Running key cipher
In classical cryptography, the running key cipher is a type of polyalphabetic substitution cipher in which a text, typically from a book, is used to provide a very long keystream. Usually, the book to be used would be agreed ahead of time, while the passage to use would be chosen randomly for each message and secretly indicated somewhere in the message.
Contents |
Example
Suppose we have agreed to use The C Programming Language (1978 edition) as our text, and we are using the tabula recta as our tableau. We need to send the message 'Flee at once'.
First, we choose a starting point. Let us choose page 63, line 1:
- errors can occur in several places. A label has...
We write out the running key under our plaintext:
| Plaintext: | f | l | e | e | a | t | o | n | c | e |
| Running key: | E | R | R | O | R | S | C | A | N | O |
| Ciphertext: | J | C | V | S | R | L | Q | N | P | S |
And send the message 'JCVSR LQNPS'. However, unlike a Vigenère cipher, if we have to extend our message, we don't repeat the key; we just continue on from the key text. So suppose we need a longer message, like: 'Flee at once. We are discovered'. Then we just continue as before:
| Plaintext: | f | l | e | e | a | t | o | n | c | e | w | e | a | r | e | d | i | s | c | o | v | e | r | e | d |
| Running key: | E | R | R | O | R | S | C | A | N | O | C | C | U | R | I | N | S | E | V | E | R | A | L | P | L |
| Ciphertext: | J | C | V | S | R | L | Q | N | P | S | Y | G | U | I | M | Q | A | W | X | S | M | E | C | T | O |
Next we need to tell the recipient where to find the running key for this message. In this case, we've decided to make up a fake block of five ciphertext characters, with three denoting the page number, and two the line number, using A=0, B=1 etc. to encode digits. Such a block is called an indicator block. The indicator block will be inserted as the second last of each message. (Of course, many other schemes are possible for hiding indicator blocks). Thus page 63, line 1 encodes as 'AGDAB' (06301).
Finally we can send the message 'JCVSR LQNPS YGUIM QAWXS AGDAB MECTO'.
Variants
Modern variants of the running key cipher often replace the traditional tabula recta with bitwise exclusive or, operate on whole bytes rather than alphabetic letters, and derive their running keys from large files. Apart from possibly greater entropy density of the files, and the ease of automation, there is little practical difference between such variants and traditional methods.
Permutation generated running keys
A more compact running key can be used if one combinatorially generates text using several start pointers (or combination rules). For example, rather than start at one place (a single pointer), one could use several start pointers and xor together the streams to form a new running key, similarly skip rules can be used. What is exchanged then is a series of pointers to the running key book and/or a series of rules for generating the new permuted running key from the initial key text. (These may be exchanged via public key encryption or in person. They may also be changed frequently without changing the running key book).
Cyphertext appearing to be plaintext
Traditional cyphertext appears to be quite different than plaintext. To address this problem, one variant outputs "plaintext" words instead of "plaintext" letters as the cyphertext output. This is done by creating an "alphabet" of words (in practice multiple words can correspond to each cypher-text output character). The result is a cyphertext output which looks like a long sequence of plaintext words (the process can be nested). Theoretically, this is no different than using standard cyphertext characters as output. However, plaintext-looking cyphertext may result in a "human in the loop" to try to mistakenly interpret it as decoded plaintext.
An example would be BDA (Berkhoff deflater algorithm), each cyphertext output character has at least one noun, verb, adjective and adverb associated with it. (E.g. (at least) one of each for every ASCII character). Grammatically plausible sentences are generated as cyphertext output. Decryption requires mapping the words back to ASCII, and then decrypting the characters to the real plaintext using the running key. Nested-BDA will run the output through the reencryption process several times, producing several layers of "plaintext-looking" cyphertext - each one potentially requiring "human-in-the-loop" to try to interpret its non-existent semantic meaning.
Security
If the running key is truly random, never reused, and kept secret, the result is a one-time pad, a method that provides perfect secrecy (reveals no information about the plaintext). However, if (as usual) the running key is a block of text in a natural language, security actually becomes fairly poor, since that text will have non-random characteristics which can be used to aid cryptanalysis. As a result, the entropy per character of both plaintext and running key is low, and the combining operation is easily inverted.
To attack the cipher, a cryptanalyst runs guessed probable plaintexts along the ciphertext, subtracting them out from each possible position. When the result is a chunk of something intelligible, there is a high probability that the guessed plain text is correct for that position (as either actual plaintext, or part of the running key). The 'chunk of something intelligible' can then often be extended at either end, thus providing even more probable plaintext - which can in turn be extended, and so on. Eventually it is likely that the source of the running key will be identified, and the jig is up.
There are several ways to improve the security. The first and most obvious is to use a secret mixed alphabet tableau instead of a tabula recta. This does indeed greatly complicate matters but it is not a complete solution. Pairs of plaintext and running key characters are far more likely to be high frequency pairs such as 'EE' rather than, say, 'QQ'. The skew this causes to the output frequency distribution is smeared by the fact that it is quite possible that 'EE' and 'QQ' map to the same ciphertext character, but nevertheless the distribution is not flat. This may enable the cryptanalyst to deduce part of the tableau, then proceed as before (but with gaps where there are sections missing from the reconstructed tableau).
Another possibility is to use a key text that has more entropy per character than typical English. For this purpose, the KGB advised agents to use documents like almanacs and trade reports, which often contain long lists of random-looking numbers.
Another problem is that the keyspace is surprisingly small. Suppose that there are 100 million key texts that might plausibly be used, and that on average each has 11 thousand possible starting positions. To an opponent with a massive collection of possible key texts, this leaves possible a brute force search of the order of 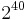 , which by computer cryptography standards is a relatively easy target. (See permutation generated running keys above for an approach to this problem).
, which by computer cryptography standards is a relatively easy target. (See permutation generated running keys above for an approach to this problem).
Confusion
Because both ciphers classically employed novels as part of their key material, many sources confuse the book cipher and the running key cipher. They are really only very distantly related. The running key cipher is a polyalphabetic substitution, the book cipher is a homophonic substitution. Perhaps the distinction is most clearly made by the fact that a running cipher would work best of all with a book of random numbers, whereas such a book (containing no text) would be useless for a book cipher.
See also
|
||||||||||||||||||||||||||