Multicollinearity
Multicollinearity is a statistical phenomenon in which two or more predictor variables in a multiple regression model are highly correlated. In this situation the coefficient estimates may change erratically in response to small changes in the model or the data. Multicollinearity does not reduce the predictive power or reliability of the model as a whole, at least within the sample data themselves; it only affects calculations regarding individual predictors. That is, a multiple regression model with correlated predictors can indicate how well the entire bundle of predictors predicts the outcome variable, but it may not give valid results about any individual predictor, or about which predictors are redundant with respect to others.
A high degree of multicollinearity can also cause computer software packages to be unable to perform the matrix inversion that is required for computing the regression coefficients, or it may make the results of that inversion inaccurate.
Note that in statements of the assumptions underlying regression analyses such as ordinary least squares, the phrase "no multicollinearity" is sometimes used to mean the absence of perfect multicollinearity, which is an exact (non-stochastic) linear relation among the regressors.
Contents |
Definition
Collinearity is a linear relationship between two explanatory variables. Two variables are perfectly collinear if there is an exact linear relationship between the two. For example, 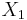 and
and 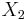 are perfectly collinear if there exist parameters
are perfectly collinear if there exist parameters 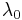 and
and 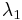 such that, for all observations i, we have
such that, for all observations i, we have
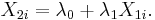
Multicollinearity refers to a situation in which two or more explanatory variables in a multiple regression model are highly linearly related. We have perfect multicollinearity if, for example as in the equation above, the correlation between two independent variables is equal to 1 or -1. In practice, we rarely face perfect multicollinearity in a data set. More commonly, the issue of multicollinearity arises when there is a strong linear relationship among two or more independent variables.
Mathematically, a set of variables is perfectly multicollinear if there exist one or more exact linear relationships among some of the variables. For example, we may have
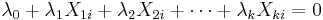
holding for all observations i, where 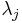 are constants and
are constants and 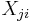 is the ith observation on the jth explanatory variable. We can explore one issue caused by multicollinearity by examining the process of attempting to obtain estimates for the parameters of the multiple regression equation
is the ith observation on the jth explanatory variable. We can explore one issue caused by multicollinearity by examining the process of attempting to obtain estimates for the parameters of the multiple regression equation
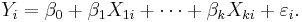
The ordinary least squares estimates involve inverting the matrix
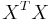
where
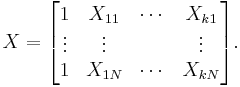
If there is an exact linear relationship (perfect multicollinearity) among the independent variables, the rank of X (and therefore of XTX) is less than k+1, and the matrix XTX will not be invertible.
In most applications, perfect multicollinearity is unlikely. An analyst is more likely to face a high degree of multicollinearity. For example, suppose that instead of the above equation holding, we have that equation in modified form with an error term 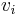 :
:
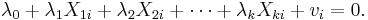
In this case, there is no exact linear relationship among the variables, but the 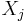 variables are nearly perfectly multicollinear if the variance of is small for some set of values for the
variables are nearly perfectly multicollinear if the variance of is small for some set of values for the 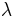 's. In this case, the matrix XTX has an inverse, but is ill-conditioned so that a given computer algorithm may or may not be able to compute an approximate inverse, and if it does so the resulting computed inverse may be highly sensitive to slight variations in the data (due to magnified effects of rounding error) and so may be very inaccurate.
's. In this case, the matrix XTX has an inverse, but is ill-conditioned so that a given computer algorithm may or may not be able to compute an approximate inverse, and if it does so the resulting computed inverse may be highly sensitive to slight variations in the data (due to magnified effects of rounding error) and so may be very inaccurate.
Detection of multicollinearity
Indicators that multicollinearity may be present in a model:
1) Large changes in the estimated regression coefficients when a predictor variable is added or deleted
2) Insignificant regression coefficients for the affected variables in the multiple regression, but a rejection of the joint hypothesis that those coefficients are all zero (using an F-test)
3) Some authors have suggested a formal detection-tolerance or the variance inflation factor (VIF) for multicollinearity:
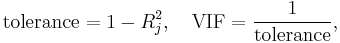
where 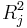 is the coefficient of determination of a regression of explanator j on all the other explanators. A tolerance of less than 0.20 or 0.10 and/or a VIF of 5 or 10 and above indicates a multicollinearity problem (but see O'Brien 2007).[1]
is the coefficient of determination of a regression of explanator j on all the other explanators. A tolerance of less than 0.20 or 0.10 and/or a VIF of 5 or 10 and above indicates a multicollinearity problem (but see O'Brien 2007).[1]
4) Condition Number Test: The standard measure of ill-conditioning in a matrix is the condition index. It will indicate that the inversion of the matrix is numerically unstable with finite-precision numbers ( standard computer floats and doubles ). This indicates the potential sensitivity of the computed inverse to small changes in the original matrix. The Condition Number is computed by finding the square root of (the maximum eigenvalue divided by the minimum eigenvalue). If the Condition Number is above 30, the regression is said to have significant multicollinearity.
5) Farrar-Glauber Test:[2] If the variables are found to be orthogonal, there is no multicollinearity; if the variables are not orthogonal, then multicollinearity is present.
Consequences of multicollinearity
As mentioned above, one consequence of a high degree of multicollinearity is that, even if the matrix XTX is invertible, a computer algorithm may be unsuccessful in obtaining an approximate inverse, and if it does obtain one it may be numerically inaccurate. But even in the presence of an accurate XTX matrix, the following consequences arise:
In the presence of multicollinearity, the estimate of one variable's impact on y while controlling for the others tends to be less precise than if predictors were uncorrelated with one another. The usual interpretation of a regression coefficient is that it provides an estimate of the effect of a one unit change in an independent variable, , holding the other variables constant. If is highly correlated with another independent variable, , in the given data set, then we only have observations for which and have a particular relationship (either positive or negative). We don't have observations for which changes independently of , so we have an imprecise estimate of the effect of independent changes in .
In some sense, the collinear variables contain the same information about the dependent variable. If nominally "different" measures actually quantify the same phenomenon then they are redundant. Alternatively, if the variables are accorded different names and perhaps employ different numeric measurement scales but are highly correlated with each other, then they suffer from redundancy.
One of the features of multicollinearity is that the standard errors of the affected coefficients tend to be large. In that case, the test of the hypothesis that the coefficient is equal to zero leads to a failure to reject the null hypothesis. However, if a simple linear regression of the dependent variable on this explanatory variable is estimated, the coefficient will be found to be significant; specifically, the analyst will reject the hypothesis that the coefficient is zero. In the presence of multicollinearity, an analyst might falsely conclude that there is no linear relationship between an independent and a dependent variable.
A principal danger of such data redundancy is that of overfitting in regression analysis models. The best regression models are those in which the predictor variables each correlate highly with the dependent (outcome) variable but correlate at most only minimally with each other. Such a model is often called "low noise" and will be statistically robust (that is, it will predict reliably across numerous samples of variable sets drawn from the same statistical population).
Multicollinearity does not actually bias results; it just produces large standard errors in the related independent variables.
In a pure statistical sense multicollinearity does not bias the results, but if there are any other problems which could introduce bias multicollinearity can multiply (by orders of magnitude) the effects of that bias. More importantly, the usual use of regression is to take coefficients from the model and then apply them to other data. If the new data differs in any way from the data that was fitted you may introduce large errors in your predictions because the pattern of multicollinearity between the independent variables is different in your new data from the data you used for your estimates.
Remedies for multicollinearity
- Make sure you have not fallen into the dummy variable trap; including a dummy variable for every category (e.g., summer, autumn, winter, and spring) and including a constant term in the regression together guarantee perfect multicollinearity.
- Try seeing what happens if you use independent subsets of your data for estimation and apply those estimates to the whole data set. Theoretically you should obtain somewhat higher variance from the smaller datasets used for estimation, but the expectation of the coefficient values should be the same. Naturally, the observed coefficient values will vary, but look at how much they vary.
- Leave the model as is, despite multicollinearity. The presence of multicollinearity doesn't affect the fitted model provided that the predictor variables follow the same pattern of multicollinearity as the data on which the regression model is based .
- Drop one of the variables. An explanatory variable may be dropped to produce a model with significant coefficients. However, you lose information (because you've dropped a variable). Omission of a relevant variable results in biased coefficient estimates for the remaining explanatory variables.
- Obtain more data, if possible. This is the preferred solution. More data can produce more precise parameter estimates (with lower standard errors), as seen from the formula in variance inflation factor for the variance of the estimate of a regression coefficient in terms of the sample size and the degree of multicollinearity.
- Mean-center the predictor variables. Mathematically this has no effect on the results from a regression. However, it can be useful in overcoming problems arising from rounding and other computational steps if a carefully designed computer program is not used.
- Standardize your independent variables. This may help reduce a false flagging of a condition index above 30.
- It has also been suggested that using the Shapley value, a game theory tool, the model could account for the effects of multicollinearity. The Shapley value assigns a value for each predictor and assesses all possible combinations of importance.[3]
- Ridge regression or principal component regression can be used.
- If the correlated explanators are different lagged values of the same underlying explanator, then a distributed lag technique can be used, imposing a general structure on the relative values of the coefficients to be estimated.
Examples of contexts in which multicollinearity arises
Survival analysis
Multicollinearity may also represent a serious issue in survival analysis. The problem is that time-varying covariates may change their value over the time line of the study. A special procedure is recommended to assess the impact of multicollinearity on the results. See Van den Poel & Larivière (2004)[4] for a detailed discussion.
Interest rates for different terms to maturity
In various situations it might be hypothesized that multiple interest rates of various terms to maturity all influence some economic decision, such as the amount of money or some other financial asset to hold, or the amount of fixed investment spending to engage in. In this case, including these various interest rates will in general create a substantial multicollinearity problem because interest rates tend to move together. If in fact each of the interest rates has its own separate effect on the dependent variable, it can be extremely difficult to separate out their effects.
References
- ^ O'Brien, Robert M. 2007. "A Caution Regarding Rules of Thumb for Variance Inflation Factors," Quality and Quantity 41(5)673-690.
- ^ Farrar Donald E. and Glauber, Robert R. 1967. "Multicollinearity in Regression Analysis: The Problem Revisited," The Review of Economics and Statistics 49(1):92-107.
- ^ Lipovestky and Conklin, 2001,"Analysis of Regression in Game Theory Approach". Applied Stochastic Models and Data Analysis 17 (2001): 319-330."
- ^ Van den Poel, Dirk, and Larivière, Bart (2004), "Attrition Analysis for Financial Services Using Proportional Hazard Models," European Journal of Operational Research, 157 (1), 196-217.