Student's t-test
A t-test is any statistical hypothesis test in which the test statistic follows a Student's t distribution if the null hypothesis is supported. It is most commonly applied when the test statistic would follow a normal distribution if the value of a scaling term in the test statistic were known. When the scaling term is unknown and is replaced by an estimate based on the data, the test statistic (under certain conditions) follows a Student's t distribution.
Contents |
History
The t-statistic was introduced in 1908 by William Sealy Gosset, a chemist working for the Guinness brewery in Dublin, Ireland ("Student" was his pen name).[1][2][3] Gosset had been hired due to Claude Guinness's policy of recruiting the best graduates from Oxford and Cambridge to apply biochemistry and statistics to Guinness' industrial processes.[2] Gosset devised the t-test as a way to cheaply monitor the quality of stout. He published the test in Biometrika in 1908, but was forced to use a pen name by his employer, who regarded the fact that they were using statistics as a trade secret. In fact, Gosset's identity was known to fellow statisticians.[4]
Uses
Among the most frequently used t-tests are:
- A one-sample location test of whether the mean of a normally distributed population has a value specified in a null hypothesis.
- A two sample location test of the null hypothesis that the means of two normally distributed populations are equal. All such tests are usually called Student's t-tests, though strictly speaking that name should only be used if the variances of the two populations are also assumed to be equal; the form of the test used when this assumption is dropped is sometimes called Welch's t-test. These tests are often referred to as "unpaired" or "independent samples" t-tests, as they are typically applied when the statistical units underlying the two samples being compared are non-overlapping.[5]
- A test of the null hypothesis that the difference between two responses measured on the same statistical unit has a mean value of zero. For example, suppose we measure the size of a cancer patient's tumor before and after a treatment. If the treatment is effective, we expect the tumor size for many of the patients to be smaller following the treatment. This is often referred to as the "paired" or "repeated measures" t-test:[5][6] see paired difference test.
- A test of whether the slope of a regression line differs significantly from 0.
Assumptions
Most t-test statistics have the form 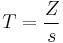 , where Z and s are functions of the data. Typically, Z is designed to be sensitive to the alternative hypothesis (i.e. its magnitude tends to be larger when the alternative hypothesis is true), whereas s is a scaling parameter that allows the distribution of T to be determined.
, where Z and s are functions of the data. Typically, Z is designed to be sensitive to the alternative hypothesis (i.e. its magnitude tends to be larger when the alternative hypothesis is true), whereas s is a scaling parameter that allows the distribution of T to be determined.
As an example, in the one-sample t-test 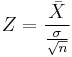 , where
, where 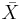 is the sample mean of the data, n is the sample size, and σ is the population standard deviation of the data; s in the one-sample t-test is
is the sample mean of the data, n is the sample size, and σ is the population standard deviation of the data; s in the one-sample t-test is 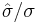 , where
, where 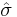 is the sample standard deviation.
is the sample standard deviation.
The assumptions underlying a t-test are that
- Z follows a standard normal distribution under the null hypothesis
- ps2 follows a χ2 distribution with p degrees of freedom under the null hypothesis, where p is a positive constant
- Z and s are independent.
In a specific type of t-test, these conditions are consequences of the population being studied, and of the way in which the data are sampled. For example, in the t-test comparing the means of two independent samples, the following assumptions should be met:
- Each of the two populations being compared should follow a normal distribution. This can be tested using a normality test, such as the Shapiro-Wilk or Kolmogorov–Smirnov test, or it can be assessed graphically using a normal quantile plot.
- If using Student's original definition of the t-test, the two populations being compared should have the same variance (testable using F test, Levene's test, Bartlett's test, or the Brown–Forsythe test; or assessable graphically using a Q-Q plot). If the sample sizes in the two groups being compared are roughly equal, Student's original t-test is highly robust to the presence of unequal variances.[7] Welch's t-test is insensitive to equality of the variances regardless of whether the sample sizes are similar.
- The data used to carry out the test should be sampled independently from the two populations being compared. This is in general not testable from the data, but if the data are known to be dependently sampled (i.e. if they were sampled in clusters), then the classical t-tests discussed here may give misleading results.
Unpaired and paired two-sample t-tests
Two-sample t-tests for a difference in mean can be either unpaired or paired. Paired t-tests are a form of blocking, and have greater power than unpaired tests when the paired units are similar with respect to "noise factors" that are independent of membership in the two groups being compared. In a different context, paired t-tests can be used to reduce the effects of confounding factors in an observational study.
Unpaired
The unpaired, or "independent samples" t-test is used when two separate sets of independent and identically distributed samples are obtained, one from each of the two populations being compared. For example, suppose we are evaluating the effect of a medical treatment, and we enroll 100 subjects into our study, then randomize 50 subjects to the treatment group and 50 subjects to the control group. In this case, we have two independent samples and would use the unpaired form of the t-test. The randomization is not essential here—if we contacted 100 people by phone and obtained each person's age and gender, and then used a two-sample t-test to see whether the mean ages differ by gender, this would also be an independent samples t-test, even though the data are observational.
Paired
Dependent samples (or "paired") t-tests typically consist of a sample of matched pairs of similar units, or one group of units that has been tested twice (a "repeated measures" t-test). A typical example of the repeated measures t-test would be where subjects are tested prior to a treatment, say for high blood pressure, and the same subjects are tested again after treatment with a blood-pressure lowering medication.
A dependent t-test based on a "matched-pairs sample" results from an unpaired sample that is subsequently used to form a paired sample, by using additional variables that were measured along with the variable of interest.[8] The matching is carried out by identifying pairs of values consisting of one observation from each of the two samples, where the pair is similar in terms of other measured variables. This approach is often used in observational studies to reduce or eliminate the effects of confounding factors.
Calculations
Explicit expressions that can be used to carry out various t-tests are given below. In each case, the formula for a test statistic that either exactly follows or closely approximates a t-distribution under the null hypothesis is given. Also, the appropriate degrees of freedom are given in each case. Each of these statistics can be used to carry out either a one-tailed test or a two-tailed test.
Once a t value is determined, a p-value can be found using a table of values from Student's t-distribution. If the calculated p-value is below the threshold chosen for statistical significance (usually the 0.10, the 0.05, or 0.01 level), then the null hypothesis is rejected in favor of the alternative hypothesis.
One-sample t-test
In testing the null hypothesis that the population mean is equal to a specified value μ0, one uses the statistic
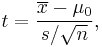
where 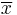 is the sample mean, s is the sample standard deviation of the sample and n is the sample size. The degrees of freedom used in this test is n − 1.
is the sample mean, s is the sample standard deviation of the sample and n is the sample size. The degrees of freedom used in this test is n − 1.
Slope of a regression line
Suppose one is fitting the model
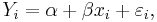
where xi, i = 1, ..., n are known, α and β are unknown, and εi are independent identically normally distributed random errors with expected value 0 and unknown variance σ2, and Yi, i = 1, ..., n are observed. It is desired to test the null hypothesis that the slope β is equal to some specified value β0 (often taken to be 0, in which case the hypothesis is that x and y are unrelated).
Let
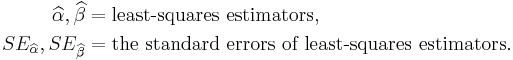
Then
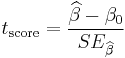
has a t-distribution with n − 2 degrees of freedom if the null hypothesis is true. The standard error of the angular coefficient:
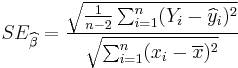
can be written in terms of the residuals. Let
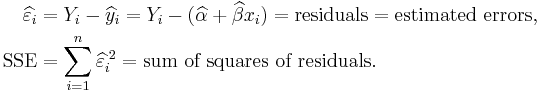
Then  is given by:
is given by:
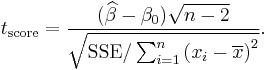
Independent two-sample t-test
Equal sample sizes, equal variance
This test is only used when both:
- the two sample sizes (that is, the number, n, of participants of each group) are equal;
- it can be assumed that the two distributions have the same variance.
Violations of these assumptions are discussed below.
The t statistic to test whether the means are different can be calculated as follows:
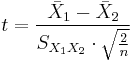
where
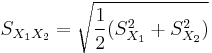
Here 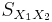 is the grand standard deviation (or pooled standard deviation), 1 = group one, 2 = group two. The denominator of t is the standard error of the difference between two means.
is the grand standard deviation (or pooled standard deviation), 1 = group one, 2 = group two. The denominator of t is the standard error of the difference between two means.
For significance testing, the degrees of freedom for this test is 2n − 2 where n is the number of participants in each group.
Unequal sample sizes, equal variance
This test is used only when it can be assumed that the two distributions have the same variance. (When this assumption is violated, see below.) The t statistic to test whether the means are different can be calculated as follows:
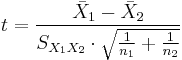
where
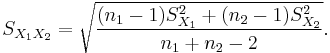
Note that the formulae above are generalizations of the case where both samples have equal sizes (substitute n for n1 and n2).
is an estimator of the common standard deviation of the two samples: it is defined in this way so that its square is an unbiased estimator of the common variance whether or not the population means are the same. In these formulae, n = number of participants, 1 = group one, 2 = group two. n − 1 is the number of degrees of freedom for either group, and the total sample size minus two (that is, n1 + n2 − 2) is the total number of degrees of freedom, which is used in significance testing.
Unequal sample sizes, unequal variance
This test also known as Welch's t-test is used only when the two population variances are assumed to be different (the two sample sizes may or may not be equal) and hence must be estimated separately. The t statistic to test whether the population means are different can be calculated as follows:
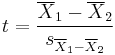
where
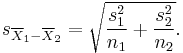
Where s2 is the unbiased estimator of the variance of the two samples, n = number of participants, 1 = group one, 2 = group two. Note that in this case, 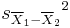 is not a pooled variance. For use in significance testing, the distribution of the test statistic is approximated as being an ordinary Student's t distribution with the degrees of freedom calculated using
is not a pooled variance. For use in significance testing, the distribution of the test statistic is approximated as being an ordinary Student's t distribution with the degrees of freedom calculated using
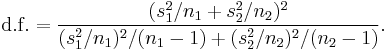
This is called the Welch–Satterthwaite equation. Note that the true distribution of the test statistic actually depends (slightly) on the two unknown variances: see Behrens–Fisher problem.
Dependent t-test for paired samples
This test is used when the samples are dependent; that is, when there is only one sample that has been tested twice (repeated measures) or when there are two samples that have been matched or "paired". This is an example of a paired difference test.
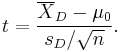
For this equation, the differences between all pairs must be calculated. The pairs are either one person's pre-test and post-test scores or between pairs of persons matched into meaningful groups (for instance drawn from the same family or age group: see table). The average (XD) and standard deviation (sD) of those differences are used in the equation. The constant μ0 is non-zero if you want to test whether the average of the difference is significantly different from μ0. The degree of freedom used is n − 1.
| Example of repeated measures | |||
| Number | Name | Test 1 | Test 2 |
|---|---|---|---|
| 1 | Mike | 35% | 67% |
| 2 | Melanie | 50% | 46% |
| 3 | Melissa | 90% | 86% |
| 4 | Mitchell | 78% | 91% |
| Example of matched pairs | |||
| Pair | Name | Age | Test |
|---|---|---|---|
| 1 | John | 35 | 250 |
| 1 | Jane | 36 | 340 |
| 2 | Jimmy | 22 | 460 |
| 2 | Jessy | 21 | 200 |
Worked examples
Let A1 denote a set obtained by taking 6 random samples out of a larger set:
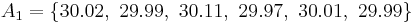
and let A2 denote a second set obtained similarly:
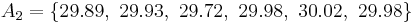
These could be, for example, the weights of screws that were chosen out of a bucket.
We will carry out tests of the null hypothesis that the means of the populations from which the two samples were taken are equal.
The difference between the two sample means, each denoted by 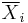 , which appears in the numerator for all the two-sample testing approaches discussed above, is
, which appears in the numerator for all the two-sample testing approaches discussed above, is
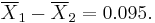
The sample standard deviations for the two samples are approximately 0.05 and 0.11, respectively. For such small samples, a test of equality between the two population variances would not be very powerful. Since the sample sizes are equal, the two forms of the two sample t-test will perform similarly in this example.
Unequal variances
If the approach for unequal variances (discussed above) is followed, the results are
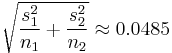
and
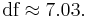
The test statistic is approximately 1.959. The two-tailed test p-value is approximately 0.091 and the one-tailed p-value is approximately 0.045.
Equal variances
If the approach for equal variances (discussed above) is followed, the results are
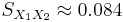
and
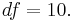
Since the sample sizes are equal (both are 6), the test statistic is again approximately equal to 1.959. Since the degrees of freedom is different from what it is in the unequal variances test, the p-values will differ slightly from what was found above. Here, the two-tailed p-value is approximately 0.078, and the one-tailed p-value is approximately 0.039. Thus if there is good reason to believe that the population variances are equal, the results become somewhat more suggestive of a difference in the mean weights for the two populations of screws.
Alternatives to the t-test for location problems
The t-test provides an exact test for the equality of the means of two normal populations with unknown, but equal, variances. (The Welch's t-test is a nearly-exact test for the case where the data are normal but the variances may differ.) For moderately large samples and a one tailed test, the t is relatively robust to moderate violations of the normality assumption.[9]
For exactness, the t-test and Z-test require normality of the sample means, and the t-test additionally requires that the sample variance follows a scaled χ2 distribution, and that the sample mean and sample variance be statistically independent. Normality of the individual data values is not required if these conditions are met. By the central limit theorem, sample means of moderately large samples are often well-approximated by a normal distribution even if the data are not normally distributed. For non-normal data, the distribution of the sample variance may deviate substantially from a χ2 distribution. However, if the sample size is large, Slutsky's theorem implies that the distribution of the sample variance has little effect on the distribution of the test statistic. If the data are substantially non-normal and the sample size is small, the t-test can give misleading results. See Location test for Gaussian scale mixture distributions for some theory related to one particular family of non-normal distributions.
When the normality assumption does not hold, a non-parametric alternative to the t-test can often have better statistical power. For example, for two independent samples when the data distributions are asymmetric (that is, the distributions are skewed) or the distributions have large tails, then the Wilcoxon Rank Sum test (also known as the Mann-Whitney U test) can have three to four times higher power than the t-test.[9][10][11] The nonparametric counterpart to the paired samples t test is the Wilcoxon signed-rank test for paired samples. For a discussion on choosing between the t and nonparametric alternatives, see Sawilowsky.[12]
One-way analysis of variance generalizes the two-sample t-test when the data belong to more than two groups.
Multivariate testing
A generalization of Student's t statistic, called Hotelling's T-square statistic, allows for the testing of hypotheses on multiple (often correlated) measures within the same sample. For instance, a researcher might submit a number of subjects to a personality test consisting of multiple personality scales (e.g. the Big Five). Because measures of this type are usually highly correlated, it is not advisable to conduct separate univariate t-tests to test hypotheses, as these would neglect the covariance among measures and inflate the chance of falsely rejecting at least one hypothesis (Type I error). In this case a single multivariate test is preferable for hypothesis testing. Hotelling's T 2 statistic follows a T 2 distribution. However, in practice the distribution is rarely used, and instead converted to an F distribution.
One-sample T 2 test
For a one-sample multivariate test, the hypothesis is that the mean vector (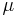 ) is equal to a given vector (
) is equal to a given vector (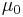 ). The test statistic is defined as:
). The test statistic is defined as:
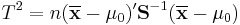
where n is the sample size, 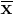 is the vector of column means and
is the vector of column means and 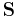 is a
is a 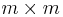 sample covariance matrix.
sample covariance matrix.
Two-sample T 2 test
For a two-sample multivariate test, the hypothesis is that the mean vectors (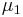 ,
, 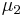 ) of two samples are equal. The test statistic is defined as
) of two samples are equal. The test statistic is defined as
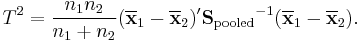
Implementations
Most spreadsheet programs and statistics packages, such as QtiPlot, OpenOffice.org Calc, Microsoft Excel, SAS, SPSS, Stata, DAP, gretl, R, Python ([1]), PSPP, and Minitab, include implementations of Student's t-test.
See also
Further reading
- Boneau, C. Alan (1960). "The effects of violations of assumptions underlying the t test". Psychological Bulletin 57 (1): 49–64. doi:10.1037/h0041412
- Edgell, Stephen E., & Noon, Sheila M (1984). "Effect of violation of normality on the t test of the correlation coefficient". Psychological Bulletin 95 (3): 576–583. doi:10.1037/0033-2909.95.3.576.
Notes
- ^ Richard Mankiewicz, The Story of Mathematics (Princeton University Press), p.158.
- ^ a b O'Connor, John J.; Robertson, Edmund F., "Student's t-test", MacTutor History of Mathematics archive, University of St Andrews, http://www-history.mcs.st-andrews.ac.uk/Biographies/Gosset.html.
- ^ Fisher Box, Joan (1987). "Guinness, Gosset, Fisher, and Small Samples". Statistical Science 2 (1): 45–52. doi:10.1214/ss/1177013437. JSTOR 2245613.
- ^ Raju TN (2005). "William Sealy Gosset and William A. Silverman: two "students" of science". Pediatrics 116 (3): 732–5. doi:10.1542/peds.2005-1134. PMID 16140715.
- ^ a b Fadem, Barbara (2008). High-Yield Behavioral Science (High-Yield Series). Hagerstwon, MD: Lippincott Williams & Wilkins. ISBN 0-7817-8258-9.
- ^ Zimmerman, Donald W. (1997). "A Note on Interpretation of the Paired-Samples t Test". Journal of Educational and Behavioral Statistics 22 (3): 349–360. JSTOR 1165289.
- ^ Markowski, Carol A; Markowski, Edward P. (1990). "Conditions for the Effectiveness of a Preliminary Test of Variance". The American Statistician 44 (4): 322–326. doi:10.2307/2684360. JSTOR 2684360.
- ^ David, HA; Gunnink, Jason L (1997). "The Paired t Test Under Artificial Pairing". The American Statistician 51 (1): 9–12. doi:10.2307/2684684. JSTOR 2684684.
- ^ a b Sawilowsky S., Blair R. C. (1992). "A more realistic look at the robustness and type II error properties of the t test to departures from population normality". Psychological Bulletin 111 (2): 353–360. doi:10.1037/0033-2909.111.2.352.
- ^ Blair, R. C.; Higgins, J.J. (1980). "A comparison of the power of Wilcoxon’s rank-sum statistic to that of Student’s t statistic under various nonnormal distributions.". Journal of Educational Statistics 5 (4): 309–334. doi:10.2307/1164905. JSTOR 1164905.
- ^ Fay, MP; Proschan, MA (2010). "Wilcoxon-Mann-Whitney or t-test? On assumptions for hypothesis tests and multiple interpretations of decision rules". Statistics Surveys 4: 1–39. doi:10.1214/09-SS051. PMC 2857732. PMID 20414472. http://www.i-journals.org/ss/viewarticle.php?id=51.
- ^ Sawilowsky S (2005). "Misconceptions leading to choosing the t test over the Wilcoxon Mann-Whitney U test for shift in location parameter". Journal of Modern Applied Statistical Methods 4 (2): 598–600.
References
- O'Mahony, Michael (1986). Sensory Evaluation of Food: Statistical Methods and Procedures. CRC Press. pp. 487. ISBN 0-824-77337-3.
- Press, William H.; Saul A. Teukolsky, William T. Vetterling, Brian P. Flannery (1992). Numerical Recipes in C: The Art of Scientific Computing. Cambridge University Press. pp. p. 616. ISBN 0-521-43108-5. http://www.nr.com/.
External links
Online calculators
- Online T-Test Calculator
- 2 Sample T-Test Calculator
- GraphPad's Paired/Unpaired/Welch T-Test Calculator
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||