Generalized minimal residual method
In mathematics, the generalized minimal residual method (usually abbreviated GMRES) is an iterative method for the numerical solution of a system of linear equations. The method approximates the solution by the vector in a Krylov subspace with minimal residual. The Arnoldi iteration is used to find this vector.
The GMRES method was developed by Yousef Saad and Martin H. Schultz in 1986.[1] GMRES is a generalization of the MINRES method to developed by Chris Paige and Michael Saunders in 1975 . GMRES also is a special case of the DIIS method developed by Peter Pulay in 1980. DIIS is also applicable to non-linear systems.
Contents |
The method
Denote the Euclidean norm of any vector v by ||v||. Denote the system of linear equations to be solved by

The matrix A is assumed to be invertible of size m-by-m. Furthermore, it is assumed that b is normalized, i.e., that ||b|| = 1.
The nth Krylov subspace for this problem is
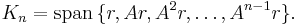
GMRES approximates the exact solution of Ax = b by the vector xn ∈ Kn that minimizes the Euclidean norm of the residual Axn − b.
The vectors r, Ar, …, An−1r might be almost linearly dependent, so instead of this basis, the Arnoldi iteration is used to find orthonormal vectors
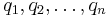
which form a basis for Kn. Hence, the vector xn ∈ Kn can be written as xn = Qnyn with yn ∈ Rn, where Qn is the m-by-n matrix formed by q1, …, qn.
The Arnoldi process also produces an (n+1)-by-n upper Hessenberg matrix 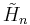 with
with
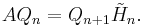
Because 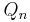 is orthogonal, we have
is orthogonal, we have
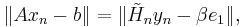
where
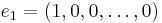
is the first vector in the standard basis of Rn+1, and
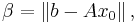
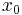 being the first trial vector (usually zero). Hence,
being the first trial vector (usually zero). Hence, 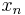 can be found by minimizing the Euclidean norm of the residual
can be found by minimizing the Euclidean norm of the residual
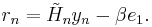
This is a linear least squares problem of size n.
This yields the GMRES method. At every step of the iteration:
- do one step of the Arnoldi method;
- find the
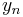 which minimizes ||rn||;
which minimizes ||rn||; - compute
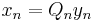 ;
; - repeat if the residual is not yet small enough.
At every iteration, a matrix-vector product Aqn must be computed. This costs about 2m2 floating-point operations for general dense matrices of size m, but the cost can decrease to O(m) for sparse matrices. In addition to the matrix-vector product, O(n m) floating-point operations must be computed at the nth iteration.
Convergence
The nth iterate minimizes the residual in the Krylov subspace Kn. Since every subspace is contained in the next subspace, the residual decreases monotonically. After m iterations, where m is the size of the matrix A, the Krylov space Km is the whole of Rm and hence the GMRES method arrives at the exact solution. However, the idea is that after a small number of iterations (relative to m), the vector xn is already a good approximation to the exact solution.
This does not happen in general. Indeed, a theorem of Greenbaum, Pták and Strakoš states that for every monotonically decreasing sequence a1, …, am−1, am = 0, one can find a matrix A such that the ||rn|| = an for all n, where rn is the residual defined above. In particular, it is possible to find a matrix for which the residual stays constant for m − 1 iterations, and only drops to zero at the last iteration.
In practice, though, GMRES often performs well. This can be proven in specific situations. If A is positive definite, then
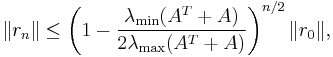
where 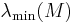 and
and 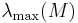 denote the smallest and largest eigenvalue of the matrix
denote the smallest and largest eigenvalue of the matrix 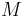 , respectively.
, respectively.
If A is symmetric and positive definite, then we even have
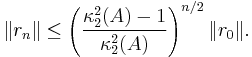
where 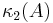 denotes the condition number of A in the Euclidean norm.
denotes the condition number of A in the Euclidean norm.
In the general case, where A is not positive definite, we have
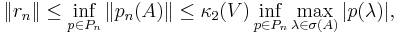
where Pn denotes the set of polynomials of degree at most n with p(0) = 1, V is the matrix appearing in the spectral decomposition of A, and σ(A) is the spectrum of A. Roughly speaking, this says that fast convergence occurs when the eigenvalues of A are clustered away from the origin and A is not too far from normality.[2]
All these inequalities bound only the residuals instead of the actual error, that is, the distance between the current iterate xn and the exact solution.
Extensions of the method
Like other iterative methods, GMRES is usually combined with a preconditioning method in order to speed up convergence.
The cost of the iterations grow like O(n2), where n is the iteration number. Therefore, the method is sometimes restarted after a number, say k, of iterations, with xk as initial guess. The resulting method is called GMRES(k).
Comparison with other solvers
The Arnoldi iteration reduces to the Lanczos iteration for symmetric matrices. The corresponding Krylov subspace method is the minimal residual method (MinRes) of Paige and Saunders. Unlike the unsymmetric case, the MinRes method is given by a three-term recurrence relation. It can be shown that there is no Krylov subspace method for general matrices, which is given by a short recurrence relation and yet minimizes the norms of the residuals, as GMRES does.
Another class of methods builds on the unsymmetric Lanczos iteration, in particular the BiCG method. These use a three-term recurrence relation, but they do not attain the minimum residual, and hence the residual does not decrease monotonically for these methods. Convergence is not even guaranteed.
The third class is formed by methods like CGS and BiCGSTAB. These also work with a three-term recurrence relation (hence, without optimality) and they can even terminate prematurely without achieving convergence. The idea behind these methods is to choose the generating polynomials of the iteration sequence suitably.
None of these three classes is the best for all matrices; there are always examples in which one class outperforms the other. Therefore, multiple solvers are tried in practice to see which one is the best for a given problem.
Solving the least squares problem
One part of the GMRES method is to find the vector which minimizes
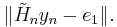
Note that is an (n+1)-by-n matrix, hence it gives an over-constrained linear system of n+1 equations for n unknowns.
The minimum can be computed using a QR decomposition: find an (n+1)-by-(n+1) orthogonal matrix Ωn and an (n+1)-by-n upper triangular matrix 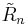 such that
such that
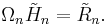
The triangular matrix has one more row than it has columns, so its bottom row consists of zero. Hence, it can be decomposed as
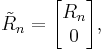
where 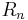 is an n-by-n (thus square) triangular matrix.
is an n-by-n (thus square) triangular matrix.
The QR decomposition can be updated cheaply from one iteration to the next, because the Hessenberg matrices differ only by a row of zeros and a column:
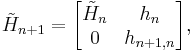
where hn = (h1n, … hnn)T. This implies that premultiplying the Hessenberg matrix with Ωn, augmented with zeroes and a row with multiplicative identity, yields almost a triangular matrix:
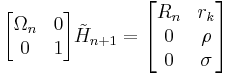
This would be triangular if σ is zero. To remedy this, one needs the Givens rotation
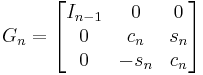
where
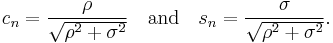
With this Givens rotation, we form
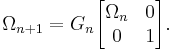
Indeed,
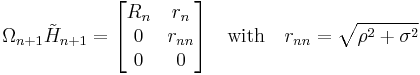
is a triangular matrix.
Given the QR decomposition, the minimization problem is easily solved by noting that
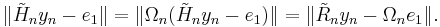
Denoting the vector 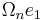 by
by
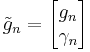
with gn ∈ Rn and γn ∈ R, this is
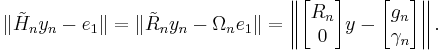
The vector y that minimizes this expression is given by
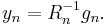
Again, the vectors 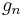 are easy to update.[3]
are easy to update.[3]
See also
Notes
References
- A. Meister, Numerik linearer Gleichungssysteme, 2nd edition, Vieweg 2005, ISBN 978-3-528-13135-7.
- Y. Saad, Iterative Methods for Sparse Linear Systems, 2nd edition, Society for Industrial and Applied Mathematics, 2003. ISBN 978-0-89871-534-7.
- Y. Saad and M.H. Schultz, "GMRES: A generalized minimal residual algorithm for solving nonsymmetric linear systems", SIAM J. Sci. Stat. Comput., 7:856-869, 1986. doi:10.1137/0907058.
- J. Stoer and R. Bulirsch, Introduction to numerical analysis, 3rd edition, Springer, New York, 2002. ISBN 978-0-387-95452-3.
- Lloyd N. Trefethen and David Bau, III, Numerical Linear Algebra, Society for Industrial and Applied Mathematics, 1997. ISBN 978-0-89871-361-9.
- Dongarra et al. , Templates for the Solution of Linear Systems: Building Blocks for Iterative Methods, 2nd Edition, SIAM, Philadelphia, 1994
|
||||||||||||||