Harris affine region detector
| Feature detection |
|---|
|
Output of a typical corner detection algorithm
|
| Edge detection |
| Canny · Canny-Deriche · Differential · Sobel · Prewitt · Roberts Cross |
| Interest point detection |
| Corner detection |
| Harris operator · Shi and Tomasi · Level curve curvature · SUSAN · FAST |
| Blob detection |
| Laplacian of Gaussian (LoG) · Difference of Gaussians (DoG) · Determinant of Hessian (DoH) · Maximally stable extremal regions · PCBR |
| Ridge detection |
| Hough transform |
| Structure tensor |
| Affine invariant feature detection |
| Affine shape adaptation · Harris affine · Hessian affine |
| Feature description |
| SIFT · SURF · GLOH · HOG · LESH |
| Scale-space |
| Scale-space axioms · Implementation details · Pyramids |
In the fields of computer vision and image analysis, the Harris affine region detector belongs to the category of feature detection. Feature detection is a preprocessing step of several algorithms that rely on identifying characteristic points or interest points so to make correspondences between images, recognize textures, categorize objects or build panoramas.
Contents |
Overview
The Harris affine detector can identify similar regions between images that are related through affine transformations and have different illuminations. These affine-invariant detectors should be capable of identifying similar regions in images taken from different viewpoints that are related by a simple geometric transformation: scaling, rotation and shearing. These detected regions have been called both invariant and covariant. On one hand, the regions are detected invariant of the image transformation but the regions covariantly change with image transformation.[1] Do not dwell too much on these two naming conventions; the important thing to understand is that the design of these interest points will make them compatible across images taken from several viewpoints. Other detectors that are affine-invariant include Hessian affine region detector, Maximally stable extremal regions, Kadir–Brady saliency detector, edge-based regions (EBR) and intensity-extrema-based (IBR) regions.
Mikolajczyk and Schmid (2002) first described the Harris affine detector as it is used today in An Affine Invariant Interest Point Detector.[2] Earlier works in this direction include use of affine shape adaptation by Lindeberg and Garding for computing affine invariant image descriptors and in this way reducing the influence of perspective image deformations,[3] the use affine adapted feature points for wide baseline matching by Baumberg[4] and the first use of scale invariant feature points by Lindeberg;[5][6] see also [7] for an overview of the theoretical background. The Harris affine detector relies on the combination of corner points detected thorough Harris corner detection, multi-scale analysis through Gaussian scale-space and affine normalization using an iterative affine shape adaptation algorithm. The recursive and iterative algorithm follows an iterative approach to detecting these regions:
- Identify initial region points using scale-invariant Harris-Laplace Detector.
- For each initial point, normalize the region to be affine invariant using affine shape adaptation.
- Iteratively estimate the affine region: selection of proper integration scale, differentiation scale and spatially localize interest points..
- Update the affine region using these scales and spatial localizations.
- Repeat step 3 if the stopping criterion is not met.
Algorithm description
Harris–Laplace detector (initial region points)
The Harris affine detector relies heavily on both the Harris measure and a Gaussian scale-space representation. Therefore, a brief examination of both follow. For a more exhaustive derivations see corner detection and Gaussian scale-space or their associated papers.[6][8]
Harris corner measure
The Harris corner detector algorithm relies on a central principle: at a corner, the image intensity will change largely in multiple directions. This can alternatively be formulated by examining the changes of intensity due to shifts in a local window. Around a corner point, the image intensity will change greatly when the window is shifted in an arbitrary direction. Following this intuition and through a clever decomposition, the Harris detector uses the second moment matrix as the basis of its corner decisions. (See corner detection for more complete derivation). The matrix  , has also been called the autocorrelation matrix and has values closely related to the derivatives of image intensity.
, has also been called the autocorrelation matrix and has values closely related to the derivatives of image intensity.
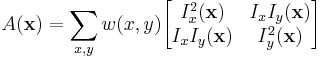
where 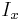 and
and 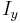 are the respective derivatives (of pixel intensity) in the
are the respective derivatives (of pixel intensity) in the  and
and 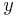 direction at point
direction at point 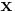 . The off-diagonal entries are the product of and , while the diagonal entries are squares of the respective derivatives. The weighting function
. The off-diagonal entries are the product of and , while the diagonal entries are squares of the respective derivatives. The weighting function 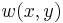 can be uniform, but is more typically an isotropic, circular Gaussian,
can be uniform, but is more typically an isotropic, circular Gaussian,
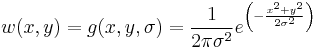
that acts to average in a local region while weighting those values near the center more heavily.
As it turns out, this matrix describes the shape of the autocorrelation measure as due to shifts in window location. Thus, if we let 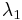 and
and 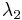 be the eigenvalues of , then these values will provide a quantitative description of the how the autocorrelation measure changes in space: its principal curvatures. As Harris and Stephens (1988) point out, the matrix centered on corner points will have two large, positive eigenvalues.[8] Rather than extracting these eigenvalues using methods like singular value decomposition, the Harris measure based on the trace and determinant is used:
be the eigenvalues of , then these values will provide a quantitative description of the how the autocorrelation measure changes in space: its principal curvatures. As Harris and Stephens (1988) point out, the matrix centered on corner points will have two large, positive eigenvalues.[8] Rather than extracting these eigenvalues using methods like singular value decomposition, the Harris measure based on the trace and determinant is used:
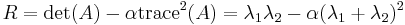
where  is a constant. Corner points have large, positive eigenvalues and would thus have a large Harris measure. Thus, corner points are identified as local maxima of the Harris measure that are above a specified threshold.
is a constant. Corner points have large, positive eigenvalues and would thus have a large Harris measure. Thus, corner points are identified as local maxima of the Harris measure that are above a specified threshold.
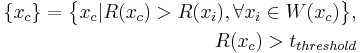
where 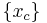 are the set of all corner points,
are the set of all corner points, 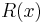 is the Harris measure calculated at ,
is the Harris measure calculated at , 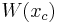 is an 8-neighbor set centered around
is an 8-neighbor set centered around 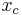 and
and 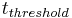 is a specified threshold.
is a specified threshold.
Gaussian scale-space
A Gaussian scale-space representation of an image is the set of images that result from convolving a Gaussian kernel of various sizes with the original image. In general, the representation can be formulated as:
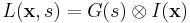
where 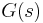 is an isotropic, circular Gaussian kernel as defined above. The convolution with a Gaussian kernel smooths the image using a window the size of the kernel. A larger scale,
is an isotropic, circular Gaussian kernel as defined above. The convolution with a Gaussian kernel smooths the image using a window the size of the kernel. A larger scale, 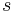 , corresponds to a smoother resultant image. Mikolajczyk and Schmid (2001) point out that derivatives and other measurements must be normalized across scales.[9] A derivative of order
, corresponds to a smoother resultant image. Mikolajczyk and Schmid (2001) point out that derivatives and other measurements must be normalized across scales.[9] A derivative of order 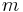 ,
, 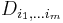 , must be normalized by a factor
, must be normalized by a factor 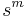 in the following manner:
in the following manner:
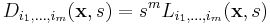
These derivatives, or any arbitrary measure, can be adapted to a scale-space representation by calculating this measure using a set of scales recursively where the 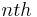 scale is
scale is 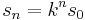 . See scale space for a more complete description.
. See scale space for a more complete description.
Combining Harris detector across Gaussian scale-space
The Harris-Laplace detector combines the traditional 2D Harris corner detector with the idea of a Gaussian scale-space representation in order to create a scale-invariant detector. Harris-corner points are good starting points because they have been shown to have good rotational and illumination invariance in addition to identifying the interesting points of the image.[10] However, the points are not scale invariant and thus the second-moment matrix must be modified to reflect a scale-invariant property. Let us denote, 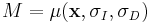 as the scale adapted second-moment matrix used in the Harris-Laplace detector.
as the scale adapted second-moment matrix used in the Harris-Laplace detector.
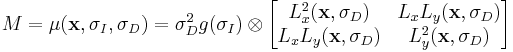
where 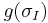 is the Gaussian kernel of scale
is the Gaussian kernel of scale 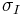 and
and 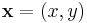 . Similar to the Gaussian-scale space,
. Similar to the Gaussian-scale space, 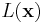 is the Gaussian-smoothed image. The
is the Gaussian-smoothed image. The  operator denotes convolution.
operator denotes convolution. 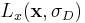 and
and 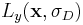 are the derivatives in their respective direction applied to the smoothed image and calculated using a Gaussian kernel with scale
are the derivatives in their respective direction applied to the smoothed image and calculated using a Gaussian kernel with scale 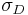 . In terms of our Gaussian scale-space framework, the parameter determines the current scale at which the Harris corner points are detected.
. In terms of our Gaussian scale-space framework, the parameter determines the current scale at which the Harris corner points are detected.
Building upon this scale-adapted second-moment matrix, the Harris-Laplace detector is a twofold process: applying the Harris corner detector at multiple scales and automatically choosing the characteristic scale.
Multi-scale Harris corner points
The algorithm searches over a fixed number of predefined scales. This set of scales is defined as:
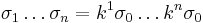
Mikolajczyk and Schmid (2004) use 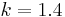 . For each integration scale, , chosen from this set, the appropriate differentiation scale is chosen to be a constant factor of the integration scale:
. For each integration scale, , chosen from this set, the appropriate differentiation scale is chosen to be a constant factor of the integration scale: 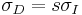 . Mikolajczyk and Schmid (2004) used
. Mikolajczyk and Schmid (2004) used 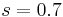 .[11] Using these scales, the interest points are detected using a Harris measure on the
.[11] Using these scales, the interest points are detected using a Harris measure on the 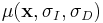 matrix. The cornerness, like the typical Harris measure, is defined as:
matrix. The cornerness, like the typical Harris measure, is defined as:
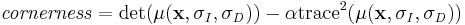
Like the traditional Harris detector, corner points are those local (8 point neighborhood) maxima of the cornerness that are above a specified threshold.
Characteristic scale identification
An iterative algorithm based on Lindeberg (1998) both spatially localizes the corner points and selects the characteristic scale.[6] The iterative search has three key steps, that are carried for each point that were initially detected at scale by the multi-scale Harris detector ( indicates the
indicates the 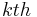 iteration):
iteration):
- Choose the scale
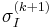 that maximizes the Laplacian-of-Gaussians (LoG) over a predefined range of neighboring scales. The neighboring scales are typically chosen from a range that is within a two scale-space neighborhood. That is, if the original points were detected using a scaling factor of
that maximizes the Laplacian-of-Gaussians (LoG) over a predefined range of neighboring scales. The neighboring scales are typically chosen from a range that is within a two scale-space neighborhood. That is, if the original points were detected using a scaling factor of 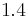 between successive scales, a two scale-space neighborhood is the range
between successive scales, a two scale-space neighborhood is the range ![t \in [0.7, \dots, 1.4]](/2012-wikipedia_en_all_nopic_01_2012/I/53fb504be03e53e3cd1393708f48ea19.png) . Thus the Gaussian scales examined are:
. Thus the Gaussian scales examined are: 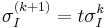 . The LoG measurement is defined as:
. The LoG measurement is defined as:
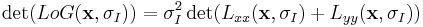
- where
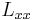 and
and 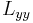 are the second derivatives in their respective directions.[12] The
are the second derivatives in their respective directions.[12] The 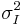 factor (as discussed above in Gaussian scale-space) is used to normalize the LoG across scales and make these measures comparable, thus making a maximum relevant. Mikolajczyk and Schmid (2001) demonstrate that the LoG measure attains the highest percentage of correctly detected corner points in comparison to other scale-selection measures.[9] The scale which maximizes this LoG measure in the two scale-space neighborhood is deemed the characteristic scale, , and used in subsequent iterations. If no extrema, or maxima of the LoG is found, this point is discarded from future searches.
factor (as discussed above in Gaussian scale-space) is used to normalize the LoG across scales and make these measures comparable, thus making a maximum relevant. Mikolajczyk and Schmid (2001) demonstrate that the LoG measure attains the highest percentage of correctly detected corner points in comparison to other scale-selection measures.[9] The scale which maximizes this LoG measure in the two scale-space neighborhood is deemed the characteristic scale, , and used in subsequent iterations. If no extrema, or maxima of the LoG is found, this point is discarded from future searches.
- Using the characteristic scale, the points are spatially localized. That is to say, the point
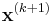 is chosen such that it maximizes the Harris corner measure (cornerness as defined above) within an 8×8 local neighborhood.
is chosen such that it maximizes the Harris corner measure (cornerness as defined above) within an 8×8 local neighborhood.
- Stopping criterion:
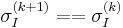 and
and 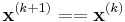 .
.
If the stopping criterion is not met, then the algorithm repeats from step 1 using the new 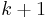 points and scale. When the stopping criterion is met, the found points represent those that maximize the LoG across scales (scale selection) and maximize the Harris corner measure in a local neighborhood (spatial selection).
points and scale. When the stopping criterion is met, the found points represent those that maximize the LoG across scales (scale selection) and maximize the Harris corner measure in a local neighborhood (spatial selection).
Affine-invariant points
Mathematical theory
The Harris-Laplace detected points are scale invariant and work well for isotropic regions that are viewed from the same viewing angle. In order to be invariant to arbitrary affine transformations (and viewpoints), the mathematical framework must be revisited. The second-moment matrix 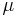 is defined more generally for anisotropic regions:
is defined more generally for anisotropic regions:
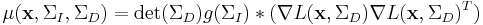
where 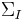 and
and 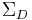 are covariance matrices defining the differentiation and the integration Gaussian kernel scales. Although this may look significantly different than the second-moment matrix in the Harris-Laplace detector; it is in fact, identical. The earlier
are covariance matrices defining the differentiation and the integration Gaussian kernel scales. Although this may look significantly different than the second-moment matrix in the Harris-Laplace detector; it is in fact, identical. The earlier 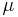 matrix was the 2D-isotropic version in which the covariance matrices and were 2x2 identity matrices multiplied by factors and , respectively. In the new formulation, one can think of Gaussian kernels as a multivariate Gaussian distributions as opposed to a uniform Gaussian kernel. A uniform Gaussian kernel can be thought of as an isotropic, circular region. Simiarly, a more general Gaussian kernel defines an ellipsoid. In fact, the eigenvectors and eigenvalues of the covariance matrix define the rotation and size of the ellipsoid. Thus we can easily see that this representation allows us to completely define an arbitrary elliptical affine region over which we want to integrate or differentiate.
matrix was the 2D-isotropic version in which the covariance matrices and were 2x2 identity matrices multiplied by factors and , respectively. In the new formulation, one can think of Gaussian kernels as a multivariate Gaussian distributions as opposed to a uniform Gaussian kernel. A uniform Gaussian kernel can be thought of as an isotropic, circular region. Simiarly, a more general Gaussian kernel defines an ellipsoid. In fact, the eigenvectors and eigenvalues of the covariance matrix define the rotation and size of the ellipsoid. Thus we can easily see that this representation allows us to completely define an arbitrary elliptical affine region over which we want to integrate or differentiate.
The goal of the affine invariant detector is to identify regions in images that are related through affine transformations. We thus consider a point 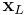 and the transformed point
and the transformed point 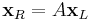 , where A is an affine transformation. In the case of images, both
, where A is an affine transformation. In the case of images, both 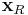 and live in
and live in 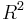 space. The second-moment matrices are related in the following manner:[3]
space. The second-moment matrices are related in the following manner:[3]
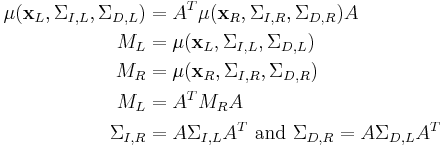
where 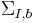 and
and 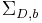 are the covariance matrices for the
are the covariance matrices for the 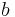 reference frame. If we continue with this formulation and enforce that
reference frame. If we continue with this formulation and enforce that
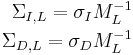
where and are scalar factors, one can show that the covariance matrices for the related point are similarly related:
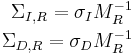
By requiring the covariance matrices to satisfy these conditions, several nice properties arise. One of these properties is that the square root of the second-moment matrix, 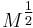 will transform the original anisotropic region into isotropic regions that are related simply through a pure rotation matrix
will transform the original anisotropic region into isotropic regions that are related simply through a pure rotation matrix 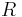 . These new isotropic regions can be thought of as a normalized reference frame. The following equations formulate the relation between the normalized points
. These new isotropic regions can be thought of as a normalized reference frame. The following equations formulate the relation between the normalized points 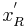 and
and 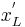 :
:
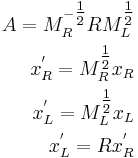
The rotation matrix can be recovered using gradient methods likes those in the SIFT descriptor. As discussed with the Harris detector, the eigenvalues and eigenvectors of the second-moment matrix, 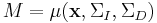 characterize the curvature and shape of the pixel intensities. That is, the eigenvector associated with the largest eigenvalue indicates the direction of largest change and the eigenvector associated with the smallest eigenvalue defines the direction of least change. In the 2D case, the eigenvectors and eigenvalues define an ellipse. For an isotropic region, the region should be circular in shape and not elliptical. This is the case when the eigenvalues have the same magnitude. Thus a measure of the isotropy around a local region is defined as the following:
characterize the curvature and shape of the pixel intensities. That is, the eigenvector associated with the largest eigenvalue indicates the direction of largest change and the eigenvector associated with the smallest eigenvalue defines the direction of least change. In the 2D case, the eigenvectors and eigenvalues define an ellipse. For an isotropic region, the region should be circular in shape and not elliptical. This is the case when the eigenvalues have the same magnitude. Thus a measure of the isotropy around a local region is defined as the following:
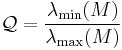
where 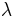 denote eigenvalues. This measure has the range
denote eigenvalues. This measure has the range ![[0 \dots 1]](/2012-wikipedia_en_all_nopic_01_2012/I/1b747dcaaa1990943e68870c2e5206fb.png) . A value of
. A value of 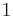 corresponds to perfect isotropy.
corresponds to perfect isotropy.
Iterative algorithm
Using this mathematical framework, the Harris affine detector algorithm iteratively discovers the second-moment matrix that transforms the anisotropic region into a normalized region in which the isotropic measure is sufficiently close to one. The algorithm uses this shape adaptation matrix, 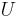 , to transform the image into a normalized reference frame. In this normalized space, the interest points' parameters (spatial location, integration scale and differentiation scale) are refined using methods similar to the Harris-Laplace detector. The second-moment matrix is computed in this normalized reference frame and should have an isotropic measure close to one at the final iteration. At every th iteration, each interest region is defined by several parameters that the algorithm must discover: the
, to transform the image into a normalized reference frame. In this normalized space, the interest points' parameters (spatial location, integration scale and differentiation scale) are refined using methods similar to the Harris-Laplace detector. The second-moment matrix is computed in this normalized reference frame and should have an isotropic measure close to one at the final iteration. At every th iteration, each interest region is defined by several parameters that the algorithm must discover: the 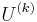 matrix, position
matrix, position 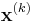 , integration scale
, integration scale 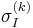 and differentiation scale
and differentiation scale 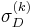 . Because the detector computes the second-moment matrix in the transformed domain, it's convenient to denote this transformed position as
. Because the detector computes the second-moment matrix in the transformed domain, it's convenient to denote this transformed position as 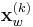 where
where 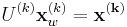 .
.
- The detector initializes the search space with points detected by the Harris-Laplace detector.
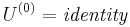 and
and 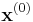 ,
, 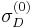 , and
, and 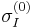 are those from the Harris-Laplace detector.
are those from the Harris-Laplace detector. - Apply the previous iteration shape adaptation matrix,
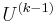 to generate the normalized reference frame,
to generate the normalized reference frame, 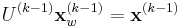 . For the first iteration, you apply
. For the first iteration, you apply 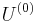 .
. - Select the integration scale, , using a method similar to the Harris-Laplace detector. The scale is chosen as the scale that maximizes the Laplacian of Gaussian (LoG). The search space of the scales are those within two scale-spaces of the previous iterations scale.
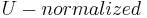 space differs significantly than the non-normalized space. Therefore, it is necessary to search for the integration scale as opposed to using the scale in the non-normalized space.
space differs significantly than the non-normalized space. Therefore, it is necessary to search for the integration scale as opposed to using the scale in the non-normalized space. - Select the differentiation scale, . In order to reduce the search space and degrees of freedom, the differentiation scale is taken to be related to the integration scale through a constant factor:
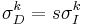 . For obvious reasons, the constant factor is less than one. Mikolajczyk and Schmid (2001) note that a too small factor will make smoothing (integration) too significant in comparison to differentiation and a factor that's too large will not allow for the integration to average the covariance matrix.[9] It is common to choose
. For obvious reasons, the constant factor is less than one. Mikolajczyk and Schmid (2001) note that a too small factor will make smoothing (integration) too significant in comparison to differentiation and a factor that's too large will not allow for the integration to average the covariance matrix.[9] It is common to choose ![s \in [0.5,0.75]](/2012-wikipedia_en_all_nopic_01_2012/I/13918bc10da07c34a64706e1fb6a3545.png) . From this set, the chosen scale will maximize the isotropic measure
. From this set, the chosen scale will maximize the isotropic measure 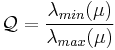 .
.
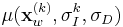 is the second-moment matrix evaluated in the normalized reference frame. This maximization processes causes the eigenvalues to converge to the same value.
is the second-moment matrix evaluated in the normalized reference frame. This maximization processes causes the eigenvalues to converge to the same value. - Spatial Localization: Select the point that maximizes the Harris corner measure (
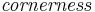 ) within an 8-point neighborhood around the previous
) within an 8-point neighborhood around the previous 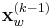 point.
is the second-moment matrix as defined above. The window
point.
is the second-moment matrix as defined above. The window 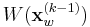 is the set of 8-nearest neighbors of the previous iteration's point in the normalized reference frame. Because our spatial localization was done in the -normalized reference frame, the newly chosen point must be transformed back to the original reference frame. This is achieved by transforming a displacement vector and adding this to the previous point:
is the set of 8-nearest neighbors of the previous iteration's point in the normalized reference frame. Because our spatial localization was done in the -normalized reference frame, the newly chosen point must be transformed back to the original reference frame. This is achieved by transforming a displacement vector and adding this to the previous point:
- As mentioned above, the square-root of the second-moment matrix defines the transformation matrix that generates the normalized reference frame. We thus need to save this matrix:
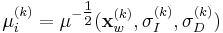 . The transformation matrix is updated:
. The transformation matrix is updated: 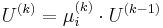 . In order to ensure that the image gets sampled correctly and we are expanding the image in the direction of the least change (smallest eigenvalue), we fix the maximum eigenvalue:
. In order to ensure that the image gets sampled correctly and we are expanding the image in the direction of the least change (smallest eigenvalue), we fix the maximum eigenvalue: 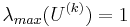 . Using this updating method, one can easily see that the final matrix takes the following form:
. Using this updating method, one can easily see that the final matrix takes the following form:
- If the stopping criterion is not met, continue to the next iteration at step 2. Because the algorithm iteratively solves for the
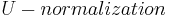 matrix that transforms an anisotropic region into an isotropic region, it makes sense to stop when the isotropic measure,
matrix that transforms an anisotropic region into an isotropic region, it makes sense to stop when the isotropic measure, 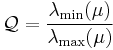 , is sufficiently close to its maximum value 1. Sufficiently close implies the following stopping condition:
, is sufficiently close to its maximum value 1. Sufficiently close implies the following stopping condition:
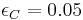 .
.
![\sigma_I^{(k)} = \underset{{\sigma_I = t\sigma_I^{(k-1)}\atop t \in [0.7, \dots, 1.4]}}{\operatorname{argmax}} \, \sigma_I^2 \det(L_{xx}(\mathbf{x}, \sigma_I) %2B L_{yy}(\mathbf{x},\sigma_I))](/2012-wikipedia_en_all_nopic_01_2012/I/6b1b934537a1fabb1eb92d5d52c2f897.png)
![\sigma_D^{(k)} = \underset{\sigma_D = s\sigma_I^{(k)},\; s \in [0.5, \dots, 0.75]}{\operatorname{argmax}} \, \frac{\lambda_\min(\mu(\mathbf{x}_w^{(k)}, \sigma_I^{k}, \sigma_D))}{\lambda_\max(\mu(\mathbf{x}_w^{(k)}, \sigma_I^{k}, \sigma_D))}](/2012-wikipedia_en_all_nopic_01_2012/I/668b758bdb60b746d8a8158ca4fe8d59.png)
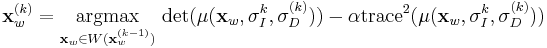
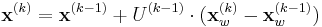
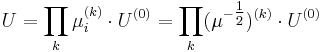
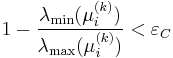
Computation and implementation
The computational complexity of the Harris-Affine detector is broken into two parts: initial point detection and affine region normalization. The initial point detection algorithm, Harris-Laplace, has complexity 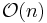 where
where  is the number of pixels in the image. The affine region normalization algorithm automatically detects the scale and estimates the shape adaptation matrix, . This process has complexity
is the number of pixels in the image. The affine region normalization algorithm automatically detects the scale and estimates the shape adaptation matrix, . This process has complexity 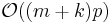 , where
, where 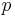 is the number of initial points, is the size of the search space for the automatic scale selection and is the number of iterations required to compute the matrix.[11]
is the number of initial points, is the size of the search space for the automatic scale selection and is the number of iterations required to compute the matrix.[11]
Some methods exist to reduce the complexity of the algorithm at the expense of accuracy. One method is to eliminate the search in the differentiation scale step. Rather than choose a factor from a set of factors, the sped-up algorithm chooses the scale to be constant across iterations and points: 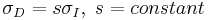 . Although this reduction in search space might decrease the complexity, this change can severely effect the convergence of the matrix.
. Although this reduction in search space might decrease the complexity, this change can severely effect the convergence of the matrix.
Analysis
Convergence
One can imagine that this algorithm might identify duplicate interest points at multiple scales. Because the Harris affine algorithm looks at each initial point given by the Harris-Laplace detector independently, there is no discrimination between identical points. In practice, it has been shown that these points will ultimately all converge to the same interest point. After finishing identifying all interest points, the algorithm accounts for duplicates by comparing the spatial coordinates (), the integration scale , the isotropic measure 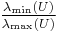 and skew.[11] If these interest point parameters are similar within a specified threshold, then they are labeled duplicates. The algorithm discards all these duplicate points except for the interest point that's closest to the average of the duplicates. Typically 30% of the Harris affine points are distinct and dissimilar enough to not be discarded.[11]
and skew.[11] If these interest point parameters are similar within a specified threshold, then they are labeled duplicates. The algorithm discards all these duplicate points except for the interest point that's closest to the average of the duplicates. Typically 30% of the Harris affine points are distinct and dissimilar enough to not be discarded.[11]
Mikolajczyk and Schmid (2004) showed that often the initial points (40%) do not converge. The algorithm detects this divergence by stopping the iterative algorithm if the inverse of the isotropic measure is larger than a specified threshold: 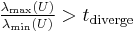 . Mikolajczyk and Schmid (2004) use
. Mikolajczyk and Schmid (2004) use 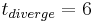 . Of those that did converge, the typical number of required iterations was 10.[2]
. Of those that did converge, the typical number of required iterations was 10.[2]
Quantitative measure
Quantitative analysis of affine region detectors take into account both the accuracy of point locations and the overlap of regions across two images. Mioklajcyzk and Schmid (2004) extend the repeatability measure of Schmid et al. (1998) as the ratio of point correspondences to minimum detected points of the two images.[11][13]
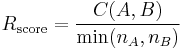
where 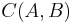 are the number of corresponding points in images and
are the number of corresponding points in images and 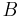 .
. 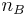 and
and 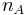 are the number of detected points in the respective images. Because each image represents 3D space, it might be the case that the one image contains objects that are not in the second image and thus whose interest points have no chance of corresponding. In order to make the repeatability measure valid, one remove these points and must only consider points that lie in both images; and only count those points such that
are the number of detected points in the respective images. Because each image represents 3D space, it might be the case that the one image contains objects that are not in the second image and thus whose interest points have no chance of corresponding. In order to make the repeatability measure valid, one remove these points and must only consider points that lie in both images; and only count those points such that 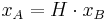 . For a pair of two images related through a homography matrix
. For a pair of two images related through a homography matrix 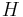 , two points,
, two points, 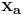 and
and 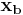 are said to correspond if:
are said to correspond if:
- Error in pixel location is less than 1.5 pixels:
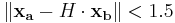
- The overlap error of the two affine points (
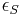 ) must be less than a specified threshold (typically 40%).[1] For affine regions, this overlap error is the following:
) must be less than a specified threshold (typically 40%).[1] For affine regions, this overlap error is the following:
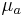 and
and 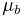 are the recovered elliptical regions whose points satisfy:
are the recovered elliptical regions whose points satisfy: 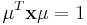 . Basically, this measure takes a ratio of areas: the area of overlap (intersection) and the total area (union). Perfect overlap would have a ratio of one and have an
. Basically, this measure takes a ratio of areas: the area of overlap (intersection) and the total area (union). Perfect overlap would have a ratio of one and have an 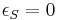 . Different scales effect the region of overlap and thus must be taken into account by normalizing the area of each region of interest. Regions with an overlap error as high as 50% are viable detectors to be matched with a good descriptor.[1] A second measure, a matching score, more practically assesses the detector's ability to identify matching points between images. Mikolajczyk and Schmid (2005) use a SIFT descriptor to identify matching points. In addition to being the closest points in SIFT-space, two matched points must also have a sufficiently small overlap error (as defined in the repeatability measure). The matching score is the ratio of the number of matched points and the minimum of the total detected points in each image:
. Different scales effect the region of overlap and thus must be taken into account by normalizing the area of each region of interest. Regions with an overlap error as high as 50% are viable detectors to be matched with a good descriptor.[1] A second measure, a matching score, more practically assesses the detector's ability to identify matching points between images. Mikolajczyk and Schmid (2005) use a SIFT descriptor to identify matching points. In addition to being the closest points in SIFT-space, two matched points must also have a sufficiently small overlap error (as defined in the repeatability measure). The matching score is the ratio of the number of matched points and the minimum of the total detected points in each image:
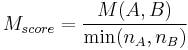 ,[1]
,[1]
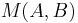 are the number of matching points and and are the number of detected regions in the respective images.
are the number of matching points and and are the number of detected regions in the respective images.
Robustness to affine and other transformations
Mikolajczyk et al. (2005) have done a thorough analysis of several state-of-the-art affine region detectors: Harris affine, Hessian affine, MSER,[14] IBR & EBR[15] and salient[16] detectors.[1] Mikolajczyk et al. analyzed both structured images and textured images in their evaluation. Linux binaries of the detectors and their test images are freely available at their webpage. A brief summary of the results of Mikolajczyk et al. (2005) follow; see A comparison of affine region detectors for a more quantitative analysis.
- Viewpoint Angle Change: The Harris affine detector has reasonable (average) robustness to these types of changes. The detector maintains a repeatability score of above 50% up until a viewpoint angle of above 40 degrees. The detector tends to detect a high number of repeatable and matchable regions even under a large viewpoint change.
- Scale Change: The Harris affine detector remains very consistent under scale changes. Although the number of points declines considerably at large scale changes (above 2.8), the repeatability (50-60%) and matching scores (25-30%) remain very constant especially with textured images. This is consistent with the high-performance of the automatic scale selection iterative algorithm.
- Blurred Images: The Harris affine detector remains very stable under image blurring. Because the detector does not rely on image segmentation or region boundaries, the repeatability and matching scores remain constant.
- JPEG Artifacts: The Harris affine detector degrades similar to other affine detectors: repeatability and matching scores drop significantly above 80% compression.
- Illumination Changes: The Harris affine detector, like other affine detectors, is very robust to illumination changes: repeatability and matching scores remain constant under decreasing light. This should be expected because the detectors rely heavily on relative intensities (derivatives) and not absolute intensities.
General trends
- Harris affine region points tend to be small and numerous. Both the Harris-Affine detector and Hessian-Affine consistently identify double the number repeatable points as other affine detectors: ~1000 regions for a 800x640 image.[1] Small regions are less likely to be occluded but have a smaller chance of overlapping neighboring regions.
- The Harris affine detector responds well to textured scenes in which there are a lot of corner-like parts. However, for some structured scenes, like buildings, the Harris-Affine detector performs very well. This is complementary to MSER that tends to do better with well structured (segmentable) scenes.
- Overall the Harris affine detector performs very well, but still behind MSER and Hessian-Affine in all cases but blurred images.
- Harris-Affine and Hessian-Affine detectors are less accurate than others: their repeatability score increases as the overlap threshold is increased.
- The detected affine-invariant regions may still differ in their rotation and illumination. Any descriptor that uses these regions must account for the invariance when using the regions for matching or other comparisons.
Applications
- Content-based image retrieval[17][18]
- Model-based recognition
- Object retrieval in video[19]
- Visual data mining: identifying important objects, characters and scenes in videos[20]
- Object recognition and categorization[21]
Software packages
- Affine Covariant Features: K. Mikolajczyk maintains a web page that contains Linux binaries of the Harris-Affine detector in addition to other detectors and descriptors. Matlab code is also available that can be used to illustrate and compute the repeatability of various detectors. Code and images are also available to duplicate the results found in the Mikolajczyk et al. (2005) paper.
- lip-vireo - binary code for Linux, Windows and SunOS from VIREO research group
External links
- [1] - Presentation slides from Mikolajczyk et al. on their 2005 paper.
- [2] - Cordelia Schmid's Computer Vision Lab
- [3] - Code, test Images, bibliography of Affine Covariant Features maintained by Krystian Mikolajczyk and the Visual Geometry Group from the Robotics group at the University of Oxford.
- [4] - Bibliography of feature (and blob) detectors maintained by USC Institute for Robotics and Intelligent Systems
- [5] - Digital implementation of Laplacian of Gaussian
See also
- Hessian-affine
- MSER
- Kadir brady saliency detector
- Scale-space
- Isotropy
- Corner detection
- Interest point detection
- Affine shape adaptation
- Computer vision
- ASIFT -> Affine-Sift (A fully affine invariant image matching algorithm)
References
- ^ a b c d e f K. Mikolajczyk, T. Tuytelaars, C. Schmid, A. Zisserman, J. Matas, F. Schaffalitzky, T. Kadir and L. Van Gool, A comparison of affine region detectors. In IJCV 65(1/2):43-72, 2005
- ^ a b Mikolajcyk, K. and Schmid, C. 2002. An affine invariant interest point detector. In Proceedings of the 8th International Conference on Computer Vision, Vancouver, Canada.
- ^ a b T. Lindeberg and J. Garding (1997). "Shape-adapted smoothing in estimation of 3-{D} depth cues from affine distortions of local 2-{D} structure". Image and Vision Computing 15: pp 415—434.
- ^ A. Baumberg (2000). "Reliable feature matching across widely separated views". Proceedings of IEEE Conference on Computer Vision and Pattern Recognition: pages I:1774—1781.
- ^ Lindeberg, Tony, Scale-Space Theory in Computer Vision, Kluwer Academic Publishers, 1994, ISBN 0-7923-9418-6
- ^ a b c T. Lindeberg (1998). "Feature detection with automatic scale selection". International Journal of Computer Vision 30 (2): pp 77—116.
- ^ *T. Lindeberg (2008/2009). "Scale-space". Encyclopedia of Computer Science and Engineering (Benjamin Wah, ed), John Wiley and Sons IV: 2495–2504. doi:10.1002/9780470050118.ecse609. http://www.nada.kth.se/~tony/abstracts/Lin08-EncCompSci.html.
- ^ a b C. Harris and M. Stephens (1988). "A combined corner and edge detector". Proceedings of the 4th Alvey Vision Conference: pages 147—151.
- ^ a b c K. Mikolajczyk and C. Schmid. Indexing based on scale invariant interest points. In Proceedings of the 8th International Conference on Computer Vision, Vancouver, Canada, pages 525-531, 2001.
- ^ Schmid, C., Mohr, R., and Bauckhage, C. 2000. Evaluation of interest point detectors. International Journal of Computer Vision, 37(2):151-172.
- ^ a b c d e f Mikolajczyk, K. and Schmid, C. 2004. Scale & affine invariant interest point detectors. International Journal on Computer Vision 60(1):63-86.
- ^ Spatial Filters: Laplacian/Laplacian of Gaussian
- ^ C. Schmid, R. Mohr, and C. Bauckhage. Comparing and evaluating interest points. In International Conference on Computer Vision, pp. 230-135, 1998.
- ^ J.Matas, O. Chum, M. Urban, and T. Pajdla, Robust wide baseline stereo from maximally stable extremal regions. In BMVC p. 384-393, 2002.
- ^ T. Tuytelaars and L. Van Gool, Matching widely separated views based on affine invariant regions. In IJCV 59(1):61-85, 2004.
- ^ T. Kadir, A. Zisserman, and M. Brady, An affine invariant salient region detector. In ECCV p. 404-416, 2004.
- ^ http://staff.science.uva.nl/~gevers/pub/overview.pdf
- ^ R. Datta, J. Li, and J. Z. Wang, “Content-based image retrieval - Approaches and trends of the new age,” In Proc. Int. Workshop on Multimedia Information Retrieval, pp. 253-262, 2005.IEEE Transactions on Multimedia, vol. 7, no. 1, pp. 127-142, 2005.
- ^ J. Sivic and A. Zisserman. Video google: A text retrieval approach to object matching in videos. In Proceedings of the International Conference on Computer Vision, Nice, France, 2003.
- ^ J. Sivic and A. Zisserman. Video data mining using configurations of viewpoint invariant regions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Washington DC, USA, pp. 488-495, 2004.
- ^ G. Dorko and C. Schmid. Selection of scale invariant neighborhoods for object class recognition. In Proceedings of International Conference on Computer Vision, Nice, France, pp. 634-640, 2003.