SimRank
SimRank is a general similarity measure, based on a simple and intuitive graph-theoretic model. SimRank is applicable in any domain with object-to-object relationships, that measures similarity of the structural context in which objects occur, based on their relationships with other objects. Effectively, SimRank is a measure that says "two objects are similar if they are related to similar objects."
Contents |
Introduction
Many applications require a measure of "similarity" between objects. One obvious example is the "find-similar-document" query, on traditional text corpora or the World-Wide Web. More generally, a similarity measure can be used to cluster objects, such as for collaborative filtering in a recommender system, in which “similar” users and items are grouped based on the users’ preferences.
Various aspects of objects can be used to determine similarity, usually depending on the domain and the appropriate definition of similarity for that domain. In a document corpus, matching text may be used, and for collaborative filtering, similar users may be identified by common preferences. SimRank is a general approach that exploits the object-to-object relationships found in many domains of interest. On the Web, for example, two pages are related if there are hyperlinks between them. A similar approach can be applied to scientific papers and their citations, or to any other document corpus with cross-reference information. In the case of recommender systems, a user’s preference for an item constitutes a relationship between the user and the item. Such domains are naturally modeled as graphs, with nodes representing objects and edges representing relationships.
The intuition behind the SimRank algorithm is that, in many domains, similar objects are related to similar objects. More precisely, objects 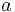 and
and 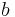 are similar if they are related to objects
are similar if they are related to objects 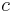 and
and 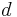 , respectively, and and are themselves similar. The base case is that objects are similar to themselves [1].
, respectively, and and are themselves similar. The base case is that objects are similar to themselves [1].
It is important to note that SimRank is a general algorithm that determines only the similarity of structural context. SimRank applies to any domain where there are enough relevant relationships between objects to base at least some notion of similarity on relationships. Obviously, similarity of other domain-specific aspects are important as well; these can — and should be combined with relational structural-context similarity for an overall similarity measure. For example, for Web pages SimRank can be combined with traditional textual similarity; the same idea applies to scientific papers or other document corpora. For recommender systems, there may be built-in known similarities between items (e.g., both computers, both clothing, etc.), as well as similarities between users (e.g., same gender, same spending level). Again, these similarities can be combined with the similarity scores that are computed based on preference patterns, in order to produce an overall similarity measure.
Basic SimRank equation
For a node 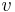 in a graph, we denote by
in a graph, we denote by 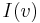 and
and 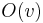 the set of in-neighbors and out-neighbors of , respectively. Individual in-neighbours are denoted as
the set of in-neighbors and out-neighbors of , respectively. Individual in-neighbours are denoted as 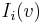 , for
, for 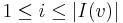 , and individual out-neighbors are denoted as
, and individual out-neighbors are denoted as 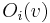 , for
, for 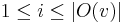 .
.
Let us denote the similarity between objects and by ![s(a, b) \in [0, 1]](/2012-wikipedia_en_all_nopic_01_2012/I/95c99a86741d9e961c4b1f938418195b.png) . Following the earlier motivation, a recursive equation is written for
. Following the earlier motivation, a recursive equation is written for 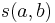 . If
. If 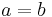 then is defined to be
then is defined to be 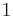 . Otherwise,
. Otherwise,
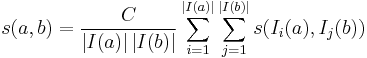
where 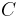 is a constant between
is a constant between 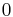 and . A slight technicality here is that either or may not have any in-neighbors. Since there is no way to infer any similarity between and in this case, similarity is set to
and . A slight technicality here is that either or may not have any in-neighbors. Since there is no way to infer any similarity between and in this case, similarity is set to 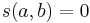 , so the summation in the above equation is defined to be when
, so the summation in the above equation is defined to be when 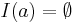 or
or 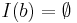 .
.
Computing SimRank
A solution to the SimRank equations for a graph 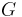 can be reached by iteration to a fixed-point. Let
can be reached by iteration to a fixed-point. Let  be the number of nodes in . For each iteration
be the number of nodes in . For each iteration  , we can keep
, we can keep 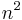 entries
entries 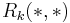 of length , where
of length , where 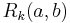 gives the score between and on iteration . We successively compute
gives the score between and on iteration . We successively compute 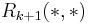 based on . We start with
based on . We start with 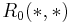 where each
where each 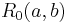 is a lower bound on the actual SimRank score :
is a lower bound on the actual SimRank score :
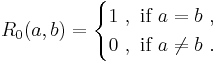
To compute 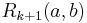 from , we use the basic SimRank equation to get:
from , we use the basic SimRank equation to get:
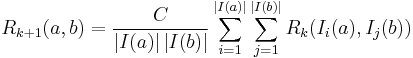
for 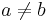 , and
, and 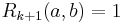 for . That is, on each iteration
for . That is, on each iteration 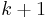 , we update the similarity of
, we update the similarity of 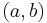 using the similarity scores of the neighbours of from the previous iteration according to the basic SimRank equation. The values are nondecreasing as increases. It was shown in [1] that the values converge to limits satisfying the basic SimRank equation, the SimRank scores
using the similarity scores of the neighbours of from the previous iteration according to the basic SimRank equation. The values are nondecreasing as increases. It was shown in [1] that the values converge to limits satisfying the basic SimRank equation, the SimRank scores 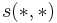 , i.e., for all
, i.e., for all 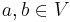 ,
, 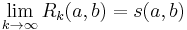 .
.
The original SimRank proposal suggested choosing the decay factor 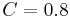 and a fixed number
and a fixed number 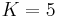 of iterations to perform. However, the recent research [2] showed that the given values for and
of iterations to perform. However, the recent research [2] showed that the given values for and 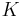 generally imply relatively low accuracy of iteratively computed SimRank scores. For guaranteeing more accurate computation results, the latter paper suggests either using a smaller decay factor (in particular,
generally imply relatively low accuracy of iteratively computed SimRank scores. For guaranteeing more accurate computation results, the latter paper suggests either using a smaller decay factor (in particular, 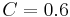 ) or taking more iterations.
) or taking more iterations.
Further research on SimRank
- Fogaras and Racz [3] suggested speeding up SimRank computation through probabilistic computation using the Monte Carlo method.
- Antonellis et al. [4] extended SimRank equations to take into consideration (i) evidence factor for incident nodes and (ii) link weights.
- Lizorkin et al. [2] proposed several optimization techniques for speeding up SimRank iterative computation.
See also
Citations
- ^ a b G. Jeh and J. Widom. SimRank: a measure of structural-context similarity. In KDD'02: Proceedings of the eighth ACM SIGKDD international conference on Knowledge discovery and data mining, pages 538-543. ACM Press, 2002. [1]
- ^ a b D. Lizorkin, P. Velikhov, M. Grinev and D. Turdakov. Accuracy Estimate and Optimization Techniques for SimRank Computation. In VLDB '08: Proceedings of the 34th International Conference on Very Large Data Bases, pages 422--433. [2]
- ^ D. Fogaras and B. Racz. Scaling link-based similarity search. In WWW '05: Proceedings of the 14th international conference on World Wide Web, pages 641--650, New York, NY, USA, 2005. ACM. [3]
- ^ I. Antonellis, H. Garcia-Molina and C.-C. Chang. Simrank++: Query Rewriting through Link Analysis of the Click Graph. In VLDB '08: Proceedings of the 34th International Conference on Very Large Data Bases, pages 408--421. [4]