Inequalities in information theory
Inequalities are very important in the study of information theory. There are a number of different contexts in which these inequalities appear.
Contents |
Shannon-type inequalities
Consider a finite collection of finitely (or at most countably) supported random variables on the same probability space. For a collection of n random variables, there are 2n − 1 such non-empty subsets for which entropies can be defined. For example, when n = 2, we may consider the entropies 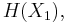
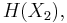 and
and 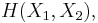 and express the following inequalities (which together characterize the range of the marginal and joint entropies of two random variables):
and express the following inequalities (which together characterize the range of the marginal and joint entropies of two random variables):
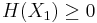
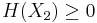
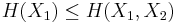
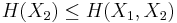
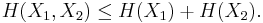
In fact, these can all be expressed as special cases of a single inequality involving the conditional mutual information, namely
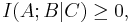
where  ,
, 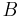 , and
, and 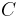 each denote the joint distribution of some arbitrary (possibly empty) subset of our collection of random variables. Inequalities that can be derived from this are known as Shannon-type inequalities. More formally, (following the notation of Yeung), define
each denote the joint distribution of some arbitrary (possibly empty) subset of our collection of random variables. Inequalities that can be derived from this are known as Shannon-type inequalities. More formally, (following the notation of Yeung), define 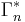 to be the set of all constructible points in
to be the set of all constructible points in 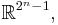 where a point is said to be constructible if and only if there is a joint, discrete distribution of n random variables such that each coordinate of that point, indexed by a non-empty subset of {1, 2, ..., n}, is equal to the joint entropy of the corresponding subset of the n random variables. The closure of is denoted
where a point is said to be constructible if and only if there is a joint, discrete distribution of n random variables such that each coordinate of that point, indexed by a non-empty subset of {1, 2, ..., n}, is equal to the joint entropy of the corresponding subset of the n random variables. The closure of is denoted 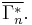
The cone in 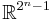 characterized by all Shannon-type inequalities among n random variables is denoted
characterized by all Shannon-type inequalities among n random variables is denoted 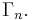 Software has been developed to automate the task of proving such inequalities.[1][2] Given an inequality, such software is able to determine whether the given inequality contains the cone
Software has been developed to automate the task of proving such inequalities.[1][2] Given an inequality, such software is able to determine whether the given inequality contains the cone 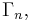 in which case the inequality can be verified, since
in which case the inequality can be verified, since 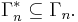
Non-Shannon-type inequalities
Other, less trivial inequalities have been discovered among the entropies and joint entropies of four or more random variables, which cannot be derived from Shannon's basic inequalities.[3][4] These are known as non-Shannon-type inequalities.
It was shown that
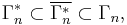
where the inclusions are proper for 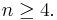 All three of these sets are, in fact, convex cones.
All three of these sets are, in fact, convex cones.
Lower bounds for the Kullback–Leibler divergence
A great many important inequalities in information theory are actually lower bounds for the Kullback–Leibler divergence. Even the Shannon-type inequalities can be considered part of this category, since the bivariate mutual information can be expressed as the Kullback–Leibler divergence of the joint distribution with respect to the product of the marginals, and thus these inequalities can be seen as a special case of Gibbs' inequality.
On the other hand, it seems to be much more difficult to derive useful upper bounds for the Kullback–Leibler divergence. This is because the Kullback–Leibler divergence DKL(P||Q) depends very sensitively on events that are very rare in the reference distribution Q. DKL(P||Q) increases without bound as an event of finite non-zero probability in the distribution P becomes exceedingly rare in the reference distribution Q, and in fact DKL(P||Q) is not even defined if an event of non-zero probability in P has zero probability in Q. (Hence the requirement that P be absolutely continuous with respect to Q.)
Gibbs' inequality
This fundamental inequality states that the Kullback–Leibler divergence is non-negative.
Kullback's inequality
Another inequality concerning the Kullback–Leibler divergence is known as Kullback's inequality.[5] If P and Q are probability distributions on the real line with P absolutely continuous with respect to Q, and whose first moments exist, then
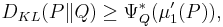
where 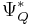 is the large deviations rate function, i.e. the convex conjugate of the cumulant-generating function, of Q, and
is the large deviations rate function, i.e. the convex conjugate of the cumulant-generating function, of Q, and 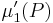 is the first moment of P.
is the first moment of P.
The Cramér–Rao bound is a corollary of this result.
Pinsker's inequality
Pinsker's inequality relates Kullback–Leibler divergence and total variation distance. It states that if P, Q are two probability distributions, then
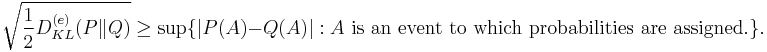
where
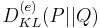
is the Kullback–Leibler divergence in nats and
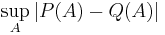
is the total variation distance.
Other inequalities
Hirschman uncertainty
In 1957,[6] Hirschman showed that for a (reasonably well-behaved) function 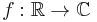 such that
such that 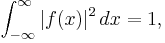 and its Fourier transform
and its Fourier transform 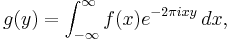 the sum of the differential entropies of
the sum of the differential entropies of 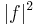 and
and 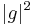 is non-negative, i.e.
is non-negative, i.e.
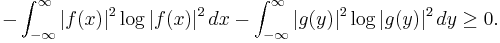
Hirschman conjectured, and it was later proved,[7] that a sharper bound of 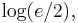 which is attained in the case of a Gaussian distribution, could replace the right-hand side of this inequality. This is especially significant since it implies, and is stronger than, Weyl's formulation of Heisenberg's uncertainty principle.
which is attained in the case of a Gaussian distribution, could replace the right-hand side of this inequality. This is especially significant since it implies, and is stronger than, Weyl's formulation of Heisenberg's uncertainty principle.
Tao's inequality
Given discrete random variables 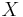 ,
, 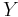 , and
, and 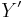 , such that takes values only in the interval [−1, 1] and is determined by (so that
, such that takes values only in the interval [−1, 1] and is determined by (so that 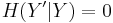 ), we have[8][9]
), we have[8][9]
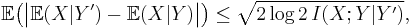
relating the conditional expectation to the conditional mutual information. This is a simple consequence of Pinsker's inequality. (Note: the correction factor log 2 inside the radical arises because we are measuring the conditional mutual information in bits rather than nats.)
See also
- Cramér–Rao bound
- Entropy power inequality
- Fano's inequality
- Jensen's inequality
- Kraft inequality
- Pinsker's inequality
- Multivariate mutual information
References
- ^ R.Yeung,Y.Yan,ITIP – Information Theoretic Inequality Prover
- ^ R.Pulikkoonattu,E.Perron,S.Diggavi, Xitip – Information Theoretic Inequalities Prover
- ^ Zhang, Z.; Yeung, R. W. (1997). "A non-Shannon-type conditional inequality of information quantities". IEEE Transactions on Information Theory (New York) 43 (6): 1982. doi:10.1109/18.641561.
- ^ Makarychev, K.; et al. (2002). "A new class of non-Shannon-type inequalities for entropies". Communications in Information and Systems 2 (2): 147–166. http://www.cs.princeton.edu/~ymakaryc/papers/nonshann.pdf.
- ^ Fuchs, Aimé; Letta, Giorgio (1970). "L'inégalité de Kullback. Application à la théorie de l'estimation". Séminaire de probabilités (Strasbourg) 4: 108–131. MR267669.
- ^ Hirschman, I. I. (1957). "A Note on Entropy". American Journal of Mathematics 79 (1): 152–156. doi:10.2307/2372390. JSTOR 2372390.
- ^ Beckner, W. (1975). "Inequalities in Fourier Analysis". Annals of Mathematics 102 (6): 159–182. doi:10.2307/1970980. JSTOR 1970980.
- ^ Tao, T. (2006). "Szemeredi's regularity lemma revisited". Contrib. Discrete Math. 1: 8–28. arXiv:math/0504472.
- ^ Ahlswede, Rudolf (2007). "The final form of Tao's inequality relating conditional expectation and conditional mutual information". Advances in Mathematics of Communications 1 (2): 239–242. doi:10.3934/amc.2007.1.239.
External links
- Thomas M. Cover, Joy A. Thomas. Elements of Information Theory, Chapter 16, "Inequalities in Information Theory" John Wiley & Sons, Inc. 1991 Print ISBN 0471062596 Online ISBN 0471200611 pdf
- Amir Dembo, Thomas M. Cover, Joy A. Thomas. Information Theoretic Inequalities. IEEE Transactions on Information Theory, Vol. 37, No. 6, November 1991. pdf