Hamming code
| Binary Hamming Codes | |
|---|---|
The Hamming(7,4)-code (with 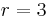 ) ) |
|
| Named after | Richard W. Hamming |
| Classification | |
| Type | Linear block code |
| Parameters | |
| Block length | 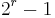 where where 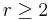 |
| Message length | 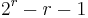 |
| Rate | 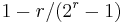 |
| Distance | 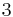 |
| Alphabet size | 2 |
| Notation | ![\left[2^r-1, 2^r-r-1,3 \right]_2](/2012-wikipedia_en_all_nopic_01_2012/I/47d3e1196ed0d82a48f9936ae15a6ac3.png) -code -code |
| Properties | |
| perfect code | |
In telecommunication, Hamming codes are a family of linear error-correcting codes that generalize the Hamming(7,4)-code invented by Richard Hamming in 1950. Hamming codes can detect up to two and correct up to one bit errors. By contrast, the simple parity code cannot correct errors, and can detect only an odd number of errors. Hamming codes are special in that they are perfect codes, that is, they achieve the highest possible rate for codes with their block length and minimum distance 3.[1]
In mathematical terms, Hamming codes are a class of binary linear codes. For each integer there is a code with block length 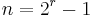 and message length
and message length 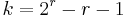 . Hence the rate of Hamming codes is
. Hence the rate of Hamming codes is 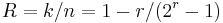 , which is highest possible for codes with distance and block length . The parity-check matrix of a Hamming code is constructed by listing all columns of length
, which is highest possible for codes with distance and block length . The parity-check matrix of a Hamming code is constructed by listing all columns of length 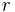 that are pairwise linearly independent.
that are pairwise linearly independent.
Because of the simplicity of Hamming codes, they are widely used in computer memory (RAM). In this context, one often uses an extended Hamming code with one extra parity bit. Extended Hamming codes achieve a distance of 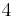 , which allows the decoder to distinguish between the situation in which at most one bit error occurred and the situation in which two bit errors occurred. In this sense, extended Hamming codes are single-error correcting and double-error detecting, and often referred to as SECDED.
, which allows the decoder to distinguish between the situation in which at most one bit error occurred and the situation in which two bit errors occurred. In this sense, extended Hamming codes are single-error correcting and double-error detecting, and often referred to as SECDED.
Contents |
History
Hamming worked at Bell Labs in the 1940s on the Bell Model V computer, an electromechanical relay-based machine with cycle times in seconds. Input was fed in on punched cards, which would invariably have read errors. During weekdays, special code would find errors and flash lights so the operators could correct the problem. During after-hours periods and on weekends, when there were no operators, the machine simply moved on to the next job.
Hamming worked on weekends, and grew increasingly frustrated with having to restart his programs from scratch due to the unreliability of the card reader. Over the next few years he worked on the problem of error-correction, developing an increasingly powerful array of algorithms. In 1950 he published what is now known as Hamming Code, which remains in use today in applications such as ECC memory.
Codes predating Hamming
A number of simple error-detecting codes were used before Hamming codes, but none were as effective as Hamming codes in the same overhead of space.
Parity
Parity adds a single bit that indicates whether the number of 1 bits in the preceding data was even or odd. If an odd number of bits is changed in transmission, the message will change parity and the error can be detected at this point. (Note that the bit that changed may have been the parity bit itself!) The most common convention is that a parity value of 1 indicates that there is an odd number of ones in the data, and a parity value of 0 indicates that there is an even number of ones in the data. In other words: the data and the parity bit together should contain an even number of 1s.
Parity checking is not very robust, since if the number of bits changed is even, the check bit will be valid and the error will not be detected. Moreover, parity does not indicate which bit contained the error, even when it can detect it. The data must be discarded entirely and re-transmitted from scratch. On a noisy transmission medium, a successful transmission could take a long time or may never occur. However, while the quality of parity checking is poor, since it uses only a single bit, this method results in the least overhead. Furthermore, parity checking does allow for the restoration of an erroneous bit when its position is known.
Two-out-of-five code
A two-out-of-five code is an encoding scheme which uses five digits consisting of exactly three 0s and two 1s. This provides ten possible combinations, enough to represent the digits 0 - 9. This scheme can detect all single bit-errors and all odd numbered bit-errors. However it still cannot correct for these errors.
Repetition
Another code in use at the time repeated every data bit several times in order to ensure that it got through. For instance, if the data bit to be sent was a 1, an n=3 repetition code would send "111". If the three bits received were not identical, an error occurred. If the channel is clean enough, most of the time only one bit will change in each triple. Therefore, 001, 010, and 100 each correspond to a 0 bit, while 110, 101, and 011 correspond to a 1 bit, as though the bits counted as "votes" towards what the original bit was. A code with this ability to reconstruct the original message in the presence of errors is known as an error-correcting code. This triple repetition code is actually the simplest Hamming code with 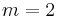 , since there are 2 parity bits, and
, since there are 2 parity bits, and 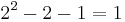 data bit.
data bit.
Such codes cannot correctly repair all errors, however. In our example, if the channel flipped two bits and the receiver got "001", the system would detect the error, but conclude that the original bit was 0, which is incorrect. If we increase the number of times we duplicate each bit to four, we can detect all two-bit errors but can't correct them (the votes "tie"); at five, we can correct all two-bit errors, but not all three-bit errors.
Moreover, the repetition code is extremely inefficient, reducing throughput by three times in our original case, and the efficiency drops drastically as we increase the number of times each bit is duplicated in order to detect and correct more errors.
Hamming codes
If more error-correcting bits are included with a message, and if those bits can be arranged such that different incorrect bits produce different error results, then bad bits could be identified. In a 7-bit message, there are seven possible single bit errors, so three error control bits could potentially specify not only that an error occurred but also which bit caused the error.
Hamming studied the existing coding schemes, including two-of-five, and generalized their concepts. To start with, he developed a nomenclature to describe the system, including the number of data bits and error-correction bits in a block. For instance, parity includes a single bit for any data word, so assuming ASCII words with 7-bits, Hamming described this as an (8,7) code, with eight bits in total, of which 7 are data. The repetition example would be (3,1), following the same logic. The code rate is the second number divided by the first, for our repetition example, 1/3.
Hamming also noticed the problems with flipping two or more bits, and described this as the "distance" (it is now called the Hamming distance, after him). Parity has a distance of 2, as any two bit flips will be invisible. The (3,1) repetition has a distance of 3, as three bits need to be flipped in the same triple to obtain another code word with no visible errors. A (4,1) repetition (each bit is repeated four times) has a distance of 4, so flipping two bits can be detected, but not corrected. When three bits flip in the same group there can be situations where the code corrects towards the wrong code word.
Hamming was interested in two problems at once; increasing the distance as much as possible, while at the same time increasing the code rate as much as possible. During the 1940s he developed several encoding schemes that were dramatic improvements on existing codes. The key to all of his systems was to have the parity bits overlap, such that they managed to check each other as well as the data.
General algorithm
The following general algorithm generates a single-error correcting (SEC) code for any number of bits.
- Number the bits starting from 1: bit 1, 2, 3, 4, 5, etc.
- Write the bit numbers in binary. 1, 10, 11, 100, 101, etc.
- All bit positions that are powers of two (have only one 1 bit in the binary form of their position) are parity bits.
- All other bit positions, with two or more 1 bits in the binary form of their position, are data bits.
- Each data bit is included in a unique set of 2 or more parity bits, as determined by the binary form of its bit position.
- Parity bit 1 covers all bit positions which have the least significant bit set: bit 1 (the parity bit itself), 3, 5, 7, 9, etc.
- Parity bit 2 covers all bit positions which have the second least significant bit set: bit 2 (the parity bit itself), 3, 6, 7, 10, 11, etc.
- Parity bit 4 covers all bit positions which have the third least significant bit set: bits 4–7, 12–15, 20–23, etc.
- Parity bit 8 covers all bit positions which have the fourth least significant bit set: bits 8–15, 24–31, 40–47, etc.
- In general each parity bit covers all bits where the binary AND of the parity position and the bit position is non-zero.
The form of the parity is irrelevant. Even parity is simpler from the perspective of theoretical mathematics, but there is no difference in practice.
This general rule can be shown visually:
-
Bit position 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 ... Encoded data bits p1 p2 d1 p4 d2 d3 d4 p8 d5 d6 d7 d8 d9 d10 d11 p16 d12 d13 d14 d15 Parity
bit
coveragep1 X X X X X X X X X X p2 X X X X X X X X X X p4 X X X X X X X X X p8 X X X X X X X X p16 X X X X X
Shown are only 20 encoded bits (5 parity, 15 data) but the pattern continues indefinitely. The key thing about Hamming Codes that can be seen from visual inspection is that any given bit is included in a unique set of parity bits. To check for errors, check all of the parity bits. The pattern of errors, called the error syndrome, identifies the bit in error. If all parity bits are correct, there is no error. Otherwise, the sum of the positions of the erroneous parity bits identifies the erroneous bit. For example, if the parity bits in positions 1, 2 and 8 indicate an error, then bit 1+2+8=11 is in error. If only one parity bit indicates an error, the parity bit itself is in error.
As you can see, if you have 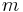 parity bits, it can cover bits from 1 up to
parity bits, it can cover bits from 1 up to 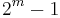 . If we subtract out the parity bits, we are left with
. If we subtract out the parity bits, we are left with 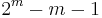 bits we can use for the data. As varies, we get all the possible Hamming codes:
bits we can use for the data. As varies, we get all the possible Hamming codes:
| Parity bits | Total bits | Data bits | Name | Rate |
|---|---|---|---|---|
| 2 | 3 | 1 | Hamming(3,1) (Triple repetition code) | 1/3 ≈ 0.333 |
| 3 | 7 | 4 | Hamming(7,4) | 4/7 ≈ 0.571 |
| 4 | 15 | 11 | Hamming(15,11) | 11/15 ≈ 0.733 |
| 5 | 31 | 26 | Hamming(31,26) | 26/31 ≈ 0.839 |
| ... | ||||
|
|
|
Hamming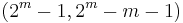 |
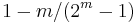 |
If, in addition, an overall parity bit (bit 0) is included, the code can detect (but not correct) any two-bit error, making a SECDED code. The overall parity indicates whether the total number of errors is even or odd. If the basic Hamming code detects an error, but the overall parity says that there are an even number of errors, an uncorrectable 2-bit error has occurred.
Hamming codes with additional parity (SECDED)
Hamming codes have a minimum distance of 3, which means that the decoder can detect and correct a single error, but it cannot distinguish a double bit error of some codeword from a single bit error of a different codeword. Thus, they can detect double-bit errors only if correction is not attempted.
To remedy this shortcoming, Hamming codes can be extended by an extra parity bit. This way, it is possible to increase the minimum distance of the Hamming code to 4, which allows the decoder to distinguish between single bit errors and two-bit errors. Thus the decoder can detect and correct a single error and at the same time detect (but not correct) a double error. If the decoder does not attempt to correct errors, it can detect up to 3 errors.
This extended Hamming code is popular in computer memory systems, where it is known as SECDED ("single error correction, double error detection"). Particularly popular is the (72,64) code, a truncated (127,120) Hamming code plus an additional parity bit, which has the same space overhead as a (9,8) parity code.
Hamming(7,4) code
In 1950, Hamming introduced the (7,4) code. It encodes 4 data bits into 7 bits by adding three parity bits. Hamming(7,4) can detect and correct single-bit errors. With the addition of an overall parity bit, it can also detect (but not correct) double-bit errors.
Construction of G and H
The matrix 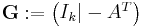 is called a (Canonical) generator matrix of a linear (n,k) code,
is called a (Canonical) generator matrix of a linear (n,k) code,
and 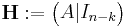 is called a parity-check matrix.
is called a parity-check matrix.
This is the construction of G and H in standard (or systematic) form. Regardless of form, G and H for linear block codes must satisfy
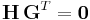 , an all-zeros matrix [Moon, p. 89].
, an all-zeros matrix [Moon, p. 89].
Since (7,4,3)=(n,k,d)=[2m − 1, 2m−1-m, m]. The parity-check matrix H of a Hamming code is constructed by listing all columns of length m that are pair-wise independent.
Thus H is a matrix whose left side is all of the nonzero n-tuples where order of the n-tuples in the columns of matrix does not matter. The right hand side is just the (n-k)-identity matrix.
So G can be obtained from H by taking the transpose of the left hand side of H with the identity k-identity matrix on the left hand side of G.
The code generator matrix 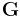 and the parity-check matrix
and the parity-check matrix 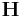 are:
are:
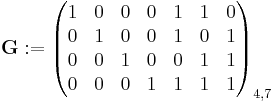
and
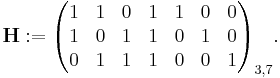
Finally, these matrices can be mutated into equivalent non-systematic codes by the following operations [Moon, p. 85]:
- Column permutations (swapping columns)
- Elementary row operations (replacing a row with a linear combination of rows)
Encoding
Example
From the above matrix we have 2k=24=16 codewords. The codewords 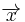 of this binary code can be obtained from
of this binary code can be obtained from 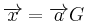 . With
. With 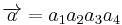 with
with 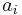 exist in
exist in 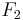 ( A field with two elements namely 0 and 1).
( A field with two elements namely 0 and 1).
Thus the codewords are all the 4-tuples (k-tuples).
Therefore,
(1,0,1,1) gets encoded as (1,0,1,1,0,1,0).
Hamming(7,4) code with an additional parity bit
The Hamming(7,4) can easily be extended to an (8,4) code by adding an extra parity bit on top of the (7,4) encoded word (see Hamming(7,4)). This can be summed up with the revised matrices:

and

Note that H is not in standard form. To obtain G, elementary row operations can be used to obtain an equivalent matrix to H in systematic form:

For example, the first row in this matrix is the sum of the second and third rows of H in non-systematic form. Using the systematic construction for Hamming codes from above, the matrix A is apparent and the systematic form of G is written as

The non-systematic form of G can be row reduced (using elementary row operations) to match this matrix.
The addition of the fourth row effectively computes the sum of all the codeword bits (data and parity) as the fourth parity bit.
For example, 1011 is encoded into 01100110 where blue digits are data; red digits are parity from the Hamming(7,4) code; and the green digit is the parity added by Hamming(8,4). The green digit makes the parity of the (7,4) code even.
Finally, it can be shown that the minimum distance has increased from 3, as with the (7,4) code, to 4 with the (8,4) code. Therefore, the code can be defined as Hamming(8,4,4).
See also
- Golay code
- Reed–Muller code
- Reed–Solomon error correction
- Turbo code
- Low-density parity-check code
- Hamming bound
Notes
References
- Moon, Todd K. (2005). Error Correction Coding. New Jersey: John Wiley & Sons. ISBN 978-0-471-64800-0. http://www.neng.usu.edu/ece/faculty/tmoon/eccbook/book.html.
- MacKay, David J.C. (September 2003). Information Theory, Inference and Learning Algorithms. Cambridge: Cambridge University Press. ISBN 0-521-64298-1. http://www.inference.phy.cam.ac.uk/mackay/itila/book.html.
- D.K. Bhattacharryya, S. Nandi. "An efficient class of SEC-DED-AUED codes". 1997 International Symposium on Parallel Architectures, Algorithms and Networks (ISPAN '97). pp. 410–415. doi:10.1109/ISPAN.1997.645128.
External links