P/poly
In computational complexity theory, P/poly is the complexity class of languages recognized by a polynomial-time Turing machine with a polynomial-bounded advice function. It is also equivalently defined as the class PSIZE of languages that have a polynomial-size circuits.[1][2] This means that the machine that recognizes a language may use a different advice function or use a different circuit depending on the length of the input, and that the advice function or circuit will vary only on the size of the input.
For example, the popular Miller-Rabin primality test can be formulated as a P/poly algorithm: the "advice" is a list of candidate a values to test. It is possible to precompute a list of at most n values such that every composite n-bit number will be certain to have a witness a in the list. For example, if we're testing a 32-bit number, it is enough to test a = 2, 7, and 61.[3] This follows from the fact that for each composite n, 3/4s of all possible a values are witnesses; a simple counting argument similar to the one in the proof that BPP in P/poly below shows that there exists a suitable list of a values for every input size, although finding it may be expensive.
Note that P/poly, unlike other polynomial-time classes such as P or BPP, is not generally considered a practical class for computing. Indeed, it contains every undecidable unary language, none of which can be solved in general by real computers. On the other hand, if the input length is bounded by a relatively small number and the advice strings are short, it can be used to model practical algorithms with a separate expensive preprocessing phase and a fast processing phase, as in the example above.
Contents |
Importance of P/poly
P/poly is an important class for several reasons. For theoretical computer science, there are several important properties that depend on P/poly:
- If NP ⊆ P/poly then PH (the polynomial hierarchy) collapses to
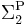 . This result is the Karp–Lipton theorem; furthermore, NP ⊆ P/poly implies AM = MA [4]
. This result is the Karp–Lipton theorem; furthermore, NP ⊆ P/poly implies AM = MA [4] - If PSPACE ⊆ P/poly then PSPACE =
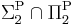 , even PSPACE = MA.
, even PSPACE = MA.
- Proof: Consider a language L from PSPACE. It is known that there exists an interactive proof system for L, where actions of the prover can be carried out by a PSPACE machine. By assumption, the prover can be replaced by a polynomial-size circuit. Therefore, L has a MA protocol: Merlin sends the circuit as proof, and Arthur can simulate the IP protocol himself without any additional help.
- If P#P ⊆ P/poly then P#P = MA. [5] The proof is similar to above, based on an interactive protocol for permanent and #P-completeness of permanent.
- If EXPTIME ⊆ P/poly then EXPTIME = (Meyer's theorem), even EXPTIME = MA.
- If NEXPTIME ⊆ P/poly then NEXPTIME = EXPTIME, even NEXPTIME = MA. Conversely, NEXPTIME = MA implies NEXPTIME ⊆ P/poly[6]
- If EXPNP ⊆ P/poly then EXPNP = (Buhrman, Homer) [7]
One of the most interesting reasons that P/poly is important is the property that if NP is not a subset of P/poly, then P ≠ NP. This observation was the center of many attempts to prove P ≠ NP.
P/poly is also used in the field of cryptography. Security is often defined 'against' P/poly adversaries. Besides including most practical models of computation like BPP, this also admits the possibility that adversaries can do heavy precomputation for inputs up to a certain length, as in the construction of rainbow tables.
Although not all languages in P/poly are sparse languages, there is a polynomial-time Turing reduction from any language in P/poly to a sparse language.[8]
Adleman's theorem
Adleman's theorem, proved by Leonard Adleman, states that BPP ⊆ P/poly, where BPP is the set of problems solvable with randomized algorithms with two-sided error in polynomial time.[9] Variants of the theorem show that BPL is contained in L/poly and AM is contained in NP/poly.
Proof
Let L be a language in BPP, and let M(x,r) be a polynomial-time algorithm that decides L with error ≤ 1/3 (where x is the input string and r is a set of random bits).
Construct a new machine M'(x,R), which runs M 18n times (where n is the input length and R is a sequence of 18n independently random rs). Thus, M' is also polynomial-time, and has an error probability ≤ 1/en by Chernoff's bound (see BPP). If we can fix R then we obtain an algorithm that is deterministic.
If Bad(x) is defined as {R: M'(x,R) is incorrect}, we have:
![\forall x\, \mbox{Prob}_R[R \in \mbox{Bad}(x)] \leq \frac{1}{e^n}.](/2012-wikipedia_en_all_nopic_01_2012/I/29c66b9d279091935ce2eb103b9cb4c0.png)
The input size is n, so there are 2n possible inputs. Thus, the probability that a random R is bad for at least one input x is
![\mbox{Prob}_R [\exists x\,R \in \mbox{Bad}(x)] \leq \frac{2^n}{e^n} < 1.](/2012-wikipedia_en_all_nopic_01_2012/I/cfec6b46787e6e6fa9fdec2332837e5f.png)
In words, the probability that R is bad for some x is less than 1, therefore there must be an R that is good for all x. Take such an R to be the advice string in our P/poly algorithm.
See also
- L/poly, a logarithmic space analogue of P/poly that captures the complexity of polynomial size branching programs
References
- ^ Lutz, Jack H.; Schmidt, William J. (1993), "Circuit size relative to pseudorandom oracles", Theor. Comput. Sci. (Essex, UK: Elsevier Science Publishers Ltd.) 107 (1): 95–120, ISSN 0304-3975
- ^ Lecture notes on computational complexity by Peter Bro Miltersen
- ^ Finding primes & proving primality
- ^ If NP has Polynomial-Size Circuits, then MA = AM
- ^ Non-deterministic Exponential Time has Two-Prover Interactive Protocols
- ^ In Search of an Easy Witness: Exponential Time vs. Probabilistic Polynomial Time
- ^ A Note on the Karp-Lipton Collapse for the Exponential Hierarchy
- ^ Jin-Yi Cai. Lecture 11: P/poly, Sparse Sets, and Mahaney's Theorem. CS 810: Introduction to Complexity Theory. The University of Wisconsin–Madison. September 18, 2003.
- ^ Adleman, L. M. (1978), "Two theorems on random polynomial time", Proceedings of the Nineteenth Annual IEEE Symposium on Foundations of Computer Science, pp. 75–83, doi:10.1109/SFCS.1978.37
|
|||||||||||||||||