Fuzz testing
Fuzz testing or fuzzing is a software testing technique, often automated or semi-automated, that involves providing invalid, unexpected, or random data to the inputs of a computer program. The program is then monitored for exceptions such as crashes or failing built-in code assertions. Fuzzing is commonly used to test for security problems in software or computer systems.
The term first originates from a class project at the University of Wisconsin 1988 although similar techniques have been used in the field of quality assurance, where they are referred to as robustness testing, syntax testing or negative testing.
There are two forms of fuzzing program; mutation-based and generation-based, which can be employed as white-, grey- or black-box testing.[1] File formats and network protocols are the most common targets of testing, but any type of program input can be fuzzed. Interesting inputs include environment variables, keyboard and mouse events, and sequences of API calls. Even items not normally considered "input" can be fuzzed, such as the contents of databases, shared memory, or the precise interleaving of threads.
For the purpose of security, input that crosses a trust boundary is often the most interesting.[2] For example, it is more important to fuzz code that handles the upload of a file by any user than it is to fuzz the code that parses a configuration file that is accessible only to a privileged user.
Contents |
History
The term "fuzz" or "fuzzing" originates from a 1988 class project at the University of Wisconsin, taught by Professor Barton Miller. The assignment was titled "Operating System Utility Program Reliability - The Fuzz Generator".[3][4] The project developed a basic command-line fuzzer to test the reliability of Unix programs by bombarding them with random data until they crashed. The test was repeated in 1995, expanded to include testing of GUI-based tools (X Windows), network protocols, and system library APIs.[1] Follow-on work included testing command- and GUI-based applications on both Windows and MacOS X.
One of the earliest examples of fuzzing dates from before 1983. "The Monkey" was a Macintosh application developed by Steve Capps prior to 1983. It used journaling hooks to feed random events into Mac programs, and was used to test for bugs in MacPaint.[5]
Uses
Fuzz testing is often employed as a black-box testing methodology in large software projects where a budget exists to develop test tools. Fuzz testing is one of the techniques that offers a high benefit-to-cost ratio.[6]
The technique can only provide a random sample of the system's behavior, and in many cases passing a fuzz test may only demonstrate that a piece of software can handle exceptions without crashing, rather than behaving correctly. This means fuzz testing is an assurance of overall quality, rather than a bug-finding tool, and not a substitute for exhaustive testing or formal methods.
As a gross measurement of reliability, fuzzing can suggest which parts of a program should get special attention, in the form of a code audit, application of static analysis, or partial rewrites.
Types of bugs
As well as testing for outright crashes, fuzz testing is used to find bugs such as assertion failures and memory leaks (when coupled with a memory debugger). The methodology is useful against large applications, where any bug affecting memory safety is likely to be a severe vulnerability.
Since fuzzing often generates invalid input it is used for testing error-handling routines, which are important for software that does not control its input. Simple fuzzing can be thought of as a way to automate negative testing.
Fuzzing can also find some types of "correctness" bugs. For example, it can be used to find incorrect-serialization bugs by complaining whenever a program's serializer emits something that the same program's parser rejects.[7] It can also find unintentional differences between two versions of a program[8] or between two implementations of the same specification.[9]
Techniques
Fuzzing programs fall into two different categories. Mutation based fuzzers mutate existing data samples to create test data while generation based fuzzers define new test data based on models of the input.[1]
The simplest form of fuzzing technique is sending a stream of random bits to software, either as command line options, randomly mutated protocol packets, or as events. This technique of random inputs still continues to be a powerful tool to find bugs in command-line applications, network protocols, and GUI-based applications and services. Another common technique that is easy to implement is mutating existing input (e.g. files from a test suite) by flipping bits at random or moving blocks of the file around. However, the most successful fuzzers have detailed understanding of the format or protocol being tested.
The understanding can be based on a specification. A specification-based fuzzer involves writing the entire array of specifications into the tool, and then using model-based test generation techniques in walking through the specifications and adding anomalies in the data contents, structures, messages, and sequences. This "smart fuzzing" technique is also known as robustness testing, syntax testing, grammar testing, and (input) fault injection.[10][11][12][13] The protocol awareness can also be created heuristically from examples using a tool such as Sequitur.[14] These fuzzers can generate test cases from scratch, or they can mutate examples from test suites or real life. They can concentrate on valid or invalid input, with mostly-valid input tending to trigger the "deepest" error cases.
There are two limitations of protocol-based fuzzing based on protocol implementations of published specifications: 1) Testing cannot proceed until the specification is relatively mature, since a specification is a prerequisite for writing such a fuzzer; and 2) Many useful protocols are proprietary, or involve proprietary extensions to published protocols. If fuzzing is based only on published specifications, test coverage for new or proprietary protocols will be limited or nonexistent.
Fuzz testing can be combined with other testing techniques. White-box fuzzing uses symbolic execution and constraint solving.[15] Evolutionary fuzzing leverages feedback from code coverage,[16] effectively automating the approach of exploratory testing.
Reproduction and isolation
Test case reduction is the process of extracting minimal test cases from an initial test case.[17][18] Test case reduction may be done manually, or using software tools, and usually involves a divide-and-conquer strategy where parts of the test are removed one by one until only the essential core of the test case remains.
So as to be able to reproduce errors, fuzzing software will often record the input data it produces, usually before applying it to the software. If the computer crashes outright, the test data is preserved. If the fuzz stream is pseudo-random number-generated, the seed value can be stored to reproduce the fuzz attempt. Once a bug is found, some fuzzing software will help to build a test case, which is used for debugging, using test case reduction tools such as Delta or Lithium.
Advantages and disadvantages
The main problem with fuzzing to find program faults is that it generally only finds very simple faults. The computational complexity of the software testing problem is of exponential order (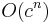 ,
, 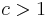 ) and every fuzzer takes shortcuts to find something interesting in a timeframe that a human cares about. A primitive fuzzer may have poor code coverage; for example, if the input includes a checksum which is not properly updated to match other random changes, only the checksum validation code will be verified. Code coverage tools are often used to estimate how "well" a fuzzer works, but these are only guidelines to fuzzer quality. Every fuzzer can be expected to find a different set of bugs.
) and every fuzzer takes shortcuts to find something interesting in a timeframe that a human cares about. A primitive fuzzer may have poor code coverage; for example, if the input includes a checksum which is not properly updated to match other random changes, only the checksum validation code will be verified. Code coverage tools are often used to estimate how "well" a fuzzer works, but these are only guidelines to fuzzer quality. Every fuzzer can be expected to find a different set of bugs.
On the other hand, bugs found using fuzz testing are sometimes severe, exploitable bugs that could be used by a real attacker. This has become more common as fuzz testing has become more widely known, as the same techniques and tools are now used by attackers to exploit deployed software. This is a major advantage over binary or source auditing, or even fuzzing's close cousin, fault injection, which often relies on artificial fault conditions that are difficult or impossible to exploit.
The randomness of inputs used in fuzzing is often seen as a disadvantage, as catching a boundary value condition with random inputs is highly unlikely.
Fuzz testing enhances software security and software safety because it often finds odd oversights and defects which human testers would fail to find, and even careful human test designers would fail to create tests for.
See also
References
- ^ a b c Michael Sutton, Adam Greene, Pedram Amini (2007). Fuzzing: Brute Force Vulnerability Discovery. Addison-Wesley. ISBN 0321446119.
- ^ John Neystadt (2008-02). "Automated Penetration Testing with White-Box Fuzzing". Microsoft. http://msdn.microsoft.com/en-us/library/cc162782.aspx. Retrieved 2009-05-14.
- ^ Barton Miller (2008). "Preface". In Ari Takanen, Jared DeMott and Charlie Miller, Fuzzing for Software Security Testing and Quality Assurance, ISBN 978-1-59693-214-2
- ^ "Fuzz Testing of Application Reliability". University of Wisconsin-Madison. http://pages.cs.wisc.edu/~bart/fuzz/. Retrieved 2009-05-14.
- ^ "Macintosh Stories: Monkey Lives". Folklore.org. 1999-02-22. http://www.folklore.org/StoryView.py?story=Monkey_Lives.txt. Retrieved 2010-05-28.
- ^ Justin E. Forrester and Barton P. Miller. "An Empirical Study of the Robustness of Windows NT Applications Using Random Testing". http://pages.cs.wisc.edu/~bart/fuzz/fuzz-nt.html.
- ^ Jesse Ruderman. "Fuzzing for correctness". http://www.squarefree.com/2007/08/02/fuzzing-for-correctness/.
- ^ Jesse Ruderman. "Fuzzing TraceMonkey". http://www.squarefree.com/2008/12/23/fuzzing-tracemonkey/.
- ^ Jesse Ruderman. "Some differences between JavaScript engines". http://www.squarefree.com/2008/12/23/differences/.
- ^ "Robustness Testing Of Industrial Control Systems With Achilles" (PDF). http://wurldtech.com/resources/SB_002_Robustness_Testing_With_Achilles.pdf. Retrieved 2010-05-28.
- ^ "Software Testing Techniques by Boris Beizer. International Thomson Computer Press; 2 Sub edition (June 1990)". Amazon.com. http://www.amazon.com/dp/1850328803. Retrieved 2010-05-28.
- ^ "Kaksonen, Rauli. (2001) A Functional Method for Assessing Protocol Implementation Security (Licentiate thesis). Espoo. Technical Research Centre of Finland, VTT Publications 447. 128 p. + app. 15 p. ISBN 951-38-5873-1 (soft back ed.) ISBN 951-38-5874-X (on-line ed.)." (PDF). http://www.vtt.fi/inf/pdf/publications/2001/P448.pdf. Retrieved 2010-05-28.
- ^ "Software Fault Injection: Inoculating Programs Against Errors by Jeffrey M. Voas and Gary McGraw". John Wiley & Sons. January 28, 1998. http://www.amazon.com/dp/0471183814.
- ^ Dan Kaminski (2006). "Black Ops 2006". http://usenix.org/events/lisa06/tech/slides/kaminsky.pdf.
- ^ Patrice Godefroid, Adam Kiezun, Michael Y. Levin. "Grammar-based Whitebox Fuzzing". Microsoft Research. http://people.csail.mit.edu/akiezun/pldi-kiezun.pdf.
- ^ "VDA Labs". http://www.vdalabs.com/tools/efs_gpf.html.
- ^ "Test Case Reduction". 2011-07-18. http://www.webkit.org/quality/reduction.html.
- ^ "IBM Test Case Reduction Techniques". 2011-07-18. https://www-304.ibm.com/support/docview.wss?uid=swg21084174.
Further reading
- ISBN 978-1-59693-214-2, Fuzzing for Software Security Testing and Quality Assurance, Ari Takanen, Jared D. DeMott, Charles Miller
External links
- University of Wisconsin Fuzz Testing (the original fuzz project) Source of papers and fuzz software.
- Look out! It's the Fuzz! (IATAC IAnewsletter 10-1)
- Designing Inputs That Make Software Fail, conference video including fuzzy testing
- Link to the Oulu (Finland) University Secure Programming Group
- JBroFuzz - Building A Java Fuzzer, conference presentation video
- Building 'Protocol Aware' Fuzzing Frameworks