Gauss–Markov theorem
In statistics, the Gauss–Markov theorem, named after Carl Friedrich Gauss and Andrey Markov, states that in a linear regression model in which the errors have expectation zero and are uncorrelated and have equal variances, the best linear unbiased estimator (BLUE) of the coefficients is given by the ordinary least squares estimator. Here "best" means giving the lowest possible mean squared error of the estimate. The errors need not be normal, nor independent and identically distributed (only uncorrelated and homoscedastic).
Contents |
Statement
Suppose we have
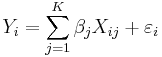
for i = 1, . . ., n, where β j are non-random but unobservable parameters, Xij are non-random and observable (called the "explanatory variables"), ε i are random, and so Y i are random. The random variables ε i are called the "errors" (not to be confused with "residuals"; see errors and residuals in statistics). Note that to include a constant in the model above, one can choose to include the variable XK all of whose observed values are unity: XiK = 1 for all i.
The Gauss–Markov assumptions state that
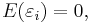
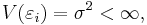
(i.e., all errors have the same variance; that is "homoscedasticity"), and
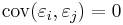
for i ≠ j; that is, any two different values of the error term are drawn from "uncorrelated" distributions. A linear estimator of β j is a linear combination
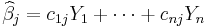
in which the coefficients cij are not allowed to depend on the underlying coefficients βj, since those are not observable, but are allowed to depend on the values Xij, since these data are observable. (The dependence of the coefficients on each Xij is typically nonlinear; the estimator is linear in each Yi and hence in each random εi, which is why this is "linear" regression.) The estimator is said to be unbiased if and only if
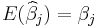
regardless of the values of Xij. Now, let 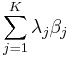 be some linear combination of the coefficients. Then the mean squared error of the corresponding estimation is
be some linear combination of the coefficients. Then the mean squared error of the corresponding estimation is
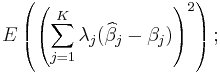
i.e., it is the expectation of the square of the weighted sum (across parameters) of the differences between the estimators and the corresponding parameters to be estimated. (Since we are considering the case in which all the parameter estimates are unbiased, this mean squared error is the same as the variance of the linear combination.) The best linear unbiased estimator (BLUE) of the vector β of parameters βj is one with the smallest mean squared error for every vector λ of linear combination parameters. This is equivalent to the condition that
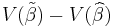
is a positive semi-definite matrix for every other linear unbiased estimator 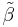 .
.
The ordinary least squares estimator (OLS) is the function
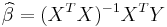
of Y and X that minimizes the sum of squares of residuals (misprediction amounts):
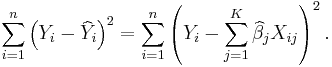
The theorem now states that the OLS estimator is a BLUE. The main idea of the proof is that the least-squares estimator is uncorrelated with every linear unbiased estimator of zero, i.e., with every linear combination  whose coefficients do not depend upon the unobservable β but whose expected value is always zero.
whose coefficients do not depend upon the unobservable β but whose expected value is always zero.
Proof
Let 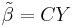 be another linear estimator of
be another linear estimator of 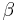 and let C be given by
and let C be given by 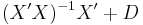 , where D is a
, where D is a  nonzero matrix. As we're restricting to unbiased estimators, minimum mean squared error implies minimum variance. The goal is therefore to show that such an estimator has a variance no smaller than that of
nonzero matrix. As we're restricting to unbiased estimators, minimum mean squared error implies minimum variance. The goal is therefore to show that such an estimator has a variance no smaller than that of 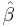 , the OLS estimator.
, the OLS estimator.
The expectation of is:
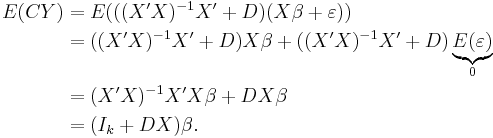
Therefore, is unbiased if and only if 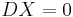 .
.
The variance of is
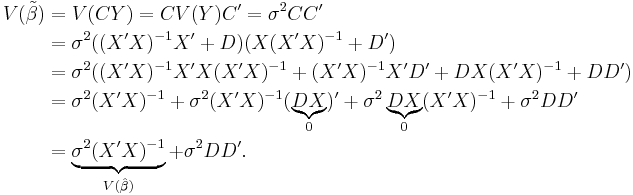
Since DD' is a positive semidefinite matrix, 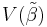 exceeds
exceeds 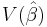 by a positive semidefinite matrix.
by a positive semidefinite matrix.
Generalized least squares estimator
The generalized least squares (GLS) or Aitken estimator extends the Gauss–Markov theorem to the case where the error vector has a non-scalar covariance matrix – the Aitken estimator is also a BLUE.[1]
See also
Other unbiased statistics
Notes
- ^ A. C. Aitken, "On Least Squares and Linear Combinations of Observations", Proceedings of the Royal Society of Edinburgh, 1935, vol. 55, pp. 42–48.
References
- Plackett, R.L. (1950). "Some Theorems in Least Squares". Biometrika 37 (1-2): 149–157. doi:10.1093/biomet/37.1-2.149. JSTOR 2332158. MR36980.
External links
- Earliest Known Uses of Some of the Words of Mathematics: G (brief history and explanation of the name)
- Proof of the Gauss Markov theorem for multiple linear regression (makes use of matrix algebra)
- A Proof of the Gauss Markov theorem using geometry
|
||||||||||||||||||||||||||||||||||||||||||||||