U-statistic
In statistical theory, a U-statistic is a class of statistics that is especially important in estimation theory. In elementary statistics, U-statistics arise naturally in producing minimum-variance unbiased estimators. A mean-unbiased estimator that is conditioned on the order statistics (of a sequence of independent and identically distributed random variables) becomes the minimum-variance unbiased estimator, by the Rao-Blackwell theorem.[1][2] Of even more importance[3] is that the theory related to U-statistics allows a single theoretical framework to be used in non-parametric statistics to prove results for a wide range of test-statistics and estimators relating to the asymptotic normality and to the variance (in finite samples) of such quantities. In addition the theory has applications to estimators which are not themselves U-statistics.
Suppose that a problem involves independent and identically-distributed random variables and that estimation of a certain parameter is required. Suppose that a simple unbiased estimate can be constructed based on only a few observations: this defines the basic estimator based on a given number of observations. For example, a single observation is itself an unbiased estimate of the mean and a pair of observations can be used to derive an unbiased estimate of the variance. The U-statistic based on this estimator is defined as the average (across all combinatorial selections of the given size from the full set of observations) of the basic estimator applied to the sub-samples.
Sen (1992) provides a review of the paper by Wassily Hoeffding (1948), which introduced U-statistics and set out the theory relating to them, and in doing so Sen outlines the importance U-statistics have in statistical theory. Sen says[4] "The impact of Hoeffding (1948) is overwhelming at the present time and is very likely to continue in the years to come". Note that the theory of U-statistics is not limited to[5] the case of independent and identically-distributed random variables or to scalar random variables.
Contents |
Formal definition
The term U-statistic, due to Hoeffding (1948), is defined as follows.
Let 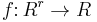 be a real-valued or complex-valued function of
be a real-valued or complex-valued function of 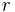 variables. For each
variables. For each  the associated U-statistic
the associated U-statistic 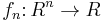 is equal to the average over ordered samples
is equal to the average over ordered samples  of size of the sample values
of size of the sample values 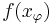 . In other words,
. In other words, 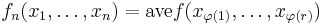 , the average being taken over distinct ordered samples of size taken from
, the average being taken over distinct ordered samples of size taken from  . Each U-statistic
. Each U-statistic 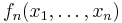 is necessarily a symmetric function.
is necessarily a symmetric function.
In other words, it bootstraps a r-sample estimator to an n-sample estimator.
U-statistics are very natural in statistical work, particularly in Hoeffding's context of independent and identically-distributed random variables, or more generally for exchangeable sequences, such as in simple random sampling from a finite population, where the defining property is termed `inheritance on the average'.
Fisher's k-statistics and Tukey's polykays are examples of homogeneous polynomial U-statistics (Fisher, 1929; Tukey, 1950). For a simple random sample φ of size n taken from a population of size N, the U-statistic has the property that the average over sample values ƒn(xφ) is exactly equal to the population value ƒN(x).
Examples
Some examples: If 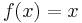 the U-statistic
the U-statistic 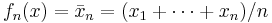 is the sample mean.
is the sample mean.
If  , the U-statistic is the mean pairwise deviation
, the U-statistic is the mean pairwise deviation 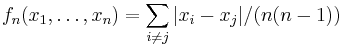 , defined for
, defined for 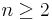 .
.
If 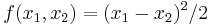 , the U-statistic is the sample variance
, the U-statistic is the sample variance 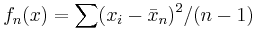 with divisor
with divisor 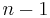 , defined for .
, defined for .
The third  -statistic
-statistic 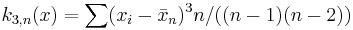 , the sample skewness defined for
, the sample skewness defined for 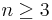 , is a U-statistic.
, is a U-statistic.
The following case highlights an important point. If 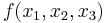 is the median of three values, is not the median of
is the median of three values, is not the median of  values. However, it is a minimum variance unbiased estimate of the expected value of the median of three values and in this application of the theory it is the population parameter defined as "the expected value of the median of three values" which is being estimated, not the median of the population. Similar estimates play a central role where the parameters of a family of probability distributions are being estimated by probability weighted moments or L-moments.
values. However, it is a minimum variance unbiased estimate of the expected value of the median of three values and in this application of the theory it is the population parameter defined as "the expected value of the median of three values" which is being estimated, not the median of the population. Similar estimates play a central role where the parameters of a family of probability distributions are being estimated by probability weighted moments or L-moments.
See also
Notes
- ^ Cox & Hinkley (1974),p. 200, p. 258
- ^ Hoeffding (1948), between Eq's(4.3),(4.4)
- ^ Sen (1992)
- ^ Sen (1992) p. 307
- ^ Sen (1992), p306
References
- Borovskikh, Yu. V. (1996). U-statistics in Banach spaces. Utrecht: VSP. pp. xii+420. ISBN 90-6764-200-2. MR1419498.
- Cox, D.R., Hinkley, D.V. (1974) Theoretical statistics. Chapman and Hall. ISBN 0-412-12420-3
- Fisher, R.A. (1929) Moments and product moments of sampling distributions. Proceedings of the London Mathematical Society, 2, 30:199–238.
- Hoeffding, W. (1948) A class of statistics with asymptotically normal distributions. Annals of Statistics, 19:293–325. (Partially reprinted in: Kotz, S., Johnson, N.L. (1992) Breakthroughs in Statistics, Vol I, pp 308–334. Springer-Verlag. ISBN 0-387-94037-5)
- Koroljuk, V. S.; Borovskich, Yu. V. (1994). Theory of U-statistics. Mathematics and its Applications. 273 (Translated by P. V. Malyshev and D. V. Malyshev from the 1989 Russian original ed.). Dordrecht: Kluwer Academic Publishers Group. pp. x+552. ISBN 0-7923-2608-3. MR1472486.
- Lee, A.J. (1990) U-Statistics: Theory and Practice. Marcel Dekker, New York. pp320 ISBN 0824782534
- Sen, P.K (1992) Introduction to Hoeffding (1948) A Class of Statistics with Asymptotically Normal Distribution. In: Kotz, S., Johnson, N.L. Breakthroughs in Statistics, Vol I, pp 299–307. Springer-Verlag. ISBN 0-387-94037-5.
- Tukey, J.W. (1950) Some Sampling Simplified. Journal of the American Statistical Association, 45, 501–519.