Arbitrary-precision arithmetic
In computer science, arbitrary-precision arithmetic indicates that calculations are performed on numbers whose digits of precision are limited only by the available memory of the host system. This contrasts with the faster fixed-precision arithmetic found in most ALU hardware, which typically offers between 16 and 64 bits of precision. Arbitrary-precision arithmetic is also called bignum arithmetic, multiple precision arithmetic, and sometimes "infinite-precision arithmetic".
Several modern programming languages have built-in support for bignums, and others have libraries available for arbitrary-precision integer and floating-point math. Rather than store values as a fixed number of binary bits related to the size of the processor register, these implementations typically use variable-length arrays of digits.
Arbitrary precision is used in applications where the speed of arithmetic is not a limiting factor, or where precise results with very large numbers are required. It should not be confused with the symbolic computation provided by many computer algebra systems, which represent numbers by expressions such as 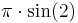 , and can thus represent any computable number with infinite precision.
, and can thus represent any computable number with infinite precision.
Contents |
Applications
A common application is public-key cryptography (such as that in every modern Web browser), whose algorithms commonly employ arithmetic with integers having hundreds or thousands of digits. Another is in situations where artificial limits and overflows would be inappropriate. It is also useful for checking the results of fixed-precision calculations, and for determining the optimum value for coefficients needed in formulae, for example the √⅓ that appears in Gaussian integration.
Arbitrary precision arithmetic is also used to compute fundamental mathematical constants such as π to millions or more digits and to analyze the properties of the digit strings[1] or more generally to investigate the precise behaviour of functions such as the Riemann Zeta function where certain questions are difficult to explore via analytical methods. Another example is in rendering Fractal images with an extremely high magnification, such as those found in the Mandelbrot set.
Arbitrary-precision arithmetic can also be used to avoid overflow, which is an inherent limitation of fixed-precision arithmetic. Similar to a 5-digit odometer's display which changes from 99999 to 00000, a fixed-precision integer may exhibit wraparound if numbers grow too large to represent at the fixed level of precision. Some processors can instead deal with overflow by saturation, which means that if a result would be unrepresentable, it is replaced with the nearest representable value. (With 16-bit unsigned saturation, adding any positive amount to 65535 would yield 65535.) Some processors can generate an exception if an arithmetic result exceeds the available precision. Where necessary, the exception can be caught and recovered from—for instance, the operation could be restarted in software using arbitrary-precision arithmetic.
In many cases, the programmer can guarantee that the integer values in a specific application will not grow large enough to cause an overflow. However, as time passes and conditions change, the bounds of the guarantee can be exceeded. For example, implementations of the Binary search method that employ the form (L + R)/2 may function incorrectly when the sum of L and R exceeds the machine word size, although the individual variables themselves remain valid.
Some programming languages such as Lisp, Python, Perl, Haskell and Ruby use, or have an option to use, arbitrary-precision numbers for all integer arithmetic. Although this reduces performance, it eliminates the possibility of incorrect results (or exceptions) due to simple overflow. It also makes it possible to guarantee that arithmetic results will be the same on all machines, regardless of any particular machine's word size. The exclusive use of arbitrary-precision numbers in a programming language also simplifies the language, because "a number is a number" and there is no need for multiple types to represent different levels of precision.
Implementation issues
Arbitrary-precision arithmetic is considerably slower than arithmetic using numbers that fit entirely within processor registers, since the latter are usually implemented in hardware arithmetic whereas the former must be implemented in software. Even if the computer lacks hardware for certain operations (such as integer division, or all floating-point operations) and software is provided instead, it will use number sizes closely related to the available hardware registers: one or two words only and definitely not N words. There are exceptions, as certain "variable word length" machines of the 1950s and 1960s, notably the IBM 1620, IBM 1401 and the Honeywell "Liberator" series, could manipulate numbers bound only by available storage, with an extra bit that delimited the value.
Numbers can be stored in a fixed-point format, or in a floating-point format as a significand multiplied by an arbitrary exponent. However, since division almost immediately introduces infinitely repeating sequences of digits (such as 4/7 in decimal, or 1/10 in binary), should this possibility arise then either the representation would be truncated at some satisfactory size or else rational numbers would be used: a large integer for the numerator and for the denominator. But even with the greatest common divisor divided out, arithmetic with rational numbers can become unwieldy very swiftly: 1/99 - 1/100 = 1/9900, and if 1/101 is then added the result is 10001/999900.
Bounding the size of arbitrary-precision numbers is not only the total storage available, but the variables used by the software to index the digit strings. These are typically themselves limited in size.
Numerous algorithms have been developed to efficiently perform arithmetic operations on numbers stored with arbitrary precision. In particular, supposing that N digits are employed, algorithms have been designed to minimize the asymptotic complexity for large N.
The simplest algorithms are for addition and subtraction, where one simply adds or subtracts the digits in sequence, carrying as necessary, which yields an O(N) algorithm (see big O notation).
Comparison is also very simple. Compare the high order digits (or machine words) until a difference is found. Comparing the rest of the digits/words is not necessary. The worst case is O(N), but usually it will go much faster.
For multiplication, the most straightforward algorithms used for multiplying numbers by hand (as taught in primary school) require 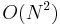 operations, but multiplication algorithms that achieve
operations, but multiplication algorithms that achieve 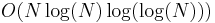 complexity have been devised, such as the Schönhage–Strassen algorithm, based on fast Fourier transforms, and there are also algorithms with slightly worse complexity but with sometimes superior real-world performance for smaller N.
complexity have been devised, such as the Schönhage–Strassen algorithm, based on fast Fourier transforms, and there are also algorithms with slightly worse complexity but with sometimes superior real-world performance for smaller N.
For division, see: Division (digital).
For a list of algorithms along with complexity estimates, see: Computational complexity of mathematical operations
For examples in x86-assembly, see: External links.
Pre-set precision
In some languages such as REXX the precision of all calculations must be set before doing a calculation. Other languages, such as Python and Ruby extend the precision automatically to prevent overflow.
Example
The calculation of factorials can easily produce very large numbers. This is not a problem for their usage in many formulae (such as Taylor series) because they appear along with other terms, so that—given careful attention to the order of evaluation—intermediate calculation values are not troublesome. If approximate values of factorial numbers are desired, Stirling's approximation gives good results using floating-point arithmetic. The largest representable value for a fixed-size integer variable may be exceeded even for relatively small arguments (see the table below). Even floating-point approximations can exceed the maximum representable floating-point value.
It may help to recast the calculations in terms of the logarithm of the number. But if exact values for large factorials are desired, then special software is required, as in the pseudocode that follows, which implements the classic algorithm to calculate 1, 1×2, 1×2×3, 1×2×3×4, etc. the successive factorial numbers.
Constant Limit = 1000; %Sufficient digits.
Constant Base = 10; %The base of the simulated arithmetic.
Constant FactorialLimit = 365; %Target number to solve, 365!
Array digit[1:Limit] of integer; %The big number.
Integer carry,d; %Assistants during multiplication.
Integer last,i; %Indices to the big number's digits.
Array text[1:Limit] of character;%Scratchpad for the output.
Constant tdigit[0:9] of character = ["0","1","2","3","4","5","6","7","8","9"];
BEGIN
digit:=0; %Clear the whole array.
digit[1]:=1; %The big number starts with 1,
last:=1; %Its highest-order digit is number 1.
for n:=1 to FactorialLimit do %Step through producing 1!, 2!, 3!, 4!, etc.
carry:=0; %Start a multiply by n.
for i:=1 to last do %Step along every digit.
d:=digit[i]*n + carry; %The classic multiply.
digit[i]:=d mod Base; %The low-order digit of the result.
carry:=d div Base; %The carry to the next digit.
next i;
while carry > 0 %Store the carry in the big number.
if last >= Limit then croak('Overflow!'); %If possible!
last:=last + 1; %One more digit.
digit[last]:=carry mod Base; %Placed.
carry:=carry div Base; %The carry reduced.
Wend %With n > Base, maybe > 1 digit extra.
text:=" "; %Now prepare the output.
for i:=1 to last do %Translate from binary to text.
text[Limit - i + 1]:=tdigit[digit[i]]; %Reversing the order.
next i; %Arabic numerals put the low order last.
Print text," = ",n,"!"; %Print the result!
next n; %On to the next factorial up.
END;
With the example in view, a number of details can be discussed. The most important is the choice of the representation of the big number. In this case, only integer values are required for digits, so an array of fixed-width integers is adequate. It is convenient to have successive elements of the array represent higher powers of the base.
The second most important decision is in the choice of the base of arithmetic, here ten. There are many considerations. The scratchpad variable d must be able to hold the result of a single-digit multiply plus the carry from the previous digit's multiply. In base ten, a sixteen-bit integer is certainly adequate as it allows up to 32767. However, this example cheats, in that the value of n is not itself limited to a single digit. This has the consequence that the method will fail for n > 3200 or so. In a more general implementation, n would also use a multi-digit representation. A second consequence of the shortcut is that after the multi-digit multiply has been completed, the last value of carry may need to be carried into multiple higher-order digits, not just one.
There is also the issue of printing the result in base ten, for human consideration. Because the base is already ten, the result could be shown simply by printing the successive digits of array digit, but they would appear with the highest-order digit last (so that 123 would appear as "321"). The whole array could be printed in reverse order, but that would present the number with leading zeroes ("00000...000123") which may not be appreciated, so we decided to build the representation in a space-padded text variable and then print that. The first few results are:
Reach of computer numbers.
1 = 1!
2 = 2!
6 = 3!
24 = 4!
120 = 5! 8-bit unsigned
720 = 6!
5040 = 7!
40320 = 8! 16-bit unsigned
362880 = 9!
3628800 = 10!
39916800 = 11!
479001600 = 12! 32-bit unsigned
6227020800 = 13!
87178291200 = 14!
1307674368000 = 15!
20922789888000 = 16!
355687428096000 = 17!
6402373705728000 = 18!
121645100408832000 = 19!
2432902008176640000 = 20! 64-bit unsigned
51090942171709440000 = 21!
1124000727777607680000 = 22!
25852016738884976640000 = 23!
620448401733239439360000 = 24!
15511210043330985984000000 = 25!
403291461126605635584000000 = 26!
10888869450418352160768000000 = 27!
304888344611713860501504000000 = 28!
8841761993739701954543616000000 = 29!
265252859812191058636308480000000 = 30!
8222838654177922817725562880000000 = 31!
263130836933693530167218012160000000 = 32!
8683317618811886495518194401280000000 = 33!
295232799039604140847618609643520000000 = 34! 128-bit unsigned
10333147966386144929666651337523200000000 = 35!
We could try to use the available arithmetic of the computer more efficiently. A simple escalation would be to use base 100 (with corresponding changes to the translation process for output), or, with sufficiently wide computer variables (such as 32-bit integers) we could use larger bases, such as 10,000. Working in a power-of-2 base closer to the computer's built-in integer operations offers advantages, although conversion to a decimal base for output becomes more difficult. On typical modern architectures, additions and multiplications take constant time independent of the values of the operands, so long as the operands fit in single machine words, so there are large gains in packing as much of a bignumber as possible into each element of the digit array. The computer may also offer facilities for splitting a product into a digit and carry without requiring the two operations of mod and div as in the example, and nearly all architectures provide a "carry flag" which can be exploited in multiple-precision addition and subtraction. This sort of detail is the grist of machine-code programmers, and a suitable assembly-language bignumber routine can run much faster than the result of the compilation of a high-level language, which does not provide access to such facilities.
For a single-digit multiply the working variables must be able to hold the value (base-1)² + carry, where the maximum value of the carry is (base-1). Similarly, the variables used to index the digit array are themselves limited in width. A simple way to extend the indices would be to deal with the bignumber's digits in blocks of some convenient size so that the addressing would be via (block i, digit j) where i and j would be small integers, or, one could escalate to employing bignumber techniques for the indexing variables. Ultimately, machine storage capacity and execution time impose limits on the problem size.
History
IBM's first business computer, the IBM 702 (a vacuum tube machine) of the mid 1950s, implemented integer arithmetic entirely in hardware on digit strings of any length from one to 511 digits. The earliest widespread software implementation of arbitrary precision arithmetic was probably that in Maclisp. Later, around 1980, the VAX/VMS and VM/CMS operating systems offered bignum facilities as a collection of string functions in the one case and in the EXEC 2 and REXX languages in the other.
An early widespread implementation was available via the IBM 1620 of 1959-1970. The 1620 was a decimal-digit machine which used discrete transistors, yet it had hardware (that used lookup tables) to perform integer arithmetic on digit strings of a length that could be from two to whatever memory was available. For floating-point arithmetic, the mantissa was restricted to a hundred digits or fewer, and the exponent was restricted to two digits only. The largest memory supplied offered sixty thousand digits, however Fortran compilers for the 1620 settled on fixed sizes such as ten, though it could be specified on a control card if the default was not satisfactory.
Arbitrary-precision software
Stand-alone application software
Software that supports arbitrary precision computations:
- bc an arbitrary-precision math program that comes standard on most *nix systems.
- dc: the POSIX desk calculator
- Calc C-style arbitrary precision calculator (LGPL2)
- Maxima (software): a computer algebra system whose "bignum" integers are directly inherited from its implementation language Common Lisp. In addition, it supports arbitrary-precision floating-point numbers, bigfloats.
- Maple, Mathematica, and several other computer algebra software include arbitrary-precision arithmetic. Mathematica employs GMP for approximate number computation.
- Matlab with Multiprecision Computing Toolbox.
- ND1, a JavaScript and RPL programmable calculator for iPhone
- PARI/GP, an open source computer algebra system that supports arbitrary precision.
- Sage, an open-source computer algebra system
- TTCalc an open source bignum mathematical calculator (TTMath library).
- Virtual Calc 2000: arbitrary-precision and arbitrary-base calculator for Windows shareware
- Wcalc an open source calculator (GMP and MPFR libraries)
Browser Plugin
Online tools
Software that supports limited precision computations available through a web browser:
- Big Online Calculator: a bignum calculator for floating point numbers (TTMath library).
- Arbitrary Precision Calculator Applet: a bignum calculator implemented using the apfloat library, or the same without an applet: Arbitrary Precision Calculator
Libraries
Arbitrary-precision arithmetic in most computer software is implemented by calling an external library that provides data types and subroutines to store numbers with the requested precision and to perform computations.
Different libraries have different ways of representing arbitrary-precision numbers, some libraries work only with integer numbers, others store floating point numbers in a variety of bases (decimal or binary powers). Rather than representing a number as single value some store numbers as a numerator/denominator pair (Rationals) and some can fully represent computable numbers, though only up to some storage limit. Fundamentally, Turing machines cannot represent all real numbers, as the cardinality of 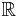 exceeds the cardinality of
exceeds the cardinality of 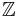 .
.
| Package / Library Name | Number Type | Language | License |
|---|---|---|---|
| apfloat | Decimal floats, integers, rationals, and complex | Java and C++ | LGPL and Freeware |
| BeeCrypt Cryptography Library | Integers | Assembly, C, C++, Java | LGPL |
| ARPREC and MPFUN | Integers, binary floats, complex binary floats | C++ with C++ and Fortran bindings | BSD |
| Base One Number Class | Decimal floats | C++ | Proprietary |
| bbnum library | Integers and floats | Assembler and C++ | New BSD |
| phpseclib | Decimal floats | PHP | LGPL |
| BCMath Arbitrary Precision Mathematics | Decimal floats | PHP | PHP License |
| BigDigits | Naturals | C | Freeware [1] |
| BigFloat | Binary Floats | C++ | GPL |
| BigNum | Binary Integers, Floats (with math functions) | C# / .NET | Freeware |
| C++ Big Integer Library | Integers | C++ | Public domain |
| CLN, a Class Library for Numbers | Integers, rationals, floats and complex | C and C++ | GPL |
| Computable Real Numbers | Reals | Common Lisp | |
| dbl<n>, Git repo | n x 53 bits precision compact & fast floating point numbers (n=2,3,4,5) | C++ template | Proprietary or GPL |
| IMSL | C | Proprietary | |
| decNumber | Decimals | C | ICU licence (MIT licence) [2] |
| FMLIB | Floats | Fortran | |
| GNU Multi-Precision Library (and MPFR) | Integers, rationals and floats | C and C++ with bindings (GMPY,...) | LGPL |
| MPCLI | Integers | C# / .NET | MIT License |
| C# Bindings for MPIR (MPIR is a fork of the GNU Multi-Precision Library)] | Integers, rationals and floats | C# / .NET | LGPL |
| GNU Multi-Precision Library for .NET | Integers | C# / .NET | LGPL |
| Eiffel Arbitrary Precision Mathematics Library | Integers | Eiffel | LGPL |
| HugeCalc | Integers | C++ and Assembler | Proprietary |
| IMath | Integers and rationals | C | MIT License |
| IntX | Integers | C# / .NET | New BSD |
| JScience LargeInteger | Integers | Java | |
| libgcrypt | Integers | C | LGPL |
| libmpdec (and cdecimal) | Decimals | C, C++ and Python | Simplified BSD |
| LibTomMath, Git repo | Integers | C and C++ | Public domain |
| LiDIA | Integers, floats, complex floats and rationals | C and C++ | Free for non-commercial use |
| MAPM | Integers and decimal floats | C (bindings for C++ and Lua) | Freeware |
| MIRACL | Integers and rationals | C and C++ | Free for non-commercial use |
| MPI | Integers | C | LGPL |
| MPArith | Integers, floats, and rationals | Pascal / Delphi | zlib |
| mpmath | Floats, complex floats | Python | New BSD |
| NTL | Integers, floats | C and C++ | GPL |
| bigInteger (and bigRational) | Integers and rationals | C and Seed7 | LGPL |
| TTMath library | Integers and binary floats | Assembler and C++ | New BSD |
| vecLib.framework | Integers | C | Proprietary |
| W3b.Sine | Decimal floats | C# / .NET | New BSD |
| Eiffel Arbitrary Precision Mathematics Library (GMP port) | Integers | Eiffel | LGPL |
| BigInt | Integers | JavaScript | Public domain |
| javascript-bignum | Scheme-compatible decimal integers, rationals, and complex | JavaScript | MIT License |
| MathX | Integers, floats | C++ | Boost Software License |
| ArbitraryPrecisionFloat | floats (Decimals, Integer and Rational are built in) | Smalltalk | MIT License |
| vlint | Integers | C++ | BSD license |
| hapint | Integers | JavaScript | MIT License or GPL |
Languages
Programming languages that supports arbitrary precision computations, either built-in, or in the standard library of the language:
- Common Lisp: The ANSI Common Lisp standard supports arbitrary precision integer, ratio and complex numbers.
- C#: System.Numerics.BigInteger (from .NET 4.0)
- ColdFusion: the built-in PrecisionEvaluate() function evaluates one or more string expressions, dynamically, from left to right, using BigDecimal precision arithmetic to calculate the values of arbitrary precision arithmetic expressions.
- Erlang: the built-in Integer datatype implements arbitrary-precision arithmetic.
- Go: the standard library package big implements arbitrary-precision integers (Int type) and rational numbers (Rat type)
- Haskell: the built-in Integer datatype implements arbitrary-precision arithmetic.
- J: built-in extended precision
- Java: class java.math.BigInteger (integer), Class java.math.BigDecimal (decimal)
- OCaml: The Num library supports arbitrary-precision integers and rationals.
- Perl: The bignum and bigrat pragmas provide BigNum and BigRational support for Perl.
- PHP: The BC Math module provides arbitrary precision mathemathics.
- Pike: the built-in int type will silently change from machine-native integer to arbitrary precision as soon as the value exceeds the former's capacity.
- Python: the built-in int (3.x) / long (2.x) integer type is of arbitrary precision. The Decimal class in the standard library module decimal has user definable precision.
- Racket: Racket's exact numbers are of arbitrary precision. For instance, (expt 10 100) produces the expected (large) result. Exact numbers also include rationals, so (/ 3 4) produces 3/4.
- REXX: programming language (including Open Object Rexx and NetRexx)
- Ruby: the built-in Bignum integer type is of arbitrary precision. The BigDecimal class in the standard library module bigdecimal has user definable precision.
- Scheme: R5RS encourages, and R6RS requires, that exact integers and exact rationals be of arbitrary precision.
- Scala: Class BigInt.
- Seed7: bigInteger and bigRational.
- Smalltalk: programming languages (including Squeak, Smalltalk/X, GNU Smalltalk, Dolphin Smalltalk, etc.)
- Standard ML: The optional built-in IntInf structure implements the INTEGER signature and supports arbitrary-precision integers.
References
- ^ R.K. Pathria, A Statistical Study of the Randomness amongst the first 10,000 Digits of Pi, 1962 Mathematics of Computation , v16, N77-80, pp 188-97 in which appears the remark "Such an extreme pattern is dangerous even if diluted by one of its neighbouring blocks" — this was the occurrence of the sequence 77 twenty-eight times in one block of a thousand digits
- Knuth, Donald (2008), Seminumerical Algorithms, The Art of Computer Programming, 2 (3 ed.), Addison-Wesley, ISBN 0-201-89684-2, Section 4.3.1: The Classical Algorithms
- Implementing Multiple-Precision Arithmetic, Part 1 and Part 2 at sputsoft.com
External links
- Chapter 9.3 of The Art of Assembly by Randall Hyde discusses multiprecision arithmetic, with examples in x86-assembly.
- Rosetta Code task Arbitrary-precision integers Case studies in the style in which over 47 programming languages compute the value of 5**4**3**2 using arbitrary precision arithmetic.
|
|||||||||||||||||||||||