Typical set
In information theory, the typical set is a set of sequences whose probability is close to two raised to the negative power of the entropy of their source distribution. That this set has total probability close to one is a consequence of the asymptotic equipartition property (AEP) which is a kind of law of large numbers. The notion of typicality is only concerned with the probability of a sequence and not the actual sequence itself.
This has great use in compression theory as it provides a theoretical means for compressing data, allowing us to represent any sequence Xn using nH(X) bits on average, and, hence, justifying the use of entropy as a measure of information from a source.
The AEP can also be proven for a large class of stationary ergodic processes, allowing typical set to be defined in more general cases.
Contents |
(Weakly) typical sequences (weak typicality, entropy typicality)
If a sequence x1, ..., xn is drawn from an i.i.d. distribution X defined over a finite alphabet 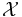 , then the typical set, Aε(n)
, then the typical set, Aε(n)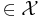 (n) is defined as those sequences which satisfy:
(n) is defined as those sequences which satisfy:
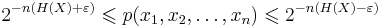
Where
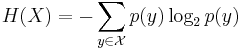
is the information entropy of X. The probability above need only be within a factor of 2nε.
It has the following properties if n is sufficiently large, ε can be chosen arbitrarily small so that:
- The probability of a sequence from X being drawn from Aε(n) is greater than 1 − ε
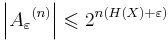
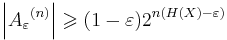
For a general stochastic process {X(t)} with AEP, the (weakly) typical set can be defined similarly with p(x1, x2, ..., xn) replaced by p(x0τ) (i.e. the probability of the sample limited to the time interval [0, τ]), n being the degree of freedom of the process in the time interval and H(X) being the entropy rate. If the process is continuous-valued, differential entropy is used instead.
Strongly typical sequences (strong typicality, letter typicality)
If a sequence x1, ..., xn is drawn from some specified joint distribution defined over a finite or an infinite alphabet , then the strongly typical set, Aε,strong(n) is defined as the set of sequences which satisfy
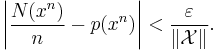
where 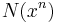 is the number of occurrences of a specific symbol in the sequence.
is the number of occurrences of a specific symbol in the sequence.
It can be shown that strongly typical sequences are also weakly typical (with a different constant ε), and hence the name. The two forms, however, are not equivalent. Strong typicality is often easier to work with in proving theorems for memoryless channels. However, as is apparent from the definition, this form of typicality is only defined for random variables having finite support.
Jointly typical sequences
Two sequences 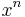 and
and 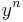 are jointly ε-typical if the pair
are jointly ε-typical if the pair 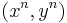 is ε-typical with respect to the joint distribution
is ε-typical with respect to the joint distribution 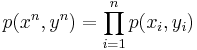 and both and are ε-typical with respect to their marginal distributions
and both and are ε-typical with respect to their marginal distributions 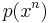 and
and 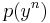 . The set of all such pairs of sequences is denoted by
. The set of all such pairs of sequences is denoted by 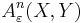 . Jointly ε-typical n-tuple sequences are defined similarly.
. Jointly ε-typical n-tuple sequences are defined similarly.
Let 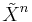 and
and 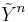 be two independent sequences of random variables with the same marginal distributions and . Then the set of jointly typical sequences has the following properties:
be two independent sequences of random variables with the same marginal distributions and . Then the set of jointly typical sequences has the following properties:
![P\left[ (X^n,Y^n) \in A_{\varepsilon}^n(X,Y) \right] \geqslant 1 - \epsilon](/2012-wikipedia_en_all_nopic_01_2012/I/63339cc4f5f97394db3d6d0a7650c442.png)
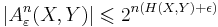
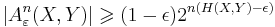
![P\left[ (\tilde{X}^n,\tilde{Y}^n) \in A_{\varepsilon}^n(X,Y) \right] \leqslant 2^{-n (I(X;Y) - 3 \epsilon)}](/2012-wikipedia_en_all_nopic_01_2012/I/9350c18a7c7975eeab331c07a5e722cc.png)
![P\left[ (\tilde{X}^n,\tilde{Y}^n) \in A_{\varepsilon}^n(X,Y) \right] \geqslant (1 - \epsilon) 2^{-n (I(X;Y) %2B 3 \epsilon)}](/2012-wikipedia_en_all_nopic_01_2012/I/c3a08f03cbbc0bc9223fe230bb36ed4b.png)
Applications of typicality
Typical set encoding
In communication, typical set encoding encodes only the typical set of a stochastic source with fixed length block codes. Asymptotically, it is, by the AEP, lossless and achieves the minimum rate equal to the entropy rate of the source.
Typical set decoding
In communication, typical set decoding is used in conjunction with random coding to estimate the transmitted message as the one with a codeword that is jointly ε-typical with the observation. i.e.
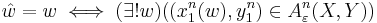
where 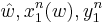 are the message estimate, codeword of message
are the message estimate, codeword of message 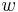 and the observation respectively. is defined with respect to the joint distribution
and the observation respectively. is defined with respect to the joint distribution 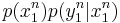 where
where 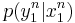 is the transition probability that characterizes the channel statistics, and
is the transition probability that characterizes the channel statistics, and 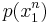 is some input distribution used to generate the codewords in the random codebook.
is some input distribution used to generate the codewords in the random codebook.
Universal null-hypothesis testing
Universal channel code
See also
References
- C. E. Shannon, "A Mathematical Theory of Communication", Bell System Technical Journal, vol. 27, pp. 379–423, 623-656, July, October, 1948
- Cover, Thomas M. (2006). "Chapter 3: Asymptotic Equipartition Property, Chapter 5: Data Compression, Chapter 8: Channel Capacity". Elements of Information Theory. John Wiley & Sons. ISBN 0-471-24195-4.
- David J. C. MacKay. Information Theory, Inference, and Learning Algorithms Cambridge: Cambridge University Press, 2003. ISBN 0-521-64298-1