BFGS method
In numerical optimization, the Broyden–Fletcher–Goldfarb–Shanno (BFGS) method is a method for solving nonlinear optimization problems (which lack constraints).
The BFGS method approximates Newton's method, a class of hill-climbing optimization techniques that seeks a stationary point of a (preferably twice continuously differentiable) function: For such problems, a necessary condition for optimality is that the gradient be zero. Newton's method and the BFGS methods need not converge unless the function has a quadratic Taylor expansion near an optimum. These methods use the first and second derivatives. However, BFGS has proven good performance even for non-smooth optimizations.
In quasi-Newton methods, the Hessian matrix of second derivatives need not be evaluated directly. Instead, the Hessian matrix is approximated using rank-one updates specified by gradient evaluations (or approximate gradient evaluations). Quasi-Newton methods are a generalization of the secant method to find the root of the first derivative for multidimensional problems. In multi-dimensions the secant equation does not specify a unique solution, and quasi-Newton methods differ in how they constrain the solution. The BFGS method is one of the most popular members of this class.[1] Also in common use is L-BFGS, which is a limited-memory version of BFGS that is particularly suited to problems with very large numbers of variables (like >1000). The BFGS-B[2] variant handles simple box constraints.
Contents |
Rationale
The search direction pk at stage k is given by the solution of the analogue of the Newton equation
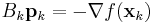
where 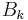 is an approximation to the Hessian matrix which is updated iteratively at each stage, and
is an approximation to the Hessian matrix which is updated iteratively at each stage, and 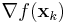 is the gradient of the function evaluated at xk. A line search in the direction pk is then used to find the next point xk+1. Instead of requiring the full Hessian matrix at the point xk+1 to be computed as Bk+1, the approximate Hessian at stage k is updated by the addition of two matrices.
is the gradient of the function evaluated at xk. A line search in the direction pk is then used to find the next point xk+1. Instead of requiring the full Hessian matrix at the point xk+1 to be computed as Bk+1, the approximate Hessian at stage k is updated by the addition of two matrices.
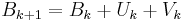
Both Uk and Vk are symmetric rank-one matrices but have different (matrix) bases. The symmetric rank one assumption here means that we may write
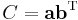
So equivalently, Uk and Vk construct a rank-two update matrix which is robust against the scale problem often suffered in the gradient descent searching (e.g., in Broyden's method).
The quasi-Newton condition imposed on this update is
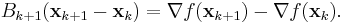
Algorithm
From an initial guess  and an approximate Hessian matrix
and an approximate Hessian matrix 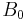 the following steps are repeated until
the following steps are repeated until  converges to the solution.
converges to the solution.
- Obtain a direction
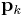 by solving:
by solving: 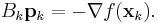
- Perform a line search to find an acceptable stepsize
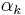 in the direction found in the first step, then update
in the direction found in the first step, then update 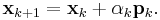
- Set
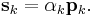
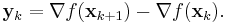
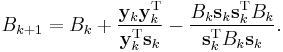
 denotes the objective function to be minimized. Convergence can be checked by observing the norm of the gradient,
denotes the objective function to be minimized. Convergence can be checked by observing the norm of the gradient, 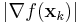 . Practically, can be initialized with
. Practically, can be initialized with 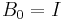 , so that the first step will be equivalent to a gradient descent, but further steps are more and more refined by
, so that the first step will be equivalent to a gradient descent, but further steps are more and more refined by 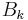 , the approximation to the Hessian.
, the approximation to the Hessian.
The first step of the algorithm is carried out using the inverse of the matrix , which is usually obtained efficiently by applying the Sherman–Morrison formula to the fifth line of the algorithm, giving
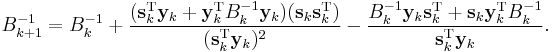
In statistical estimation problems (such as maximum likelihood or Bayesian inference), credible intervals or confidence intervals for the solution can be estimated from the inverse of the final Hessian matrix. However, these quantities are technically defined by the true Hessian matrix, and the BFGS approximation may not converge to the true Hessian matrix.
Implementations
In the Matlab Optimization Toolbox, the fminunc function uses BFGS with cubic line search when the problem size is set to "medium scale." The GSL implements BFGS as gsl_multimin_fdfminimizer_vector_bfgs2. In SciPy, the scipy.optimize.fmin_bfgs function implements BFGS. It is also possible to run BFGS using any of the L-BFGS algorithms by setting the parameter L to a very large number.
See also
Notes
- ^ Nocedal & Wright (2006), page 24
- ^ R. H. Byrd, P. Lu and J. Nocedal. A Limited Memory Algorithm for Bound Constrained Optimization (1995), SIAM Journal on Scientific and Statistical Computing, 16, 5, pp. 1190–1208.
Bibliography
- Avriel, Mordecai (2003), Nonlinear Programming: Analysis and Methods, Dover Publishing, ISBN 0-486-43227-0
- Bonnans, J. Frédéric; Gilbert, J. Charles; Lemaréchal, Claude; Sagastizábal, Claudia A. (2006), Numerical optimization: Theoretical and practical aspects, Universitext (Second revised ed. of translation of 1997 French ed.), Berlin: Springer-Verlag, pp. xiv+490, doi:10.1007/978-3-540-35447-5, ISBN 3-540-35445-X, MR2265882, http://www.springer.com/mathematics/applications/book/978-3-540-35445-1
- Broyden, C. G. (1970), "The convergence of a class of double-rank minimization algorithms", Journal of the Institute of Mathematics and Its Applications 6: 76–90, doi:10.1093/imamat/6.1.76
- Fletcher, R. (1970), "A New Approach to Variable Metric Algorithms", Computer Journal 13 (3): 317–322, doi:10.1093/comjnl/13.3.317
- Fletcher, Roger (1987), Practical methods of optimization (2nd ed.), New York: John Wiley & Sons, ISBN 978-0-471-91547-8.
- Goldfarb, D. (1970), "A Family of Variable Metric Updates Derived by Variational Means", Mathematics of Computation 24 (109): 23–26, doi:10.1090/S0025-5718-1970-0258249-6
- Luenberger, David G.; Ye, Yinyu (2008), Linear and nonlinear programming, International Series in Operations Research & Management Science, 116 (Third ed.), New York: Springer, pp. xiv+546, ISBN 978-0-387-74502-2 MR2423726
- Nocedal, Jorge; Wright, Stephen J. (2006), Numerical Optimization (2nd ed.), Berlin, New York: Springer-Verlag, ISBN 978-0-387-30303-1
- Shanno, David F. (July 1970), "Conditioning of quasi-Newton methods for function minimization", Math. Comput. 24: 647–656, MR42:8905
- Shanno, David F.; Kettler, Paul C. (July 1970), "Optimal conditioning of quasi-Newton methods", Math. Comput. 24: 657–664, MR42:8906
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||