 | D8, 00, DC, 00 | 00, D8, 00, DC |
| U+1D11E | 𝄞 | MUSICAL SYMBOL G CLEF | D834, DD1E | D8, 34, DD, 1E | 34, D8, 1E, DD |
| U+10FFFD | | PRIVATE USE CHARACTER-10FFFD (last Unicode code point) | DBFF, DFFD | DB, FF, DF, FD | FF, DB, FD, DF |
* Appropriate font and software are required to see the correct glyphs.
Example UTF-16 encoding procedure
The character at code point U+64321 (hexadecimal) is to be encoded in UTF-16. Since it is above U+FFFF, it must be encoded with a surrogate pair, as follows:
v = 0x64321 v′ = v - 0x10000 = 0x54321 = 0101 0100 0011 0010 0001 vh = v′ >> 10 = 01 0101 0000 // higher 10 bits of v′ vl = v′ & 0x3FF = 11 0010 0001 // lower 10 bits of v′ w1 = 0xD800 + vh = 1101 1000 0000 0000 + 01 0101 0000 = 1101 1001 0101 0000 = 0xD950 // first code unit of UTF-16 encoding w2 = 0xDC00 + vl = 1101 1100 0000 0000 + 11 0010 0001 = 1101 1111 0010 0001 = 0xDF21 // second code unit of UTF-16 encoding
See also
References
- ^
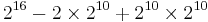 , where
, where 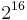 is the BMP,
is the BMP, 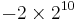 is the interval U+D800–U+DFFF, and
is the interval U+D800–U+DFFF, and 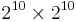 are the higher planes.
are the higher planes. - ^ "Questions about encoding forms". http://www.unicode.org/faq//utf_bom.html. Retrieved 12 November 2010.
- ^ ISO/IEC 10646-1:2000(E), pp. 890-892; ISO/IEC 10646:2003(E), pp. 1364-1366; ISO/IEC 10646:2012(E) Final Committee Draft (FCD), p. 2208; The FCD contains a reference to clauses 9 and 10, pp. 15-17.
- ^ "Code in Apache Xalan 2.7.0 which can fail on surrogate pairs". Apache Foundation. http://www.google.com/codesearch/p?hl=en&sa=N&cd=3&ct=rc#WiHOcNHN_BU/xalan-j_2_7_0/src/org/apache/xalan/lib/ExsltStrings.java&q=file:ExsltStrings\.java%20align.
- ^ UTF-8 encoding produces byte values strictly less than 0xFE, so either byte in the BOM sequence also identifies the encoding as UTF-16.
- ^ Use of U+FEFF as the character ZWNBSP instead of as a BOM has been deprecated in favor of U+2060 (WORD JOINER); see Byte Order Mark (BOM) FAQ at unicode.org. But if an application interprets an initial BOM as a character, the ZWNBSP character is invisible, so the impact is minimal.
- ^ goto.glocalnet.net Encoding test pages (load these files and check the encoding that the browser selects)
- ^ Unicode (Windows). Retrieved 08 March 2011 "These functions use UTF-16 (wide character) encoding (...) used for native Unicode encoding on Windows operating systems."
- ^ "Description of storing UTF-8 data in SQL Server". microsoft.com. December 7, 2005. http://support.microsoft.com/kb/232580. Retrieved 2008-02-01.
- ^ "Unicode". microsoft.com. http://msdn.microsoft.com/en-us/library/dd374081(VS.85).aspx. Retrieved 2009-07-20.
- ^ "Surrogates and Supplementary Characters". microsoft.com. http://msdn.microsoft.com/en-us/library/dd374069(VS.85).aspx. Retrieved 2009-07-20.
- ^ PEP 261
- ^ PEP 393
- ^ Java Language Specification, Third Edition, section 3.3
- ^ ECMA-334, section 9.4.1
- ^ Austin, Calvin (May 2004). "J2SE 5.0 in a Nutshell". http://java.sun.com/developer/technicalArticles/releases/j2se15/. Retrieved 2008-06-17. "Supplementary Character Support",
- ^ "Javadoc for java.lang.String.charAt(int)". http://docs.oracle.com/javase/6/docs/api/java/lang/String.html#charAt(int).
- ^ "C Sharp Language Specification". microsoft.com. http://download.microsoft.com/download/3/8/8/388e7205-bc10-4226-b2a8-75351c669b09/csharp%20language%20specification.doc. Retrieved 2009-07-08.
- ^ http://unicode.org/glossary/#C
External links
- A very short algorithm for determining the surrogate pair for any codepoint
- Unicode Technical Note #12: UTF-16 for Processing
- Unicode FAQ: What is the difference between UCS-2 and UTF-16?
- Unicode Character Name Index
- RFC 2781: UTF-16, an encoding of ISO 10646
- java.lang.String documentation, discussing surrogate handling
|
|||||||||||||||||||||||||||||||||||||||||||||||