Belief revision
Belief revision is the process of changing beliefs to take into account a new piece of information. The logical formalization of belief revision is researched in philosophy, in databases, and in artificial intelligence for the design of rational agents.
What makes belief revision non-trivial is that several different ways for performing this operation may be possible. For example, if the current knowledge includes the three facts " is true", "
is true", "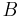 is true" and "if and are true then
is true" and "if and are true then 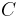 is true", the introduction of the new information " is false" can be done preserving consistency only by removing at least one of the three facts. In this case, there are at least three different ways for performing revision. In general, there may be several different ways for changing knowledge.
is true", the introduction of the new information " is false" can be done preserving consistency only by removing at least one of the three facts. In this case, there are at least three different ways for performing revision. In general, there may be several different ways for changing knowledge.
Revision and update
Two kinds of changes are usually distinguished:
- update
- the new information is about the situation at present, while the old beliefs refer to the past; update is the operation of changing the old beliefs to take into account the change;
- revision
- both the old beliefs and the new information refer to the same situation; an inconsistency between the new and old information is explained by the possibility of old information being less reliable than the new one; revision is the process of inserting the new information into the set of old beliefs without generating an inconsistency.
The main assumption of belief revision is that of minimal change: the knowledge before and after the change should be as similar as possible. In the case of update, this principle formalizes the assumption of inertia. In the case of revision, this principle enforces as much information as possible to be preserved by the change.
Example
The following classical example shows that the operations to perform in the two settings of update and revision are not the same. The example is based on two different interpretations of the set of beliefs 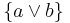 and the new piece of information
and the new piece of information 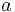 :
:
- update
- in this scenario, two satellites, Unit A and Unit B, orbit around Mars; the satellites are programmed to land while transmitting their status to Earth; Earth has received a transmission from one of the satellites, communicating that it is still in orbit; however, due to interference, it is not known which satellite sent the signal; subsequently, Earth receives the communication that Unit A has landed; this scenario can be modeled in the following way; two propositional variables and
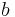 indicate that Unit A and Unit B, respectively, are still in orbit; the initial set of beliefs is (either one of the two satellites is still in orbit) and the new piece of information is
indicate that Unit A and Unit B, respectively, are still in orbit; the initial set of beliefs is (either one of the two satellites is still in orbit) and the new piece of information is 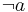 (Unit A has landed, and is therefore not in orbit); the only rational result of the update is ; since the initial information that one of the two satellites had not landed yet was possibly coming from the Unit A, the position of the Unit B is not known;
(Unit A has landed, and is therefore not in orbit); the only rational result of the update is ; since the initial information that one of the two satellites had not landed yet was possibly coming from the Unit A, the position of the Unit B is not known;
- revision
- the play "Six Characters in Search of an Author" will be performed in one of the two local theatres; this information can be denoted by , where and indicates that the play will be performed at the first or at the second theatre, respectively; a further information that "Jesus Christ Superstar" will be performed at the first theatre indicates that holds; in this case, the obvious conclusion is that "Six Characters in Search of an Author" will be performed at the second but not the first theatre, which is represented in logic by
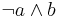 .
.
This example shows that revising the belief 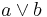 with the new information produces two different results and depending on whether the setting is that of update or revision.
with the new information produces two different results and depending on whether the setting is that of update or revision.
Contraction, expansion, revision, consolidation, and merging
In the setting in which all beliefs refer to the same situation, a distinction between various operations that can be performed is made:
- contraction
- removal of a belief;
- expansion
- addition of a belief without checking consistency;
- revision
- addition of a belief while maintaining consistency;
- consolidation
- restoring consistency of a set of beliefs;
- merging
- fusion of two or more sets of beliefs while maintaining consistency.
Revision and merging differ in that the first operation is done when the new belief to incorporate is considered more reliable than the old ones; therefore, consistency is maintained by removing some of the old beliefs. Merging is a more general operation, in that the priority among the belief sets may or may not be the same.
Revision can be performed by first incorporating the new fact and then restoring consistency via consolidation. This is actually a form of merging rather than revision, as the new information is not always treated as more reliable than the old knowledge.
The AGM postulates
The AGM postulates (named after the names of their proponents, Alchourrón, Gärdenfors, and Makinson) are properties that an operator that performs revision should satisfy in order for being considered rational. The considered setting is that of revision, that is, different pieces of information referring to the same situation. Three operations are considered: expansion (addition of a belief without a consistency check), revision (addition of a belief while maintaining consistency), and contraction (removal of a belief).
The first six postulates are called "the basic AGM postulates". In the settings considered by Alchourrón, Gärdenfors, and Makinson, the current set of beliefs is represented by a deductively closed set of logical formulae 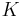 called belief base, the new piece of information is a logical formula
called belief base, the new piece of information is a logical formula 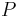 , and revision is performed by a binary operator
, and revision is performed by a binary operator  that takes as its operands the current beliefs and the new information and produces as a result a belief base representing the result of the revision. The
that takes as its operands the current beliefs and the new information and produces as a result a belief base representing the result of the revision. The 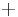 operator denoted expansion:
operator denoted expansion: 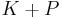 is the deductive closure of
is the deductive closure of 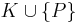 . The AGM postulates for revision are:
. The AGM postulates for revision are:
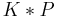 is a belief base (i.e., a deductively closed set of formulae);
is a belief base (i.e., a deductively closed set of formulae);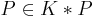
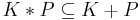
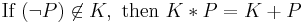
- is inconsistent only if is inconsistent or is inconsistent
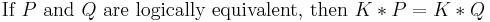 (see logical equivalence)
(see logical equivalence)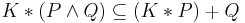
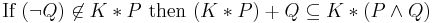
A revision operator that satisfies all eight postulates is the full meet revision, in which is equal to if consistent, and to the deductive closure of otherwise. While satisfying all AGM postulates, this revision operator has been considered to be too conservative, in that no information from the old knowledge base is maintained if the revising formula is inconsistent with it.
Conditions equivalent to the AGM postulates
The AGM postulates are equivalent to several different conditions on the revision operator; in particular, they are equivalent to the revision operator being definable in terms of structures known as selection functions, epistemic entrenchments, systems of spheres, and preference relations. The latter are reflexive, transitive, and total relations over the set of models.
Each revision operator satisfying the AGM postulates is associated to a set of preference relations 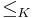 , one for each possible belief base , such that the models of are exactly the minimal of all models according to . The revision operator and its associated family of orderings are related by the fact that is the set of formulae whose set of models contains all the minimal models of according to . This condition is equivalent to the set of models of being exactly the set of the minimal models of according to the ordering .
, one for each possible belief base , such that the models of are exactly the minimal of all models according to . The revision operator and its associated family of orderings are related by the fact that is the set of formulae whose set of models contains all the minimal models of according to . This condition is equivalent to the set of models of being exactly the set of the minimal models of according to the ordering .
A preference ordering represents an order of unplausibility among all situations, including those that are conceivable but yet currently considered false. The minimal models according to such an ordering are exactly the models of the knowledge base, which are the models that are currently considered the most likely. All other models are greater than these ones, and are indeed considered less plausible. In general, 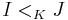 indicates that the situation represented by the model
indicates that the situation represented by the model 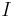 is believed to be more plausible than the situation represented by
is believed to be more plausible than the situation represented by 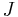 . As a result, revising by a formula having and as models should select only to be a model of the revised knowledge base, as this model represent the most likely scenario among those supported by .
. As a result, revising by a formula having and as models should select only to be a model of the revised knowledge base, as this model represent the most likely scenario among those supported by .
Contraction
Contraction is the operation of removing a belief from a knowledge base ; the result of this operation is denoted by 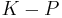 . The operators of revision and contractions are related by the Levi and Harper identities:
. The operators of revision and contractions are related by the Levi and Harper identities:
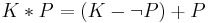
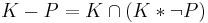
Eight postulates have been defined for contraction. Whenever a revision operator satisfies the eight postulates for revision, its corresponding contraction operator satisfies the eight postulates for contraction, and vice versa. If a contraction operator satisfies at least the first six postulates for contraction, translating it into a revision operator and then back into a contraction operator using the two identities above leads to the original contraction operator. The same holds starting from a revision operator.
One of the postulates for contraction has been longly discussed: the recovery postulate:
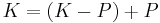
According to this postulate, the removal of a belief followed by the reintroduction of the same belief in the belief base should lead to the original belief base. There are some examples showing that such behavior is not always reasonable: in particular, the contraction by a general condition such as leads to the removal of more specific conditions such as from the belief base; it is then unclear why the reintroduction of should also lead to the reintroduction of the more specific condition . For example, if George was previously believed to have German citizenship, it was also believed to be European. Contracting this latter belief amounts to stop believing that George is European; therefore, that George has German citizenship is also retracted from the belief base. If George is later discovered to have Austrian citizenship, then the fact that he is European is also reintroduced. According to the recovery postulate, however, the belief that he also has German citizenship should also be reintroduced.
The correspondence between revision and contraction induced by the Levi and Harper identities is such that a contraction not satisfying the recovery postulate is translated into a revision satisfying all eight postulates, and that a revision satisfying all eight postulates is translated into a contraction satisfying all eight postulates, including recovery. As a result, if recovery is excluded from consideration, a number of contraction operators are translated into a single revision operator, which can be then translated back into exactly one contraction operator. This operator is the only one of the initial group of contraction operators that satisfies recovery; among this group, it is the operator that preserves as much information as possible.
The Ramsey test
The evaluation of a counterfactual conditional 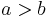 can be done, according to the Ramsey test, to the hypothetical addition of to the set of current beliefs followed by a check for the truth of . If is the set of beliefs currently held, the Ramsey test is formalized by the following correspondence:
can be done, according to the Ramsey test, to the hypothetical addition of to the set of current beliefs followed by a check for the truth of . If is the set of beliefs currently held, the Ramsey test is formalized by the following correspondence:
- if and only if
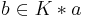
If the considered language of the formulae representing beliefs is propositional, the Ramsey test gives a consistent definition for counterfactual conditionals in terms of a belief revision operator. However, if the language of formulae representing beliefs itself includes the counterfactual conditional connective 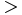 , the Ramsey test leads to the Gardnefors triviality result: there is no non-trivial revision operator that satisfies both the AGM postulates for revision and the condition of the Ramsey test. This result holds in the assumption that counterfactual formulae like can be present in belief bases and revising formulae. Several solutions to this problem have been proposed.
, the Ramsey test leads to the Gardnefors triviality result: there is no non-trivial revision operator that satisfies both the AGM postulates for revision and the condition of the Ramsey test. This result holds in the assumption that counterfactual formulae like can be present in belief bases and revising formulae. Several solutions to this problem have been proposed.
Non-monotonic inference relation
Given a fixed knowledge base and a revision operator , one can define a non-monotonic inference relation using the following definition: 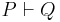 if and only if
if and only if 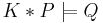 . In other words, a formula entails another formula
. In other words, a formula entails another formula 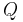 if the addition of the first formula to the current knowledge base leads to the derivation of . This inference relation is non-monotonic.
if the addition of the first formula to the current knowledge base leads to the derivation of . This inference relation is non-monotonic.
The AGM postulates can be translated into a set of postulates for this inference relation. Each of these postulates is entailed by some previously considered set of postulates for non-monotonic inference relations. Vice versa, conditions that have been considered for non-monotonic inference relations can be translated into postulates for a revision operator. All these postulates are entailed by the AGM postulates.
Foundational revision
In the AGM framework, a belief set is represented by a deductively closed set of propositional formulae. While such sets are infinite, they can always be finitely representable. However, working with deductively closed sets of formulae leads to the implicit assumption that equivalent belief bases should be considered equal when revising. This is called the principle of irrelevance of syntax.
This principle has been and is currently debated: while 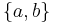 and
and 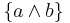 are two equivalent sets, revising by should produce different results. In the first case, and are two separate beliefs; therefore, revising by should not produce any effect on , and the result of revision is
are two equivalent sets, revising by should produce different results. In the first case, and are two separate beliefs; therefore, revising by should not produce any effect on , and the result of revision is 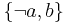 . In the second case,
. In the second case, 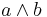 is taken a single belief. The fact that is false contradicts this belief, which should therefore be removed from the belief base. The result of revision is therefore
is taken a single belief. The fact that is false contradicts this belief, which should therefore be removed from the belief base. The result of revision is therefore 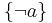 in this case.
in this case.
The problem of using deductively closed knowledge bases is that no distinction is made between pieces of knowledge that are known by themselves and pieces of knowledge that are merely consequences of them. This distinction is instead done by the foundational approach to belief revision, which is related to foundationalism in philosophy. According to this approach, retracting a non-derived piece of knowledge should lead to retracting all its consequences that are not otherwise supported (by other non-derived pieces of knowledge). This approach can be realized by using knowledge bases that are not deductively closed and assuming that all formulae in the knowledge base represent self-standing beliefs, that is, they are not derived beliefs. In order to distinguish the foundational approach to belief revision to that based on deductively closed knowledge bases, the latter is called the coherentist approach. This name has been chosen because the coherentist approach aims at restoring the coherence (consistency) among all beliefs, both self-standing and derived ones. This approach is related to coherentism in philosophy.
Foundationalist revision operators working on non-deductively closed belief bases typically select some subsets of that are consistent with , combined them in some way, and then conjoined them with . The following are two non-deductively closed base revision operators.
- WIDTIO
- (When in Doubt, Throw it Out) the maximal subsets of that are consistent with are intersected, and is added to the resulting set; in other words, the result of revision is composed by and of all formulae of that are in all maximal subsets of that are consistent with ;
- Ginsberg-Fagin-Ullman-Vardi
- the maximal subsets of that are consistent and contain are combined by disjunction;
- Nebel
- similar to the above, but a priority among formulae can be given, so that formulae with higher priority are less likely to being retracted than formulae with lower priority.
A different realization of the foundational approach to belief revision is based on explicitly declaring the dependences among beliefs. In the truth maintenance systems, dependence links among beliefs can be specified. In other worlds, one can explicitly declare that a given fact is believed because of one or more other facts; such a dependency is called a justification. Beliefs not having any justifications play the role of non-derived beliefs in the non-deductively closed knowledge base approach.
Model-based revision and update
A number of proposals for revision and update based on the set of models of the involved formulae were developed independently of the AGM framework. The principle behind this approach is that a knowledge base is equivalent to a set of possible worlds, that is, to a set of scenarios that are considered possible according to that knowledge base. Revision can therefore be performed on the sets of possible worlds rather than on the corresponding knowledge bases.
The revision and update operators based on models are usually identified by the name of their authors: Winslett, Forbus, Satoh, Dalal, Hegner, and Weber. According to the first four of these proposal, the result of revising/updating a formula by another formula is characterized by the set of models of that are the closest to the models of . Different notions of closeness can be defined, leading to the difference among these proposals.
- Dalal
- the models of having a minimal Hamming distance to models of are selected to be the models that result from the change;
- Satoh
- similar to Dalal, but distance between two models is defined as the set of literals that are given different values by them; similarity between models is defined as set containment of these differences;
- Winslett
- for each model of , the closest models of are selected; comparison is done using set containment of the difference;
- Borgida
- equal to Winslett's if and are inconsistent; otherwise, the result of revision is
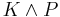 ;
;
- Forbus
- similar to Winslett, but the Hamming distance is used.
The revision operator defined by Hegner makes not to affect the value of the variables that are mentioned in . What results from this operation is a formula 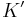 that is consistent with , and can therefore be conjoined with it. The revision operator by Weber is similar, but the literals that are removed from are not all literals of , but only the literals that are evaluated differently by a pair of closest models of and according to the Satoh measure of closeness.
that is consistent with , and can therefore be conjoined with it. The revision operator by Weber is similar, but the literals that are removed from are not all literals of , but only the literals that are evaluated differently by a pair of closest models of and according to the Satoh measure of closeness.
Iterated revision
The AGM postulates are equivalent to a preference ordering (an ordering over models) to be associated to every knowledge base . However, they do not relate the orderings corresponding to two non-equivalent knowledge bases. In particular, the orderings associated to a knowledge base and its revised version can be completely different. This is a problem for performing a second revision, as the ordering associated with is necessary to calculate 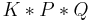 .
.
Establishing a relation between the ordering associated with and has been however recognized not to be the right solution to this problem. Indeed, the preference relation should depend on the previous history of revisions, rather than on the resulting knowledge base only. More generally, a preference relation gives more information about the state of mind of an agent than a simple knowledge base. Indeed, two states of mind might represent the same piece of knowledge while at the same time being different in the way a new piece of knowledge would be incorporated. For example, two people might have the same idea as to where to go on holiday, but yet they differ on how they would change this idea if they win a million-dollar lottery. Since the basic condition of the preference ordering is that their minimal models are exactly the models of their associated knowledge base, a knowledge base can be considered implicitly represented by a preference ordering (but not vice versa).
Given that a preference ordering allows deriving its associated knowledge base but also allows performing a single step of revision, studies on iterated revision have been concentrated on how a preference ordering should be changed in response of a revision. While single-step revision is about how a knowledge base has to be changed into a new knowledge base , iterated revision is about how a preference ordering (representing both the current knowledge and how much situations believed to be false are considered possible) should be turned into a new preference relation when is learned. A single step of iterated revision produces a new ordering that allows for further revisions.
Two kinds of preference ordering are usually considered: numerical and non-numerical. In the first case, the level of plausibility of a model is representing by a non-negative integer number; the lower the rank, the more plausible the situation corresponding to the model. Non-numerical preference orderings correspond to the preference relations used in the AGM framework: a possibly total ordering over models. The non-numerical preference relation were initially considered unsuitable for iterated revision because of the impossibility of reverting a revision by a number of other revisions, which is instead possible in the numerical case.
Darwiche and Pearl[1] formulated the following postulates for iterated revision.
- if
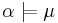 then
then 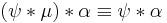 ;
; - if
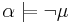 , then ;
, then ; - if
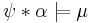 , then
, then 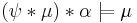 ;
; - if
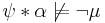 , then
, then 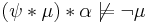 .
.
Specific iterated revision operators have been proposed by Spohn, Boutilier, Williams, Lehmann, and others.
- Spohn rejected revision
- this non-numerical proposal has been first considered by Spohn, who rejected it based on the fact that revisions can change some orderings in such a way the original ordering cannot be restored with a sequence of other revisions; this operator change a preference ordering in view of new information by making all models of being preferred over all other models; the original preference ordering is maintained when comparing two models that are both models of or both non-models of ;
- Natural revision
- while revising a preference ordering by a formula , all minimal models (according to the preference ordering) of are made more preferred by all other ones; the original ordering of models is preserved when comparing two models that are not minimal models of ; this operator changes the ordering among models minimally while preserving the property that the models of the knowledge base after revising by are the minimal models of according to the preference ordering;
- Transmutations
- these are two forms of revision, conditionalization and adjustment, which work on numerical preference orderings; revision requires not only a formula but also a number indicating its degree of plausibility; while the preference ordering is still inverted (the lower a model, the most plausible it is) the degree of plausibility of a revising formula is direct (the higher the degree, the most believed the formula is);
- Ranked revision
- a ranked model, which is an assignment of non-negative integers to models, has to be specified at the beginning; this rank is similar to a preference ordering, but is not changed by revision; what is changed by a sequence of revisions are a current set of models (representing the current knowledge base) and a number called the rank of the sequence; since this number can only monotonically non-decrease, some sequences of revision lead to situations in which every further revision is performed as a full meet revision.
Merging
The assumption implicit in the revision operator is that the new piece of information is always to be considered more reliable than the old knowledge base . This is formalized by the second of the AGM postulates: is always believed after revising with . More generally, one can consider the process of merging several pieces of information (rather than just two) that might or might not have the same reliability. Revision becomes the particular instance of this process when a less reliable piece of information is merged with a more reliable .
While the input to the revision process is a pair of formulae and , the input to merging is a multiset of formulae , 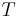 , etc. The use of multisets is necessary as two sources to the merging process might be identical.
, etc. The use of multisets is necessary as two sources to the merging process might be identical.
When merging a number of knowledge bases with the same degree of plausibility, a distinction is made between arbitration and majority. This distinction depends on the assumption that is made about the information and how it has to be put together.
- arbitration
- the result of arbitrating two knowledge bases and entails
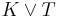 ; this condition formalizes the assumption of maintaining as much as the old information as possible, as it is equivalent to imposing that every formula entailed by both knowledge bases is also entailed by the result of their arbitration; in a possible world view, the "real" world is assumed one of the worlds considered possible according to at least one of the two knowledge bases;
; this condition formalizes the assumption of maintaining as much as the old information as possible, as it is equivalent to imposing that every formula entailed by both knowledge bases is also entailed by the result of their arbitration; in a possible world view, the "real" world is assumed one of the worlds considered possible according to at least one of the two knowledge bases;
- majority
- the result of merging a knowledge base with other knowledge bases can be forced to entail by adding a sufficient number of other knowledge bases equivalent to ; this condition corresponds to a kind of vote-by-majority: a sufficiently large number of knowledge bases can always overcome the "opinion" of any other fixed set of knowledge bases.
The above is the original definition of arbitration. According to a newer definition, an arbitration operator is a merging operator that is insensitive to the number of equivalent knowledge bases to merge. This definition makes arbitration the exact opposite of majority.
Postulates for both arbitration and merging have been proposed. An example of an arbitration operator satisfying all postulates is the classical disjunction. An example of a majority operator satisfying all postulates is that selecting all models that have a minimal total Hamming distance to models of the knowledge bases to merge.
A merging operator can be expressed as a family of orderings over models, one for each possible multiset of knowledge bases to merge: the models of the result of merging a multiset of knowledge bases are the minimal models of the ordering associated to the multiset. A merging operator defined in this way satisfies the postulates for merging if and only if the family of orderings meets a given set of conditions. For the old definition of arbitration, the orderings are not on models but on pairs (or, in general, tuples) of models.
Social choice theory
Many revision proposals involve orderings over models representing the relative plausibility of the possible alternatives. The problem of merging amounts to combine a set of orderings into a single one expressing the combined plausibility of the alternatives. This is similar with what is done in social choice theory, which is the study of how the preferences of a group of agents can be combined in a rational way. Belief revision and social choice theory are similar in that they combine a set of orderings into one. They differ on how these orderings are interpreted: preferences in social choice theory; plausibility in belief revision. Another difference is that the alternatives are explicitly enumerated in social choice theory, while they are the propositional models over a given alphabet in belief revision.
Complexity
The problem about belief revision that is the most studied from the point of view of computational complexity is that of query answering in the propositional case. This is the problem of establishing whether a formula follows from the result of a revision, that is, , where , , and are propositional formulae. More generally, query answering is the problem of telling whether a formula is entailed by the result of a belief revision, which could be update, merging, revision, iterated revision, etc. Another problem that has received some attention is that of model checking, that is, checking whether a model satisfies the result of a belief revision. A related question is whether such result can be represented in space polynomial in that of its arguments.
Since a deductively closed knowledge base is infinite, complexity studies on belief revision operators working on deductively closed knowledge bases are done in the assumption that such deductively closed knowledge base are given in the form of an equivalent finite knowledge base.
A distinction is made among belief revision operators and belief revision schemes. While the former are simple mathematical operators mapping a pair of formulae into another formula, the latter depend on further information such as a preference relation. For example, the Dalal revision is an operator because, once two formulae and are given, no other information is needed to compute . On the other hand, revision based on a preference relation is a revision scheme, because and do not allow determining the result of revision if the family of preference orderings between models is not given. The complexity for revision schemes is determined in the assumption that the extra information needed to compute revision is given in some compact form. For example, a preference relation can be represented by a sequence of formulae whose models are increasingly preferred. Explicitly storing the relation as a set of pairs of models is instead not a compact representation of preference because the space required is exponential in the number of propositional letters.
The complexity of query answering and model checking in the propositional case is in the second level of the polynomial hierarchy for most belief revision operators and schemas. Most revision operators suffer from the problem of representational blow up: the result of revising two formulae is not necessarily representable in space polynomial in that of the two original formulae. In other words, revision may exponentially increase the size of the knowledge base.
Implementations
Systems specifically implementing belief revision are: Immortal, SATEN, and BReLS. Two systems including a belief revision feature are SNePS and Cyc.
See also
- Artificial intelligence
- Inquiry
- Knowledge representation
- Non-monotonic logic
- Defeasible reasoning
- Reasoning
- Philosophy of science
- Discursive dilemma
References
- ^ Darwiche, A. and Pearl, J. (1997) On the logic of iterated belief revision. Artificial Intelligence 89(1-2): 1-29.
- C. E. Alchourròn, P. Gärdenfors, and D. Makinson (1985). On the logic of theory change: Partial meet contraction and revision functions. Journal of Symbolic Logic, 50:510–530.
- C. Boutilier (1993). Revision sequences and nested conditionals. In Proceedings of the Thirteenth International Joint Conference on Artificial Intelligence (IJCAI'93), pages 519–525.
- C. Boutilier (1995). Generalized update: belief change in dynamic settings. In Proceedings of the Fourteenth International Joint Conference on Artificial Intelligence (IJCAI'95), pages 1550–1556.
- C. Boutilier (1996). Abduction to plausible causes: an event-based model of belief update. Artificial Intelligence, 83:143–166.
- M. Cadoli, F. M. Donini, P. Liberatore, and M. Schaerf (1999). The size of a revised knowledge base. Artificial Intelligence, 115(1):25–64.
- T. Chou and M. Winslett (1991). Immortal: A model-based belief revision system. In Proceedings of the Second International Conference on the Principles of Knowledge Representation and Reasoning (KR'91), pages 99–110. Morgan Kaufmann Publishers.
- M. Dalal (1988). Investigations into a theory of knowledge base revision: Preliminary report. In Proceedings of the Seventh National Conference on Artificial Intelligence (AAAI'88), pages 475–479.
- T. Eiter and G. Gottlob (1992). On the complexity of propositional knowledge base revision, updates and counterfactuals. Artificial Intelligence, 57:227–270.
- T. Eiter and G. Gottlob (1996). The complexity of nested counterfactuals and iterated knowledge base revisions. Journal of Computer and System Sciences, 53(3):497–512.
- R. Fagin, J. D. Ullman, and M. Y. Vardi (1983). On the semantics of updates in databases. In Proceedings of the Second ACM SIGACT SIGMOD Symposium on Principles of Database Systems (PODS'83), pages 352–365.
- M. Freund and D. Lehmann (2002). Belief Revision and Rational Inference. Arxiv preprint cs.AI/0204032.
- N. Friedman and J. Y. Halpern (1994). A knowledge-based framework for belief change, part II: Revision and update. In Proceedings of the Fourth International Conference on the Principles of Knowledge Representation and Reasoning (KR'94), pages 190–200.
- A. Fuhrmann (1991). Theory contraction through base contraction. Journal of Philosophical Logic, 20:175–203.
- D. Gabbay, G. Pigozzi, and J. Woods (2003). Controlled Revision – An algorithmic approach for belief revision, Journal of Logic and Computation, 13(1): 15–35.
- P. Gärdenfors and D. Makinson (1988). Revision of knowledge systems using epistemic entrenchment. In Proceedings of the Second Conference on Theoretical Aspects of Reasoning about Knowledge (TARK'88), pages 83–95.
- P. Gärdenfors and H. Rott (1995). Belief revision. In Handbook of Logic in Artificial Intelligence and Logic Programming, Volume 4, pages 35–132. Oxford University Press.
- G. Grahne and Alberto O. Mendelzon (1995). Updates and subjunctive queries. Information and Computation, 2(116):241–252.
- G. Grahne, Alberto O. Mendelzon, and P. Revesz (1992). Knowledge transformations. In Proceedings of the Eleventh ACM SIGACT SIGMOD SIGART Symposium on Principles of Database Systems (PODS'92), pages 246–260.
- S. O. Hansson (1999). A Textbook of Belief Dynamics. Dordrecht: Kluwer Academic Publishers.
- A. Herzig (1996). The PMA revised. In Proceedings of the Fifth International Conference on the Principles of Knowledge Representation and Reasoning (KR'96), pages 40–50.
- A. Herzig (1998). Logics for belief base updating. In D. Dubois, D. Gabbay, H. Prade, and P. Smets, editors, Handbook of defeasible reasoning and uncertainty management, volume 3 – Belief Change, pages 189–231. Kluwer Academic Publishers.
- H. Katsuno and A. O. Mendelzon (1991). On the difference between updating a knowledge base and revising it. In Proceedings of the Second International Conference on the Principles of Knowledge Representation and Reasoning (KR'91), pages 387–394.
- H. Katsuno and A. O. Mendelzon (1991). Propositional knowledge base revision and minimal change. Artificial Intelligence, 52:263–294.
- S. Konieczny and R. Pino Perez (1998). On the logic of merging. In Proceedings of the Sixth International Conference on Principles of Knowledge Representation and Reasoning (KR'98), pages 488–498.
- D. Lehmann (1995). Belief revision, revised. In Proceedings of the Fourteenth International Joint Conference on Artificial Intelligence (IJCAI'95), pages 1534–1540.
- P. Liberatore (1997). The complexity of iterated belief revision. In Proceedings of the Sixth International Conference on Database Theory (ICDT'97), pages 276–290.
- P. Liberatore and M. Schaerf (1998). Arbitration (or how to merge knowledge bases). IEEE Transactions on Knowledge and Data Engineering, 10(1):76–90.
- P. Liberatore and M. Schaerf (2000). BReLS: A system for the integration of knowledge bases. In Proceedings of the Seventh International Conference on Principles of Knowledge Representation and Reasoning (KR 2000), pages 145–152.
- D. Makinson (1985). How to give up: A survey of some formal aspects of the logic of theory change. Synthese, 62:347–363.
- A. Perea (2003). Proper Rationalizability and Belief Revision in Dynamic Games. Research Memoranda 048: METEOR, Maastricht Research School of Economics of Technology and Organization.
- B. Nebel (1991). Belief revision and default reasoning: Syntax-based approaches. In Proceedings of the Second International Conference on the Principles of Knowledge Representation and Reasoning (KR'91), pages 417–428.
- B. Nebel (1994). Base revision operations and schemes: Semantics, representation and complexity. In Proceedings of the Eleventh European Conference on Artificial Intelligence (ECAI'94), pages 341–345.
- B. Nebel (1996). How hard is it to revise a knowledge base? Technical Report 83, Albert-Ludwigs-Universität Freiburg, Institut für Informatik.
- G. Pigozzi (2005). Two aggregation paradoxes in social decision making: the Ostrogorski paradox and the discursive dilemma, Episteme: A Journal of Social Epistemology, 2(2): 33–42.
- G. Pigozzi (2006). Belief merging and the discursive dilemma: an argument-based account to paradoxes of judgment aggregation. Synthese 152(2): 285–298.
- P. Z. Revesz (1993). On the semantics of theory change: Arbitration between old and new information. In Proceedings of the Twelfth ACM SIGACT SIGMOD SIGART Symposium on Principles of Database Systems (PODS'93), pages 71–82.
- K. Satoh (1988). Nonmonotonic reasoning by minimal belief revision. In Proceedings of the International Conference on Fifth Generation Computer Systems (FGCS'88), pages 455–462.
- Shoham, Yoav; Leyton-Brown, Kevin (2009). Multiagent Systems: Algorithmic, Game-Theoretic, and Logical Foundations. New York: Cambridge University Press. ISBN 978-0-521-89943-7. http://www.masfoundations.org. See Section 14.2; downloadable free online.
- V. S. Subrahmanian (1994). Amalgamating knowledge bases. ACM Transactions on Database Systems, 19(2):291–331.
- A. Weber (1986). Updating propositional formulas. In Proc. of First Conf. on Expert Database Systems, pages 487–500.
- M. Williams (1994). Transmutations of knowledge systems. In Proceedings of the Fourth International Conference on the Principles of Knowledge Representation and Reasoning (KR'94), pages 619–629.
- M. Winslett (1989). Sometimes updates are circumscription. In Proceedings of the Eleventh International Joint Conference on Artificial Intelligence (IJCAI'89), pages 859–863.
- M. Winslett (1990). Updating Logical Databases. Cambridge University Press.
- Y. Zhang and N. Foo (1996). Updating knowledge bases with disjunctive information. In Proceedings of the Thirteenth National Conference on Artificial Intelligence (AAAI'96), pages 562–568.
External links
- Beliefrevision.org
- Defeasible Reasoning: 4.3 Belief Revision Theory at Stanford Encyclopedia of Philosophy
- Logic of Belief Revision at Stanford Encyclopedia of Philosophy