Generic-case complexity
Generic-case complexity is a subfield of computational complexity theory that studies the complexity of computational problems on "most inputs".
Generic-case complexity is a way of measuring the complexity of a computational problem by neglecting a small set of unrepresentative inputs and considering worst-case complexity on the rest. Small is defined in terms of asymptotic density. The apparent efficacy of generic case complexity is because for a wide variety of concrete computational problems, the most difficult instances seem to be rare. Typical instances are relatively easy.
This approach to complexity originated in combinatorial group theory, which has a computational tradition going back to the beginning of the last century. The notion of generic complexity was introduced in [1] where authors showed that for a large class of finitely generated groups the generic time complexity of some classical decision problems from combinatorial group theory, namely the word problem, conjugacy problem and membership problem, are linear.
A detailed introduction of generic case complexity can be found in the surveys ,[2] .[3]
Contents |
Basic definitions
Asymptotic density
Let I be an infinite set of inputs for a computational problem.
Definition 1. A size function on I is a map 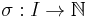 with infinite range. The ball of radius n is
with infinite range. The ball of radius n is 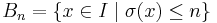 .
.
If the inputs are coded as strings over a finite alphabet, size might be the string length.
Let 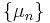 be an ensemble of probability distributions where
be an ensemble of probability distributions where 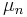 is a probability distribution on
is a probability distribution on 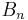 . If the balls are finite, then each can be taken to be the equiprobable distribution which is the most common case. Notice that only finitely many 's can be empty or have
. If the balls are finite, then each can be taken to be the equiprobable distribution which is the most common case. Notice that only finitely many 's can be empty or have 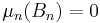 ; we ignore them.
; we ignore them.
Definition 2. The asymptotic density of a subset 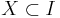 is
is 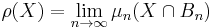 when this limit exists.
when this limit exists.
When the balls are finite and is the equiprobable measure,
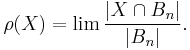
In this case it is often convenient to use spheres 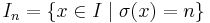 instead of balls and define
instead of balls and define 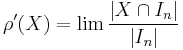 . An argument using Stolz theorem shows that
. An argument using Stolz theorem shows that 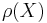 exists if
exists if 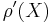 does, and in that case they are equal.
does, and in that case they are equal.
Definition 3 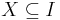 is generic if
is generic if 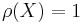 and negligible if
and negligible if 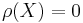 . X is exponentially (superpolynomially) generic if the convergence to the limit in Definition 2 is exponentially (superpolynomially) fast, etc.
. X is exponentially (superpolynomially) generic if the convergence to the limit in Definition 2 is exponentially (superpolynomially) fast, etc.
A generic subset X is asymptotically large. Whether X appears large in practice depends on how fast 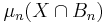 converges to 1. Superpolynomial convergence seems to be fast enough.
converges to 1. Superpolynomial convergence seems to be fast enough.
Generic complexity classes
Definition 4 An algorithm is in GenP (generically polynomial time) if it never gives incorrect answers and if it gives correct answers in polynomial time on a generic set of inputs. A problem is in GenP if it admits an algorithm in GenP. Likewise for GenL (generically linear time), GenE (generically exponential time with a linear exponent) GenExp (generically exponential time), etc. ExpGenP is the subclass of GenP for which the relevant generic set is exponentially generic.
More generally for any 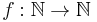 we can define the class Gen(f) corresponding to time complexity O(f) on a generic set of input.
we can define the class Gen(f) corresponding to time complexity O(f) on a generic set of input.
Definition 5. An algorithm solves a problem generically if it never gives incorrect answers and if it gives correct answers on a generic set of inputs. A problem is generically solvable if it is solved generically by some algorithm.
Theory and applications
Combinatorial group theory problems.
- The famous undecidable problems: the word, conjugacy and membership decision problems are in generically polynomial.[1]
- The word and conjugacy search problems are in GenP for all fixed finitely presented groups.[4]
- The well known coset enumeration procedure admits a computable upper bound on a generic set of inputs.[5]
- The Whitehead algorithm for testing whether or not one element of a free group is mapped to another by an automorphism has an exponential worst case upper bound but runs well in practice. The algorithm is shown to be in GenL.[6]
- The conjugacy problem in HNN extensions can be unsolvable even for free groups. However, it is generically cubic time[7]
The halting problem and the Post correspondence problem.
- The halting problem for Turing machine with one-sided tape is easily decidable most of the time; it is in GenP[8]
The situation for two-sided tape is unknown. However, there is a kind of lower bound for machines of both types. The halting problem is not in ExpGenP for any model of Turing machine,[9][10]
- The Post correspondence problem is in ExpGenP.[2]
= Presburger arithmetic
The decision problem for Presburger arithmetic admits a double exponential worst case lower bound [11] and a triple exponential worst case upper bound. The generic complexity is not known, but it is known that the problem is not in ExpGenP [12]
NP complete problems
As it is well known that NP-complete problems can be easy on average, it is not a surprise that several of them are generically easy too.
- The three satisfiability problem is in ExpGenP [13]
- The subset sum problem is in GenP.[2]
One way functions
There is a generic complexity version of a one-way function [14] which yields the same class of functions but allows one to consider different security assumptions than usual.
Public-key cryptography
A series of articles,[15][16][17] is devoted to cryptanalysis of the Anshel–Anshel–Goldfeld key exchange protocol, whose security is based on assumptions about the braid group. This series culminates in [18] which applies techniques from generic case complexity to obtain a complete analysis of the length based attack and the conditions under which it works. The generic point of view also suggests a kind of new attack called the quotient attack, and a more secure version of the Anshel–Anshel–Goldfeld protocol.
List of general theoretical results
- A famous Rice's theorem states that if F is a subset of the set of partial computable functions from
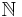 to
to 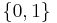 , then unless F or its complement is empty, the problem of deciding whether or not a particular Turing machine computes a function in F is undecidable. The following theorem gives a generic version.
, then unless F or its complement is empty, the problem of deciding whether or not a particular Turing machine computes a function in F is undecidable. The following theorem gives a generic version.
Theorem 1 [19] Let I be the set of all Turing machines. If F is a subset of the set of all partial computable function from to itself such that F and its complement are both non-empty, then the problem of deciding whether or not a given Turing machine computes a function from F is not decidable on any exponentially generic subset of I.
- The following theorems are from.[1]
Theorem 2 The set of formal languages which are generically computable has measure zero.
Theorem 3 There is an infinite hierarchy of generic complexity classes. More precisely for a proper complexity function f, 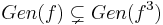 .
.
- The next theorem shows that just as there are average case complete problems within distributional NP problems,
there are also generic case complete problems. The arguments in the generic case are similar to those in the average case, and the generic case complete problem is also average case complete. It is the distributional bounded halting problem.
Theorem 4 [2] There is a notion of generic-polynomial-time reduction with respect to which the distributional bounded halting problem is complete within class of distributional NP problems.
Comparisons with previous work
Almost polynomial time
Meyer and Paterson [20] define an algorithm to be almost polynomial time, or APT, if it halts within p(n) steps on all but p(n) inputs of size n. Clearly APT algorithms are included in our class GenP. We have seen several NP complete problems in GenP, but Meyer and Paterson show that this is not the case for APT. They prove that an NP complete problem is reducible to a problem in APT if and only if P = NP. Thus APT seems much more restrictive than GenP.
Average-case complexity
Generic case complexity is similar to average-case complexity. However there are some significant differences. Generic case complexity is a direct measure of the performance of an algorithm on most inputs while average case complexity gives a measure of the balance between easy and difficult instances. In addition Generic-case complexity naturally applies to undecidable problems.
Suppose 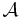 is an algorithm whose time complexity,
is an algorithm whose time complexity, 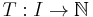 is polynomial on
is polynomial on 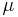 average. What can we infer about the behavior of on typical inputs?
average. What can we infer about the behavior of on typical inputs?
Example 1 Let I be the set of all words over and define the size 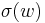 to be word length,
to be word length, 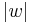 . Define
. Define 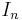 to be the set of words of length n, and assume that each is the equiprobable measure. Suppose that T(w)=n for all but one word in each , and
to be the set of words of length n, and assume that each is the equiprobable measure. Suppose that T(w)=n for all but one word in each , and 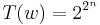 on the exceptional words.
on the exceptional words.
In this example T is certainly polynomial on typical inputs, but T is not polynomial on average. T is in GenP.
Example 2 Keep I and 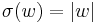 as before, but define
as before, but define 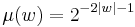 and
and 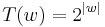 . T is polynomial on average even though it is exponential on typical inputs. T is not in GenP.
. T is polynomial on average even though it is exponential on typical inputs. T is not in GenP.
In these two examples the generic complexity is more closely related to behavior on typical inputs than average case complexity. Average case complexity measures something else: the balance between the frequency of difficult instances and the degree of difficulty,.[21][22] Roughly speaking an algorithm which is polynomial time on average can have only a subpolynomial fraction of inputs that require superpolynomial time to compute.
Nevertheless in some cases generic and average case complexity are quite close to each other. A function 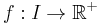 is polynomial on -average on spheres if there exists
is polynomial on -average on spheres if there exists 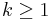 such that
such that 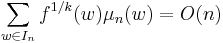 where is the ensemble induced by . If f is polynomial on -average on spheres, the f is polynomial on -average, and for many distributions the converse holds [23]
where is the ensemble induced by . If f is polynomial on -average on spheres, the f is polynomial on -average, and for many distributions the converse holds [23]
Theorem 5 [2] If a function is polynomial on -average on spheres then f is generically polynomial relative to the spherical asymptotic density 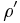 .
.
Theorem 6 [2] Suppose a complete algorithm has subexponential time bound T and a partial algorithm 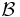 for the same problem is in ExpGenP with respect to the ensemble corresponding to a probability measure on the inputs I for . Then there is a complete algorithm which is -average time complexity.
for the same problem is in ExpGenP with respect to the ensemble corresponding to a probability measure on the inputs I for . Then there is a complete algorithm which is -average time complexity.
Errorless heuristic algorithms
In a 2006 paper, Bogdanov and Trevisan came close to defining generic case complexity.[24] Instead of partial algorithms, they consider so-called errorless heuristic algorithms. These are complete algorithms which may fail by halting with output "?". The class AvgnegP is defined to consist of all errorless heuristic algorithms A which run in polynomial time and for which the probability of failure on is negligible, i.e., converges superpolynomially fast to 0. AvgnegP is a subset of GenP. Errorless heuristic algorithms are essentially the same as the algorithms with benign faults defined by Impagliazzo where polynomial time on average algorithms are characterized in terms of so-called benign algorithm schemes.
References
- ^ a b c I. Kapovich, A. Myasnikov, P. Schupp and V. Shpilrain, Generic case complexity, decision problems in group theory and random walks, J. Algebra, vol 264 (2003), 665–694.
- ^ a b c d e f R. Gilman, A. G. Miasnikov, A. D. Myasnikov, and A. Ushakov, Generic Case Complexity, unpublished first draft of a book, 143 pages.
- ^ R. Gilman, A. G. Miasnikov, A. D. Myasnikov, and A. Ushakov, Report on generic case complexity, Herald of Omsk University, Special Issue, 2007, 103–110.
- ^ A. Ushakov, Dissertation, City University of New York, 2005.
- ^ R. Gilman, Hard problems in group theory, talk given at the International Conference on Geometric and Combinatorial Methods in Group Theory and Semigroup Theory, May 18, 2009.
- ^ I. Kapovich, P. Schupp, V. Shpilrain, Generic properties of Whiteheads algorithm and isomorphism rigidity of random one-relator groups, Pacific J. Math. 223 (2006)
- ^ A.V. Borovik, A.G. Myasnikov, V.N. Remeslennikov, Generic complexity of the conjugacy problem in HNN-extensions and algorithmic stratification of Miller's groups, Internat. J. Algebra Comput. 17 (2007), 963–997.
- ^ J. D. Hamkins and A. Miasnikov, The halting problem is decidable on a set of asymptotic probability one, Notre Dame J. Formal Logic 47 (2006), 515–524.
- ^ A. Miasnikov and A. Rybalov, Generic complexity of undecidable problems, J. Symbolic Logic 73 (2008), 656–673.
- ^ A. Rybalov, On the strongly generic undecidability of the halting problem, Theoret. Comput. Sci. 377 (2007), 268–270.
- ^ M. J. Fischer and M. O. Rabin, Super-Exponential Complexity of Presburger Arithmetic, Proceedings of the SIAM-AMS Symposium in Applied Mathematics 7 (1974) 2741.
- ^ A. Rybalov, Generic complexity of Presburger arithmetic, 356–361 in Second International Symposium on Computer Science in Russia, CSR 2007, Lecture Notes in Computer Science 4649, Springer 2007.
- ^ R. Gilman, A. G. Miasnikov, A. D. Myasnikov, and A. Ushakov, Report on generic case complexity, Herald of Omsk University, Special Issue, 2007, 103–110.
- ^ A. D. Myasnikov, Generic Complexity and One-Way Functions, Groups, Complexity and Cryptography, 1, (2009), 13–31.
- ^ R. Gilman, A. G. Miasnikov, A. D. Myasnikov, and A. Ushakov, New developments in commutator key exchange, Proc. First Int. Conf. on Symbolic Computation and Cryptography (SCC-2008), Beijing, 2008.
- ^ A. G. Myasnikov, V. Shpilrain, A. Ushakov, A practical attack on a braid group based cryptographic protocol, in Lecture Notes in Computer Science, 3621, Springer Verlag, 2005, 86–96.
- ^ A. D. Myasnikov, and A. Ushakov, Length based attack and braid groups: cryptanalysis of Anshel–Anshel–Goldfeld key exchange protocol, in Public Key Cryptography PKC 2007, 76–88, Lecture Notes in Comput. Sci., 4450, Springer, Berlin, 2007.
- ^ A. G. Miasnikov and A. Ushakov, Random subgroups and analysis of the length-based and quotient attacks, Journal of Mathematical Cryptology, 2 (2008), 29–61.
- ^ A. Miasnikov and A. Rybalov, Generic complexity of undecidable problems, J. Symbolic Logic 73 (2008), 656–673.
- ^ A. R. Meyer and M. S. Paterson, With what frequency are apparently intractable problems difficult?, M.I.T. Technical Report, MIT/LCS/TM-126, February, 1979.
- ^ Y. Gurevich, The challenger-solver game: variations on the theme of P =?NP, Logic in Computer Science Column, The Bulletin of the EATCS, October 1989, p.112-121.
- ^ R. Impagliazzo, A personal view of average-case complexity, in Proceedings of the 10th Annual Structure in Complexity Theory Conference - SCT 1995, IEEE Computer Society, 1995, page 134.
- ^ Y. Gurevich, Average case completeness, J. of Computer and System Science, 42 (1991), 346–398.
- ^ A. Bogdanov, L. Trevisan, Average-case Complexity, Found. Trends Theor. Comput. Sci. 2, No. 1, 111 p. (2006)..