Cross entropy
In information theory, the cross entropy between two probability distributions measures the average number of bits needed to identify an event from a set of possibilities, if a coding scheme is used based on a given probability distribution 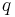 , rather than the "true" distribution
, rather than the "true" distribution 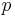 .
.
The cross entropy for two distributions and over the same probability space is thus defined as follows:
![\mathrm{H}(p, q) = \mathrm{E}_p[-\log q] = \mathrm{H}(p) %2B D_{\mathrm{KL}}(p \| q)\!](/2012-wikipedia_en_all_nopic_01_2012/I/0ab52f3e2d2aa97a20317c6a92d976c7.png) ,
,
where 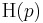 is the entropy of , and
is the entropy of , and 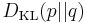 is the Kullback-Leibler divergence of from (also known as the relative entropy).
is the Kullback-Leibler divergence of from (also known as the relative entropy).
For discrete and this means
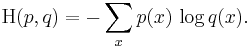
The situation for continuous distributions is analogous:
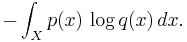
NB: The notation 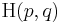 is sometimes used for both the cross entropy as well as the joint entropy of and .
is sometimes used for both the cross entropy as well as the joint entropy of and .
Estimation
There are many situations where cross-entropy needs to be measured but the distribution of is unknown. An example is language modeling, where a model is created based on a training set  , and then its cross-entropy is measured on a test set to assess how accurate the model is in predicting the test data. In this example, is the true distribution of words in any corpus, and is the distribution of words as predicted by the model. Since the true distribution is unknown, cross-entropy cannot be directly calculated. In these cases, an estimate of cross-entropy is calculated using the following formula:
, and then its cross-entropy is measured on a test set to assess how accurate the model is in predicting the test data. In this example, is the true distribution of words in any corpus, and is the distribution of words as predicted by the model. Since the true distribution is unknown, cross-entropy cannot be directly calculated. In these cases, an estimate of cross-entropy is calculated using the following formula:
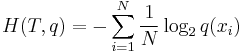
where 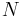 is the size of the test set, and
is the size of the test set, and 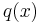 is the probability of event
is the probability of event  estimated from the training set. It should be noted that the sum is calculated over . This is a Monte Carlo estimate of the true cross entropy, where the training set is treated as samples from
estimated from the training set. It should be noted that the sum is calculated over . This is a Monte Carlo estimate of the true cross entropy, where the training set is treated as samples from 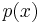 .
.
Cross-entropy minimization
Cross-entropy minimization is frequently used in optimization and rare-event probability estimation; see the cross-entropy method.
When comparing a distribution against a fixed reference distribution , cross entropy and KL divergence are identical up to an additive constant (since is fixed): both take on their minimal values when 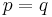 , which is
, which is 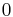 for KL divergence, and for cross entropy. In the engineering literature, the principle of minimising KL Divergence (Kullback's "Principle of Minimum Discrimination Information") is often called the Principle of Minimum Cross-Entropy (MCE), or Minxent.
for KL divergence, and for cross entropy. In the engineering literature, the principle of minimising KL Divergence (Kullback's "Principle of Minimum Discrimination Information") is often called the Principle of Minimum Cross-Entropy (MCE), or Minxent.
However, as discussed in the article Kullback-Leibler divergence, sometimes the distribution q is the fixed prior reference distribution, and the distribution p is optimised to be as close to q as possible, subject to some constraint. In this case the two minimisations are not equivalent. This has led to some ambiguity in the literature, with some authors attempting to resolve the inconsistency by redefining cross-entropy to be DKL(p||q) , rather than H(p,q).