Power transform
In statistics, the power transform is from a family of functions that are applied to create a rank-preserving transformation of data using power functions. This is a useful data (pre)processing technique used to stabilize variance, make the data more normal distribution-like, improve the Pearson correlation between variables and for other data stabilization procedures. The Box–Cox transformation, by statisticians George E. P. Box and David Cox, is one particular way of parameterising a power transform that has advantageous properties.
Contents |
Definition
The power transformation is defined as a continuously varying function, with respect to the power parameter λ, in a piece-wise function form that makes it continuous at the point of singularity (λ = 0). For data vectors (y1,..., yn) in which each yi > 0, the power transform is
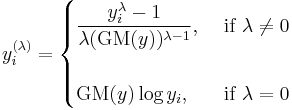
where
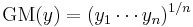
is the geometric mean of the observations y1, ..., yn.
The inclusion of the (λ − 1)th power of the geometric mean in the denominator implies that the units of measurement do not change as λ changes. That makes it possible to compare sums of squares of residuals and choose the value of λ that minimizes that sum.
The value at Y = 1 for any λ is 0, and the derivative with respect to Y there is 1 for any λ. Sometimes Y is a version of some other variable scaled to give Y = 1 at some sort of average value.
The transformation is a power transformation, but done in such a way as to make it continuous with the parameter λ at λ = 0. It has proved popular in regression analysis, including econometrics.
Box and Cox also proposed a more general form of the transformation that incorporates a shift parameter.
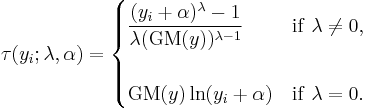
If τ(Y, λ, α) follows a truncated normal distribution, then Y is said to follow a Box–Cox distribution.
Box-Cox transformation
The power transformation above is used by box-cox for calculating the profile likelihood function for &lambda. However, the box-cox transformation itself is defined as
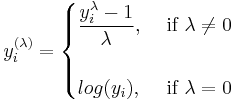
Use of the power transform
- Power transforms are ubiquitously used in various fields. For example, multi-resolution and wavelet analysis, statistical data analysis, medical research, modeling of physical processes, geochemical data analysis, epidemiology and many other clinical, environmental and social research areas.
Example
The BUPA liver data set contains data on liver enzymes ALT and γGT. The data can be found via the classic data sets page. Suppose we are interested in using log(γGT) to predict ALT. A plot of the data appears in panel (a) of the figure. There appears to be non-constant variance, and a Box–Cox transformation might help.
The log-likelihood of the power parameter appears in panel (b). The horizontal reference line is at a distance of χ12/2 from the maximum and can be used to read off an approximate 95% confidence interval for λ. It appears as though a value close to zero would be good, so we take logs.
Possibly, the transformation could be improved by adding a shift parameter to the log transformation. Panel (c) of the figure shows the log-likelihood. In this case, the maximum of the likelihood is close to zero suggesting that a shift parameter is not needed. The final panel shows the transformed data with a superimposed regression line.
Note that although Box–Cox transformations can make big improvements in model fit, there are some issues that the transformation cannot help with. In the current example, the data are rather heavy-tailed so that the assumption of normality is not realistic and a robust regression approach leads to a more precise model.
Econometric application
Economists often characterize production relationships by some variant of the Box–Cox transformation.
Consider a common representation of production Q as dependent on services provided by a capital stock K and by labor hours N:
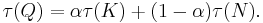
Solving for Q by inverting the Box–Cox transformation we find
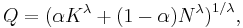
which is known as the constant elasticity of substitution (CES) production function.
The CES production function is a homogeneous function of degree one.
When λ = 1, this produces the linear production function:
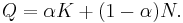
When λ → 0 this produces the famous Cobb-Douglas production function:
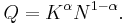
Activities and demonstrations
The SOCR resource pages contain a number of hands-on interactive activities demonstrating the Box–Cox (Power) Transformation using Java applets and charts. These directly illustrate the effects of this transform on Qq plots, X-Y scatterplots, time-series plots and histograms.
References
- Box, George E. P.; Cox, D. R. (1964). "An analysis of transformations". Journal of the Royal Statistical Society, Series B 26 (2): 211–252. JSTOR 2984418. MR192611.
- Carroll, RJ and Ruppert, D. On prediction and the power transformation family. Biometrika 68: 609–615.
- DeGroot, M. H. (1987). "A Conversation with George Box". Statistical Science 2 (3): 239–258. doi:10.1214/ss/1177013223.
- Handelsman, DJ. Optimal Power Transformations for Analysis of Sperm Concentration and Other Semen Variables. Journal of Andrology, Vol. 23, No. 5, September/October 2002.
- Gluzman, S and Yukalov, VI. Self-similar power transforms in extrapolation problems. Journal of Mathematical Chemistry, Volume 39, Number 1 / January, 2006, DOI 10.1007/s10910-005-9003-7, 47–56.
- Howarth, RJ and Earle, SAM. Application of a generalized power transformation to geochemical data Journal Mathematical Geology, Volume 11, Number 1 / February, 1979, DOI 10.1007/BF01043245, pages 45–62.
- Peters, JL Rushton, L, Sutton, AJ, Jones, DR, Abrams, KR, Mugglestone, MA. (2005) Bayesian methods for the cross-design synthesis of epidemiological and toxicological evidence. Journal of the Royal Statistical Society: Series C (Applied Statistics) 54 (1), 159–172, doi:10.1111/j.1467-9876.2005.00476.x
External links
- Nishii, R. (2001), "Box–Cox transformation", in Hazewinkel, Michiel, Encyclopedia of Mathematics, Springer, ISBN 978-1556080104, http://www.encyclopediaofmath.org/index.php?title=B/b110790 (fixed link)