Conditional expectation
In probability theory, a conditional expectation (also known as conditional expected value or conditional mean) is the expected value of a real random variable with respect to a conditional probability distribution.
The concept of conditional expectation is extremely important in Kolmogorov's measure-theoretic definition of probability theory. In fact, the concept of conditional probability itself is actually defined in terms of conditional expectation.
Contents |
Introduction
Let X and Y be discrete random variables, then the conditional expectation of X given the event Y=y is a function of y over the range of Y
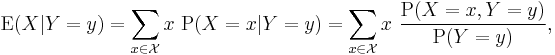
where 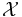 is the range of X.
is the range of X.
A problem arises when we attempt to extend this to the case where Y is a continuous random variable. In this case, the probability P(Y=y) = 0, and the Borel–Kolmogorov paradox demonstrates the ambiguity of attempting to define conditional probability along these lines.
However the above expression may be rearranged:
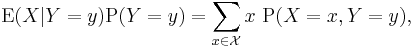
and although this is trivial for individual values of y (since both sides are zero), it should hold for any measurable subset B of the domain of Y that:
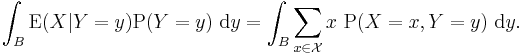
In fact, this is a sufficient condition to define both conditional expectation, and conditional probability.
Formal definition
Let 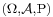 be a probability space, with a real random variable X and a sub-σ-algebra
be a probability space, with a real random variable X and a sub-σ-algebra 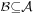 . Then a conditional expectation of X given
. Then a conditional expectation of X given 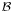 is any -measurable function
is any -measurable function 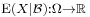 which satisfies:
which satisfies:
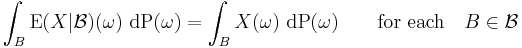 .[1]
.[1]
Note that 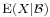 is simply the name of the conditional expectation function.
is simply the name of the conditional expectation function.
Discussion
A couple of points worth noting about the definition:
- This is not a constructive definition; we are merely given the required property that a conditional expectation must satisfy.
- The required property has the same form as the last expression in the Introduction section.
- Existence of a conditional expectation function is determined by the Radon–Nikodym theorem, a sufficient condition is that the (unconditional) expected value for X exist.
- Uniqueness can be shown to be almost sure: that is, versions of the same conditional expectation will only differ on a set of probability zero.
- The σ-algebra controls the "granularity" of the conditioning. A conditional expectation
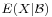 over a finer-grained σ-algebra will allow us to condition on a wider variety of events.
over a finer-grained σ-algebra will allow us to condition on a wider variety of events.
- To condition freely on values of a random variable Y with state space
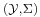 , it suffices to define the conditional expectation using the pre-image of Σ with respect to Y:
, it suffices to define the conditional expectation using the pre-image of Σ with respect to Y:
- To condition freely on values of a random variable Y with state space
-
-
- This suffices to ensure that the conditional expectation is σ(Y)-measurable. Although conditional expectation is defined to condition on events in the underlying probability space Ω, the requirement that it be σ(Y)-measurable allows us to condition on
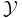 as in the introduction.
as in the introduction.
-
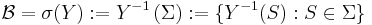
Definition of conditional probability
For any event 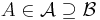 , define the indicator function:
, define the indicator function:
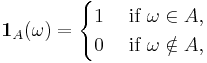
which is a random variable with respect to the Borel σ-algebra on (0,1). Note that the expectation of this random variable is equal to the probability of A itself:

Then the conditional probability given is a function 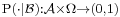 such that
such that 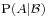 is the conditional expectation of the indicator function for A:
is the conditional expectation of the indicator function for A:
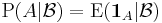
In other words, is a -measurable function satisfying
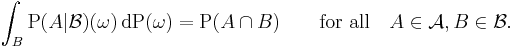
A conditional probability is regular if 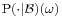 is also a probability measure for all ω ∈ Ω. An expectation of a random variable with respect to a regular conditional probability is equal to its conditional expectation.
is also a probability measure for all ω ∈ Ω. An expectation of a random variable with respect to a regular conditional probability is equal to its conditional expectation.
- For the trivial sigma algebra
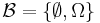 the conditional probability is a constant function,
the conditional probability is a constant function, 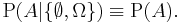
- For
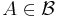 , as outlined above,
, as outlined above, 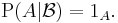 .
.
Conditioning as factorization
In the definition of conditional expectation that we provided above, the fact that Y is a real random variable is irrelevant: Let U be a measurable space, that is, a set equipped with a σ-algebra 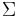 of subsets. A U-valued random variable is a function
of subsets. A U-valued random variable is a function 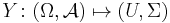 such that
such that 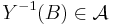 for any measurable subset
for any measurable subset 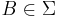 of U.
of U.
We consider the measure Q on U given as above: Q(B) = P(Y−1(B)) for every measurable subset B of U. Then Q is a probability measure on the measurable space U defined on its σ-algebra of measurable sets.
Theorem. If X is an integrable random variable on Ω then there is one and, up to equivalence a.e. relative to Q, only one integrable function g on U (which is written 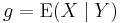 ) such that for any measurable subset B of U:
) such that for any measurable subset B of U:
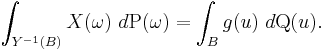
There are a number of ways of proving this; one as suggested above, is to note that the expression on the left hand side defines, as a function of the set B, a countably additive signed measure μ on the measurable subsets of U. Moreover, this measure μ is absolutely continuous relative to Q. Indeed Q(B) = 0 means exactly that Y−1(B) has probability 0. The integral of an integrable function on a set of probability 0 is itself 0. This proves absolute continuity. Then the Radon–Nikodym theorem provides the function g, equal to the density of μ with respect to Q.
The defining condition of conditional expectation then is the equation
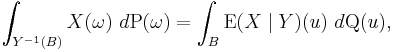
and it holds that
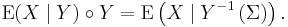
We can further interpret this equality by considering the abstract change of variables formula to transport the integral on the right hand side to an integral over Ω:
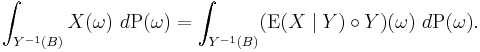
This equation can be interpreted to say that the following diagram is commutative in the average.
E(X|Y)= goY
Ω ───────────────────────────> R
Y g=E(X|Y= ·)
Ω ──────────> R ───────────> R
ω ──────────> Y(ω) ───────────> g(Y(ω)) = E(X|Y=Y(ω))
y ───────────> g( y ) = E(X|Y= y )
The equation means that the integrals of X and the composition 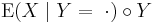 over sets of the form Y−1(B), for B a measurable subset of U, are identical.
over sets of the form Y−1(B), for B a measurable subset of U, are identical.
Conditioning relative to a subalgebra
There is another viewpoint for conditioning involving σ-subalgebras N of the σ-algebra M. This version is a trivial specialization of the preceding: we simply take U to be the space Ω with the σ-algebra N and Y the identity map. We state the result:
Theorem. If X is an integrable real random variable on Ω then there is one and, up to equivalence a.e. relative to P, only one integrable function g such that for any set B belonging to the subalgebra N
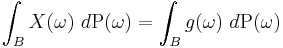
where g is measurable with respect to N (a stricter condition than the measurability with respect to M required of X). This form of conditional expectation is usually written: E(X|N). This version is preferred by probabilists. One reason is that on the space of square-integrable real random variables (in other words, real random variables with finite second moment) the mapping X → E(X|N) is self-adjoint
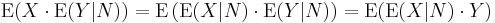
and an orthogonal projection
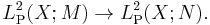
Basic properties
Let (Ω, M, P) be a probability space, and let N be a σ-subalgebra of M.
- Conditioning with respect to N is linear on the space of integrable real random variables.
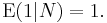 More generally,
More generally, 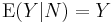 for every integrable N–measurable random variable Y on Ω.
for every integrable N–measurable random variable Y on Ω.
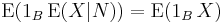 for all B ∈ N and every integrable random variable X on Ω.
for all B ∈ N and every integrable random variable X on Ω.
- Jensen's inequality holds: If ƒ is a convex function, then
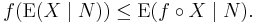
- Conditioning is a contractive projection
-
- for any s ≥ 1.
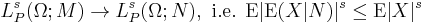
See also
- Law of total probability
- Law of total expectation
- Law of total variance
- Law of total cumulance (generalizes the other three)
- Conditioning (probability)
- Joint probability distribution
- Disintegration theorem
Notes
- ^ Loève (1978), p. 7
References
- Kolmogorov, Andrey (1933) (in German). Grundbegriffe der Wahrscheinlichkeitsrechnung. Berlin: Julius Springer.
- Translation: Kolmogorov, Andrey (1956). Foundations of the Theory of Probability (2nd ed.). New York: Chelsea. ISBN 0828400237. http://www.mathematik.com/Kolmogorov/index.html.
- Loève, Michel (1978). "Chapter 27. Concept of Conditioning". Probability Theory vol. II (4th ed.). Springer. ISBN 0387902627.
- William Feller, An Introduction to Probability Theory and its Applications, vol 1, 1950
- Paul A. Meyer, Probability and Potentials, Blaisdell Publishing Co., 1966
- Grimmett, Geoffrey; Stirzaker, David (2001). Probability and Random Processes (3rd ed.). Oxford University Press. ISBN 0198572220.
External links
- Ushakov, N.G. (2001), "Conditional mathematical expectation", in Hazewinkel, Michiel, Encyclopedia of Mathematics, Springer, ISBN 978-1556080104, http://www.encyclopediaofmath.org/index.php?title=c/c024500