Multi-armed bandit
In statistics, particularly in the design of sequential experiments, a multi-armed bandit takes its name from a traditional slot machine (one-armed bandit). Multiple levers are considered in the motivating applications in statistics. When pulled, each lever provides a reward drawn from a distribution associated with that specific lever. The objective of the gambler is to maximize the sum of rewards earned through a sequence of lever pulls.[1][2]
In practice, multi-armed bandits have been used to model the problem of managing research projects in a large organization, like a science foundation or a pharmaceutical company. Given its fixed budget, the problem is to allocate resources among the competing projects, whose properties are only partially known now but may be better understood as time passes.[1][2]
In the early versions of the multi-armed bandit problem, the gambler has no initial knowledge about the levers. The crucial tradeoff the gambler faces at each trial is between "exploitation" of the lever that has the highest expected payoff and "exploration" to get more information about the expected payoffs of the other levers.
The multi-armed bandit is sometimes called a 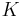 -armed bandit or
-armed bandit or 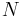 -armed bandit.
-armed bandit.
Contents |
Empirical motivation
The multi-armed bandit problem models an agent that simultaneously attempts to acquire new knowledge and to optimize its decisions based on existing knowledge. There are many practical applications:
- clinical trials investigating the effects of different experimental treatments while minimizing patient losses,[1][2][3] and
- adaptive routing efforts for minimizing delays in a network.
In these practical examples, the problem requires balancing reward maximization based on the knowledge already acquired with attempting new actions to further increase knowledge. This is known as the exploitation vs. exploration tradeoff in reinforcement learning.
The model can also be used to control dynamic allocation of resources to different projects, answering the question "which project should I work on" given uncertainty about the difficulty and payoff of each possibility.
Originally considered by Allied scientists in World War II, it proved so intractable that it was proposed the problem be dropped over Germany so that German scientists could also waste their time on it.[4] It was formulated by Herbert Robbins in 1952.
The multi-armed bandit model
The multi-armed bandit (or just bandit for short) can be seen as a set of real distributions 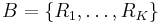 , each distribution being associated with the rewards delivered by one of the K levers. Let
, each distribution being associated with the rewards delivered by one of the K levers. Let  be the mean values associated with these reward distributions. The gambler iteratively plays one lever per round and observes the associated reward. The objective is to maximize the sum of the collected rewards. The horizon H is the number of rounds that remain to be played. The bandit problem is formally equivalent to a one-state Markov decision process. The regret
be the mean values associated with these reward distributions. The gambler iteratively plays one lever per round and observes the associated reward. The objective is to maximize the sum of the collected rewards. The horizon H is the number of rounds that remain to be played. The bandit problem is formally equivalent to a one-state Markov decision process. The regret 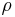 after T rounds is defined as the difference between the reward sum associated with an optimal strategy and the sum of the collected rewards:
after T rounds is defined as the difference between the reward sum associated with an optimal strategy and the sum of the collected rewards: 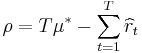 , where
, where 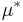 is the maximal reward mean,
is the maximal reward mean, 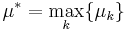 , and
, and 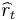 is the reward at time t. A strategy whose average regret per round
is the reward at time t. A strategy whose average regret per round 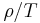 tends to zero with probability 1 when the number of played rounds tends to infinity is a zero-regret strategy. Intuitively, zero-regret strategies are guaranteed to converge to an optimal strategy, not necessarily unique, if enough rounds are played.
tends to zero with probability 1 when the number of played rounds tends to infinity is a zero-regret strategy. Intuitively, zero-regret strategies are guaranteed to converge to an optimal strategy, not necessarily unique, if enough rounds are played.
Variations
Another formulation of the multi-armed bandit has each arm representing an independent markov machine. Each time a particular arm is played, the state of that machine advances to a new one, chosen according to the Markov state evolution probabilities. There is a reward depending on the current state of the machine. In a generalisation called the "restless bandit problem", the states of non-played arms can also evolve over time.[5] There has also been discussion of systems where the number of choices (about which arm to play) increases over time.[6]
Computer science researchers have studied multi-armed bandits under worst-case assumptions, obtaining positive results for finite numbers of trials with both stochastic [7] and nonstochastic[8] arm payoffs.
Common bandit strategies
Many strategies exist which provide an approximate solution to the bandit problem, and can be put into the three broad categories detailed below.
Semi-uniform strategies
Semi-uniform strategies were the earliest (and simplest) strategies discovered to approximately solve the bandit problem. All those strategies have in common a greedy behavior where the best lever (based on previous observations) is always pulled except when a (uniformly) random action is taken.
- Epsilon-greedy strategy: The best lever is selected for a proportion
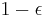 of the trials, and another lever is randomly selected (with uniform probability) for a proportion
of the trials, and another lever is randomly selected (with uniform probability) for a proportion 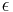 . A typical parameter value might be
. A typical parameter value might be 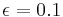 , but this can vary widely depending on circumstances and predilections.
, but this can vary widely depending on circumstances and predilections.
- Epsilon-first strategy: A pure exploration phase is followed by a pure exploitation phase. For trials in total, the exploration phase occupies
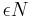 trials and the exploitation phase
trials and the exploitation phase 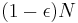 trials. During the exploration phase, a lever is randomly selected (with uniform probability); during the exploitation phase, the best lever is always selected.
trials. During the exploration phase, a lever is randomly selected (with uniform probability); during the exploitation phase, the best lever is always selected.
- Epsilon-decreasing strategy: Similar to the epsilon-greedy strategy, except that the value of decreases as the experiment progresses, resulting in highly explorative behaviour at the start and highly exploitative behaviour at the finish.
- Adaptive epsilon-greedy strategy based on value differences (VDBE): Similar to the epsilon-decreasing strategy, except that epsilon is reduced on basis of the learning progress instead of manual tuning (Tokic, 2010). High changes in the value estimates lead to a high epsilon (exploration); low value changes to a low epsilon (exploitation).
Probability matching strategies
Probability matching strategies reflect the idea that the number of pulls for a given lever should match its actual probability of being the optimal lever.
Pricing strategies
Pricing strategies establish a price for each lever. The lever of highest price is always pulled.
Optimal strategies with ethical constraints
These strategies minimize the assignment of any patient to an inferior arm ("physician's duty"). In a typical case, they minimize expected successes lost (ESL), that is, the expected number of favorable outcomes that were missed because of assignment to an arm later proved to be inferior. Another version minimizes resources wasted on any inferior, more expensive, treatment.[3]
See also
- Gittins index — a powerful, general strategy for analyzing bandit problems.
- Optimal stopping
- Search theory
- Greedy algorithm
Notes
- ^ a b c Gittins (1989)
- ^ a b c Berry and Fristedt (1985)
- ^ a b Press (2009)
- ^ Whittle (1979)
- ^ Whittle (1988)
- ^ Whittle (1981)
- ^ P. Auer et al. (2002) "Finite-time analysis of the multiarmed bandit problem." Machine Learning 47:235-256 doi:10.1023/A:1013689704352
- ^ P. Auer et al. (2002) "The nonstochastic multiarmed bandit problem." Siam Journal on Computing 32:48-77 doi:10.1137/S0097539701398375
References
- Berry, Donald A.; Fristedt, Bert (1985), Bandit problems: Sequential allocation of experiments, Monographs on Statistics and Applied Probability, London: Chapman & Hall, ISBN 0-412-24810-7.
- Dayanik, S.; Powell, W.; Yamazaki, K. (2008), "Index policies for discounted bandit problems with availability constraints", Advances in Applied Probability 40 (2): 377–400, doi:10.1239/aap/1214950209.
- Gittins, J. C. (1989), Multi-armed bandit allocation indices, Wiley-Interscience Series in Systems and Optimization., Chichester: John Wiley & Sons, Ltd., ISBN 0-471-92059-2.
- Powell, Warren B. (2007), "Chapter 10", Approximate Dynamic Programming: Solving the Curses of Dimensionality, New York: John Wiley and Sons, ISBN 0470171553.
- William H. Press (2009) "Bandit solutions provide unified ethical models for randomized clinical trials and comparative effectiveness research," Proceedings of the National Academy of Sciences, vol. 106, pp. 22387-22392.
- Robbins, H. (1952), "Some aspects of the sequential design of experiments", Bulletin of the American Mathematical Society 58 (5): 527–535, doi:10.1090/S0002-9904-1952-09620-8.
- Sutton, Richard; Barto, Andrew (1998), Reinforcement Learning, MIT Press, ISBN 0262193981, http://webdocs.cs.ualberta.ca/~sutton/book/the-book.html.
- Tokic, Michel (2010), "Adaptive ε-greedy exploration in reinforcement learning based on value differences", KI 2010: Advances in Artificial Intelligence, Lecture Notes in Computer Science, 6359, Springer-Verlag, pp. 203–210, doi:10.1007/978-3-642-16111-7_23, ISBN 978-3-642-16110-0, http://www.tokic.com/www/tokicm/publikationen/papers/AdaptiveEpsilonGreedyExploration.pdf.
- Weber, Richard (1992), "On the Gittins index for multiarmed bandits", Annals of Applied Probability 2 (4): 1024–1033, doi:10.1214/aoap/1177005588, JSTOR 2959678.
- Whittle, Peter (1979), "Discussion of Dr Gittins' paper", Journal of the Royal Statistical Society, Series B 41 (2): 165.
- Whittle, Peter (1981), "Arm-acquiring bandits", Annals of Probability 9 (2): 284–292, doi:10.1214/aop/1176994469.
- Whittle, Peter (1988), "Restless bandits: Activity allocation in a changing world", Journal of Applied Probability 25A: 287–298, MR974588.
External links
- bandit.sourceforge.net Bandit project , open source implementation of many bandit strategies at sourceforge.net
- Sudipto Guha, Kamesh Munagala, Peng Shi, (2009) "Approximation Algorithms for Restless Bandit Problems", 2009 arXiv:0711.3861v5
- Leslie Pack Kaelbling and Michael L. Littman (1996). Exploitation versus Exploration: The Single-State Case
- Tutorial: Introduction to Bandits: Algorithms and Theory. Part1. Part2.
- Feynman's restaurant problem, a classic example (with known answer) of the exploitation vs. exploration tradeoff.