Factorial experiment
In statistics, a full factorial experiment is an experiment whose design consists of two or more factors, each with discrete possible values or "levels", and whose experimental units take on all possible combinations of these levels across all such factors. A full factorial design may also be called a fully crossed design. Such an experiment allows studying the effect of each factor on the response variable, as well as the effects of interactions between factors on the response variable.
For the vast majority of factorial experiments, each factor has only two levels. For example, with two factors each taking two levels, a factorial experiment would have four treatment combinations in total, and is usually called a 2×2 factorial design.
If the number of combinations in a full factorial design is too high to be logistically feasible, a fractional factorial design may be done, in which some of the possible combinations (usually at least half) are omitted.
Contents |
History
Factorial designs were used in the 19th century by John Bennet Lawes and Joseph Henry Gilbert of the Rothamsted Experimental Station.[1]
Ronald Fisher argued in 1926 that "complex" designs (such as factorial designs) were more efficient than studying one factor at a time.[2]
Fisher wrote,
"No aphorism is more frequently repeated in connection with field trials, than that we must ask Nature few questions, or, ideally, one question, at a time. The writer is convinced that this view is wholly mistaken."
Nature, he suggests, will best respond to a logical and carefully thought out questionnaire". A factorial design allows the effect of several factors and even interactions between them to be determined with the same number of trials as are necessary to determine any one of the effects by itself with the same degree of accuracy.
Frank Yates made significant contributions, particularly in the analysis of designs, by the Yates analysis.
The term "factorial" may not have been used in print before 1935, when Fisher used it in his book The Design of Experiments. [1]
Example
The simplest factorial experiment contains two levels for each of two factors. Suppose an engineer wishes to study the total power used by each of two different motors, A and B, running at each of two different speeds, 2000 or 3000 RPM. The factorial experiment would consist of four experimental units: motor A at 2000 RPM, motor B at 2000 RPM, motor A at 3000 RPM, and motor B at 3000 RPM. Each combination of a single level selected from every factor is present once.
This experiment is an example of a 22 (or 2x2) factorial experiment, so named because it considers two levels (the base) for each of two factors (the power or superscript), or #levels#factors, producing 22=4 factorial points.
Designs can involve many independent variables. As a further example, the effects of three input variables can be evaluated in eight experimental conditions shown as the corners of a cube.
This can be conducted with or without replication, depending on its intended purpose and available resources. It will provide the effects of the three independent variables on the dependent variable and possible interactions.
Notation
| A | B | |
|---|---|---|
| (1) | − | − |
| a | + | − |
| b | − | + |
| ab | + | + |
To save space, the points in a two-level factorial experiment are often abbreviated with strings of plus and minus signs. The strings have as many symbols as factors, and their values dictate the level of each factor: conventionally, 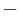 for the first (or low) level, and
for the first (or low) level, and 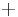 for the second (or high) level. The points in this experiment can thus be represented as
for the second (or high) level. The points in this experiment can thus be represented as 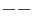 ,
,  ,
, 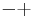 , and
, and 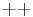 .
.
The factorial points can also be abbreviated by (1), a, b, and ab, where the presence of a letter indicates that the specified factor is at its high (or second) level and the absence of a letter indicates that the specified factor is at its low (or first) level (for example, "a" indicates that factor A is on its high setting, while all other factors are at their low (or first) setting). (1) is used to indicate that all factors are at their lowest (or first) values.
Implementation
For more than two factors, a 2k factorial experiment can be usually recursively designed from a 2k-1 factorial experiment by replicating the 2k-1 experiment, assigning the first replicate to the first (or low) level of the new factor, and the second replicate to the second (or high) level. This framework can be generalized to, e.g., designing three replicates for three level factors, etc.
A factorial experiment allows for estimation of experimental error in two ways. The experiment can be replicated, or the sparsity-of-effects principle can often be exploited. Replication is more common for small experiments and is a very reliable way of assessing experimental error. When the number of factors is large (typically more than about 5 factors, but this does vary by application), replication of the design can become operationally difficult. In these cases, it is common to only run a single replicate of the design, and to assume that factor interactions of more than a certain order (say, between three or more factors) are negligible. Under this assumption, estimates of such high order interactions are estimates of an exact zero, thus really an estimate of experimental error.
When there are many factors, many experimental runs will be necessary, even without replication. For example, experimenting with 10 factors at two levels each produces 210=1024 combinations. At some point this becomes infeasible due to high cost or insufficient resources. In this case, fractional factorial designs may be used.
As with any statistical experiment, the experimental runs in a factorial experiment should be randomized to reduce the impact that bias could have on the experimental results. In practice, this can be a large operational challenge.
Factorial experiments can be used when there are more than two levels of each factor. However, the number of experimental runs required for three-level (or more) factorial designs will be considerably greater than for their two-level counterparts. Factorial designs are therefore less attractive if a researcher wishes to consider more than two levels.
Analysis
A factorial experiment can be analyzed using ANOVA or regression analysis . It is relatively easy to estimate the main effect for a factor. To compute the main effect of a factor "A", subtract the average response of all experimental runs for which A was at its low (or first) level from the average response of all experimental runs for which A was at its high (or second) level.
Other useful exploratory analysis tools for factorial experiments include main effects plots, interaction plots, and a normal probability plot of the estimated effects.
When the factors are continuous, two-level factorial designs assume that the effects are linear. If a quadratic effect is expected for a factor, a more complicated experiment should be used, such as a central composite design. Optimization of factors that could have quadratic effects is the primary goal of response surface methodology.
See also
Notes
- ^ Frank Yates and Kenneth Mather (1963). "Ronald Aylmer Fisher". Biographical Memoirs of Fellows of the Royal Society of London 9: 91–120. http://digital.library.adelaide.edu.au/coll/special//fisher/fisherbiog.pdf.
- ^ Ronald Fisher (1926). "The Arrangement of Field Experiments". Journal of the Ministry of Agriculture of Great Britain 33: 503–513. http://digital.library.adelaide.edu.au/coll/special//fisher/48.pdf.
References
- Box, G.E., Hunter,W.G., Hunter, J.S., Statistics for Experimenters: Design, Innovation, and Discovery, 2nd Edition, Wiley, 2005, ISBN 0471718130
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||