Fast Fourier transform
A fast Fourier transform (FFT) is an efficient algorithm to compute the discrete Fourier transform (DFT) and its inverse. There are many distinct FFT algorithms involving a wide range of mathematics, from simple complex-number arithmetic to group theory and number theory; this article gives an overview of the available techniques and some of their general properties, while the specific algorithms are described in subsidiary articles linked below.
A DFT decomposes a sequence of values into components of different frequencies. This operation is useful in many fields (see discrete Fourier transform for properties and applications of the transform) but computing it directly from the definition is often too slow to be practical. An FFT is a way to compute the same result more quickly: computing a DFT of N points in the naive way, using the definition, takes O(N2) arithmetical operations, while an FFT can compute the same result in only O(N log N) operations. The difference in speed can be substantial, especially for long data sets where N may be in the thousands or millions—in practice, the computation time can be reduced by several orders of magnitude in such cases, and the improvement is roughly proportional to N/log(N). This huge improvement made many DFT-based algorithms practical; FFTs are of great importance to a wide variety of applications, from digital signal processing and solving partial differential equations to algorithms for quick multiplication of large integers.
The most well known FFT algorithms depend upon the factorization of N, but (contrary to popular misconception) there are FFTs with O(N log N) complexity for all N, even for prime N. Many FFT algorithms only depend on the fact that  is an
is an  th primitive root of unity, and thus can be applied to analogous transforms over any finite field, such as number-theoretic transforms.
th primitive root of unity, and thus can be applied to analogous transforms over any finite field, such as number-theoretic transforms.
Since the inverse DFT is the same as the DFT, but with the opposite sign in the exponent and a 1/N factor, any FFT algorithm can easily be adapted for it.
Contents |
Definition and speed
An FFT computes the DFT and produces exactly the same result as evaluating the DFT definition directly; the only difference is that an FFT is much faster. (In the presence of round-off error, many FFT algorithms are also much more accurate than evaluating the DFT definition directly, as discussed below.)
la transformada rapida de fourier es un te,a que se dificulto para los estudiantes de los lunes
Let x0, ...., xN-1 be complex numbers. The DFT is defined by the formula

Evaluating this definition directly requires O(N2) operations: there are N outputs Xk, and each output requires a sum of N terms. An FFT is any method to compute the same results in O(N log N) operations. More precisely, all known FFT algorithms require Θ(N log N) operations (technically, O only denotes an upper bound), although there is no proof that better complexity is impossible.
To illustrate the savings of an FFT, consider the count of complex multiplications and additions. Evaluating the DFT's sums directly involves N2 complex multiplications and N(N − 1) complex additions [of which O(N) operations can be saved by eliminating trivial operations such as multiplications by 1]. The well-known radix-2 Cooley–Tukey algorithm, for N a power of 2, can compute the same result with only (N/2) log2 N complex multiplies (again, ignoring simplifications of multiplications by 1 and similar) and N log2N complex additions. In practice, actual performance on modern computers is usually dominated by factors other than arithmetic and is a complicated subject (see, e.g., Frigo & Johnson, 2005), but the overall improvement from Θ(N2) to Θ(N log N) remains.
Computational issues
Bounds on complexity and operation counts
A fundamental question of longstanding theoretical interest is to prove lower bounds on the complexity and exact operation counts of fast Fourier transforms, and many open problems remain. It is not even rigorously proved whether DFTs truly require 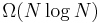 (i.e., order
(i.e., order  or greater) operations, even for the simple case of power of two sizes, although no algorithms with lower complexity are known. In particular, the count of arithmetic operations is usually the focus of such questions, although actual performance on modern-day computers is determined by many other factors such as cache or CPU pipeline optimization.
or greater) operations, even for the simple case of power of two sizes, although no algorithms with lower complexity are known. In particular, the count of arithmetic operations is usually the focus of such questions, although actual performance on modern-day computers is determined by many other factors such as cache or CPU pipeline optimization.
Following pioneering work by Winograd (1978), a tight  lower bound is known for the number of real multiplications required by an FFT. It can be shown that only
lower bound is known for the number of real multiplications required by an FFT. It can be shown that only  irrational real multiplications are required to compute a DFT of power-of-two length
irrational real multiplications are required to compute a DFT of power-of-two length  . Moreover, explicit algorithms that achieve this count are known (Heideman & Burrus, 1986; Duhamel, 1990). Unfortunately, these algorithms require too many additions to be practical, at least on modern computers with hardware multipliers.
. Moreover, explicit algorithms that achieve this count are known (Heideman & Burrus, 1986; Duhamel, 1990). Unfortunately, these algorithms require too many additions to be practical, at least on modern computers with hardware multipliers.
A tight lower bound is not known on the number of required additions, although lower bounds have been proved under some restrictive assumptions on the algorithms. In 1973, Morgenstern proved an lower bound on the addition count for algorithms where the multiplicative constants have bounded magnitudes (which is true for most but not all FFT algorithms). Pan (1986) proved an lower bound assuming a bound on a measure of the FFT algorithm's "asynchronicity", but the generality of this assumption is unclear. For the case of power-of-two , Papadimitriou (1979) argued that the number 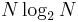 of complex-number additions achieved by Cooley–Tukey algorithms is optimal under certain assumptions on the graph of the algorithm (his assumptions imply, among other things, that no additive identities in the roots of unity are exploited). (This argument would imply that at least
of complex-number additions achieved by Cooley–Tukey algorithms is optimal under certain assumptions on the graph of the algorithm (his assumptions imply, among other things, that no additive identities in the roots of unity are exploited). (This argument would imply that at least  real additions are required, although this is not a tight bound because extra additions are required as part of complex-number multiplications.) Thus far, no published FFT algorithm has achieved fewer than complex-number additions (or their equivalent) for power-of-two .
real additions are required, although this is not a tight bound because extra additions are required as part of complex-number multiplications.) Thus far, no published FFT algorithm has achieved fewer than complex-number additions (or their equivalent) for power-of-two .
A third problem is to minimize the total number of real multiplications and additions, sometimes called the "arithmetic complexity" (although in this context it is the exact count and not the asymptotic complexity that is being considered). Again, no tight lower bound has been proven. Since 1968, however, the lowest published count for power-of-two was long achieved by the split-radix FFT algorithm, which requires  real multiplications and additions for
real multiplications and additions for 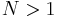 . This was recently reduced to
. This was recently reduced to  (Johnson and Frigo, 2007; Lundy and Van Buskirk, 2007).
(Johnson and Frigo, 2007; Lundy and Van Buskirk, 2007).
Most of the attempts to lower or prove the complexity of FFT algorithms have focused on the ordinary complex-data case, because it is the simplest. However, complex-data FFTs are so closely related to algorithms for related problems such as real-data FFTs, discrete cosine transforms, discrete Hartley transforms, and so on, that any improvement in one of these would immediately lead to improvements in the others (Duhamel & Vetterli, 1990).
Accuracy and approximations
All of the FFT algorithms discussed below compute the DFT exactly (in exact arithmetic, i.e. neglecting floating-point errors). A few "FFT" algorithms have been proposed, however, that compute the DFT approximately, with an error that can be made arbitrarily small at the expense of increased computations. Such algorithms trade the approximation error for increased speed or other properties. For example, an approximate FFT algorithm by Edelman et al. (1999) achieves lower communication requirements for parallel computing with the help of a fast multipole method. A wavelet-based approximate FFT by Guo and Burrus (1996) takes sparse inputs/outputs (time/frequency localization) into account more efficiently than is possible with an exact FFT. Another algorithm for approximate computation of a subset of the DFT outputs is due to Shentov et al. (1995). Only the Edelman algorithm works equally well for sparse and non-sparse data, however, since it is based on the compressibility (rank deficiency) of the Fourier matrix itself rather than the compressibility (sparsity) of the data.
Even the "exact" FFT algorithms have errors when finite-precision floating-point arithmetic is used, but these errors are typically quite small; most FFT algorithms, e.g. Cooley–Tukey, have excellent numerical properties. The upper bound on the relative error for the Cooley–Tukey algorithm is O(ε log N), compared to O(εN3/2) for the naïve DFT formula (Gentleman and Sande, 1966), where ε is the machine floating-point relative precision. In fact, the root mean square (rms) errors are much better than these upper bounds, being only O(ε √log N) for Cooley–Tukey and O(ε √N) for the naïve DFT (Schatzman, 1996). These results, however, are very sensitive to the accuracy of the twiddle factors used in the FFT (i.e. the trigonometric function values), and it is not unusual for incautious FFT implementations to have much worse accuracy, e.g. if they use inaccurate trigonometric recurrence formulas. Some FFTs other than Cooley–Tukey, such as the Rader-Brenner algorithm, are intrinsically less stable.
In fixed-point arithmetic, the finite-precision errors accumulated by FFT algorithms are worse, with rms errors growing as O(√N) for the Cooley–Tukey algorithm (Welch, 1969). Moreover, even achieving this accuracy requires careful attention to scaling in order to minimize the loss of precision, and fixed-point FFT algorithms involve rescaling at each intermediate stage of decompositions like Cooley–Tukey.
To verify the correctness of an FFT implementation, rigorous guarantees can be obtained in O(N log N) time by a simple procedure checking the linearity, impulse-response, and time-shift properties of the transform on random inputs (Ergün, 1995).
Algorithms
Cooley–Tukey algorithm
By far the most common FFT is the Cooley–Tukey algorithm. This is a divide and conquer algorithm that recursively breaks down a DFT of any composite size N = N1N2 into many smaller DFTs of sizes N1 and N2, along with O(N) multiplications by complex roots of unity traditionally called twiddle factors (after Gentleman and Sande, 1966).
This method (and the general idea of an FFT) was popularized by a publication of J. W. Cooley and J. W. Tukey in 1965, but it was later discovered (Heideman & Burrus, 1984) that those two authors had independently re-invented an algorithm known to Carl Friedrich Gauss around 1805 (and subsequently rediscovered several times in limited forms).
The most well-known use of the Cooley–Tukey algorithm is to divide the transform into two pieces of size  at each step, and is therefore limited to power-of-two sizes, but any factorization can be used in general (as was known to both Gauss and Cooley/Tukey). These are called the radix-2 and mixed-radix cases, respectively (and other variants such as the split-radix FFT have their own names as well). Although the basic idea is recursive, most traditional implementations rearrange the algorithm to avoid explicit recursion. Also, because the Cooley–Tukey algorithm breaks the DFT into smaller DFTs, it can be combined arbitrarily with any other algorithm for the DFT, such as those described below.
at each step, and is therefore limited to power-of-two sizes, but any factorization can be used in general (as was known to both Gauss and Cooley/Tukey). These are called the radix-2 and mixed-radix cases, respectively (and other variants such as the split-radix FFT have their own names as well). Although the basic idea is recursive, most traditional implementations rearrange the algorithm to avoid explicit recursion. Also, because the Cooley–Tukey algorithm breaks the DFT into smaller DFTs, it can be combined arbitrarily with any other algorithm for the DFT, such as those described below.
Other FFT algorithms
There are other FFT algorithms distinct from Cooley–Tukey. For  with coprime
with coprime 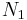 and
and  , one can use the Prime-Factor (Good-Thomas) algorithm (PFA), based on the Chinese Remainder Theorem, to factorize the DFT similarly to Cooley–Tukey but without the twiddle factors. The Rader-Brenner algorithm (1976) is a Cooley–Tukey-like factorization but with purely imaginary twiddle factors, reducing multiplications at the cost of increased additions and reduced numerical stability; it was later superseded by the split-radix variant of Cooley–Tukey (which achieves the same multiplication count but with fewer additions and without sacrificing accuracy). Algorithms that recursively factorize the DFT into smaller operations other than DFTs include the Bruun and QFT algorithms. (The Rader-Brenner and QFT algorithms were proposed for power-of-two sizes, but it is possible that they could be adapted to general composite
, one can use the Prime-Factor (Good-Thomas) algorithm (PFA), based on the Chinese Remainder Theorem, to factorize the DFT similarly to Cooley–Tukey but without the twiddle factors. The Rader-Brenner algorithm (1976) is a Cooley–Tukey-like factorization but with purely imaginary twiddle factors, reducing multiplications at the cost of increased additions and reduced numerical stability; it was later superseded by the split-radix variant of Cooley–Tukey (which achieves the same multiplication count but with fewer additions and without sacrificing accuracy). Algorithms that recursively factorize the DFT into smaller operations other than DFTs include the Bruun and QFT algorithms. (The Rader-Brenner and QFT algorithms were proposed for power-of-two sizes, but it is possible that they could be adapted to general composite 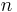 . Bruun's algorithm applies to arbitrary even composite sizes.) Bruun's algorithm, in particular, is based on interpreting the FFT as a recursive factorization of the polynomial
. Bruun's algorithm applies to arbitrary even composite sizes.) Bruun's algorithm, in particular, is based on interpreting the FFT as a recursive factorization of the polynomial  , here into real-coefficient polynomials of the form
, here into real-coefficient polynomials of the form  and
and  .
.
Another polynomial viewpoint is exploited by the Winograd algorithm, which factorizes into cyclotomic polynomials—these often have coefficients of 1, 0, or −1, and therefore require few (if any) multiplications, so Winograd can be used to obtain minimal-multiplication FFTs and is often used to find efficient algorithms for small factors. Indeed, Winograd showed that the DFT can be computed with only 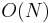 irrational multiplications, leading to a proven achievable lower bound on the number of multiplications for power-of-two sizes; unfortunately, this comes at the cost of many more additions, a tradeoff no longer favorable on modern processors with hardware multipliers. In particular, Winograd also makes use of the PFA as well as an algorithm by Rader for FFTs of prime sizes.
irrational multiplications, leading to a proven achievable lower bound on the number of multiplications for power-of-two sizes; unfortunately, this comes at the cost of many more additions, a tradeoff no longer favorable on modern processors with hardware multipliers. In particular, Winograd also makes use of the PFA as well as an algorithm by Rader for FFTs of prime sizes.
Rader's algorithm, exploiting the existence of a generator for the multiplicative group modulo prime , expresses a DFT of prime size as a cyclic convolution of (composite) size  , which can then be computed by a pair of ordinary FFTs via the convolution theorem (although Winograd uses other convolution methods). Another prime-size FFT is due to L. I. Bluestein, and is sometimes called the chirp-z algorithm; it also re-expresses a DFT as a convolution, but this time of the same size (which can be zero-padded to a power of two and evaluated by radix-2 Cooley–Tukey FFTs, for example), via the identity
, which can then be computed by a pair of ordinary FFTs via the convolution theorem (although Winograd uses other convolution methods). Another prime-size FFT is due to L. I. Bluestein, and is sometimes called the chirp-z algorithm; it also re-expresses a DFT as a convolution, but this time of the same size (which can be zero-padded to a power of two and evaluated by radix-2 Cooley–Tukey FFTs, for example), via the identity  .
.
FFT algorithms specialized for real and/or symmetric data
In many applications, the input data for the DFT are purely real, in which case the outputs satisfy the symmetry

and efficient FFT algorithms have been designed for this situation (see e.g. Sorensen, 1987). One approach consists of taking an ordinary algorithm (e.g. Cooley–Tukey) and removing the redundant parts of the computation, saving roughly a factor of two in time and memory. Alternatively, it is possible to express an even-length real-input DFT as a complex DFT of half the length (whose real and imaginary parts are the even/odd elements of the original real data), followed by O(N) post-processing operations.
It was once believed that real-input DFTs could be more efficiently computed by means of the discrete Hartley transform (DHT), but it was subsequently argued that a specialized real-input DFT algorithm (FFT) can typically be found that requires fewer operations than the corresponding DHT algorithm (FHT) for the same number of inputs. Bruun's algorithm (above) is another method that was initially proposed to take advantage of real inputs, but it has not proved popular.
There are further FFT specializations for the cases of real data that have even/odd symmetry, in which case one can gain another factor of (roughly) two in time and memory and the DFT becomes the discrete cosine/sine transform(s) (DCT/DST). Instead of directly modifying an FFT algorithm for these cases, DCTs/DSTs can also be computed via FFTs of real data combined with O(N) pre/post processing.
Multidimensional FFTs
As defined in the multidimensional DFT article, the multidimensional DFT

transforms an array  with a
with a 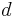 -dimensional vector of indices
-dimensional vector of indices  by a set of nested summations (over
by a set of nested summations (over 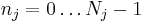 for each
for each  ), where the division
), where the division  , defined as
, defined as  , is performed element-wise. Equivalently, it is simply the composition of a sequence of sets of one-dimensional DFTs, performed along one dimension at a time (in any order).
, is performed element-wise. Equivalently, it is simply the composition of a sequence of sets of one-dimensional DFTs, performed along one dimension at a time (in any order).
This compositional viewpoint immediately provides the simplest and most common multidimensional DFT algorithm, known as the row-column algorithm (after the two-dimensional case, below). That is, one simply performs a sequence of one-dimensional FFTs (by any of the above algorithms): first you transform along the  dimension, then along the
dimension, then along the  dimension, and so on (or actually, any ordering will work). This method is easily shown to have the usual
dimension, and so on (or actually, any ordering will work). This method is easily shown to have the usual  complexity, where
complexity, where  is the total number of data points transformed. In particular, there are
is the total number of data points transformed. In particular, there are  transforms of size , etcetera, so the complexity of the sequence of FFTs is:
transforms of size , etcetera, so the complexity of the sequence of FFTs is:
![\begin{align}
& {} \qquad \frac{N}{N_1} O(N_1 \log N_1) + \cdots + \frac{N}{N_d} O(N_d \log N_d) \\[6pt]
& = O\left(N \left[\log N_1 + \cdots + \log N_d\right]\right) = O(N \log N).
\end{align}](/2010-wikipedia_en_wp1-0.8_orig_2010-12/I/4f4007296852689639259ba53363e62b.png)
In two dimensions, the  can be viewed as an
can be viewed as an 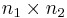 matrix, and this algorithm corresponds to first performing the FFT of all the rows and then of all the columns (or vice versa), hence the name.
matrix, and this algorithm corresponds to first performing the FFT of all the rows and then of all the columns (or vice versa), hence the name.
In more than two dimensions, it is often advantageous for cache locality to group the dimensions recursively. For example, a three-dimensional FFT might first perform two-dimensional FFTs of each planar "slice" for each fixed , and then perform the one-dimensional FFTs along the direction. More generally, an asymptotically optimal cache-oblivious algorithm consists of recursively dividing the dimensions into two groups 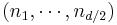 and
and  that are transformed recursively (rounding if is not even) (see Frigo and Johnson, 2005). Still, this remains a straightforward variation of the row-column algorithm that ultimately requires only a one-dimensional FFT algorithm as the base case, and still has complexity. Yet another variation is to perform matrix transpositions in between transforming subsequent dimensions, so that the transforms operate on contiguous data; this is especially important for out-of-core and distributed memory situations where accessing non-contiguous data is extremely time-consuming.
that are transformed recursively (rounding if is not even) (see Frigo and Johnson, 2005). Still, this remains a straightforward variation of the row-column algorithm that ultimately requires only a one-dimensional FFT algorithm as the base case, and still has complexity. Yet another variation is to perform matrix transpositions in between transforming subsequent dimensions, so that the transforms operate on contiguous data; this is especially important for out-of-core and distributed memory situations where accessing non-contiguous data is extremely time-consuming.
There are other multidimensional FFT algorithms that are distinct from the row-column algorithm, although all of them have complexity. Perhaps the simplest non-row-column FFT is the vector-radix FFT algorithm, which is a generalization of the ordinary Cooley–Tukey algorithm where one divides the transform dimensions by a vector  of radices at each step. (This may also have cache benefits.) The simplest case of vector-radix is where all of the radices are equal (e.g. vector-radix-2 divides all of the dimensions by two), but this is not necessary. Vector radix with only a single non-unit radix at a time, i.e.
of radices at each step. (This may also have cache benefits.) The simplest case of vector-radix is where all of the radices are equal (e.g. vector-radix-2 divides all of the dimensions by two), but this is not necessary. Vector radix with only a single non-unit radix at a time, i.e.  , is essentially a row-column algorithm. Other, more complicated, methods include polynomial transform algorithms due to Nussbaumer (1977), which view the transform in terms of convolutions and polynomial products. See Duhamel and Vetterli (1990) for more information and references.
, is essentially a row-column algorithm. Other, more complicated, methods include polynomial transform algorithms due to Nussbaumer (1977), which view the transform in terms of convolutions and polynomial products. See Duhamel and Vetterli (1990) for more information and references.
Other generalizations
An O(N5/2 log N) generalization to spherical harmonics on the sphere S2 with N2 nodes was described by Mohlenkamp (1999), along with an algorithm conjectured (but not proven) to have O(N2 log2 N) complexity; Mohlenkamp also provides an implementation in the libftsh library. A spherical-harmonic algorithm with O(N2 log N) complexity is described by Rokhlin and Tygert (2006).
Various groups have also published "FFT" algorithms for non-equispaced data, as reviewed in Potts et al. (2001). Such algorithms do not strictly compute the DFT (which is only defined for equispaced data), but rather some approximation thereof (a non-uniform discrete Fourier transform, or NDFT, which itself is often computed only approximately).
See also
- Split-radix FFT algorithm
- Prime-factor FFT algorithm
- Bruun's FFT algorithm
- Rader's FFT algorithm
- Bluestein's FFT algorithm
- Butterfly diagram - a diagram used to describe FFTs.
- Odlyzko–Schönhage algorithm applies the FFT to finite Dirichlet series.
- Overlap add/Overlap save - efficient convolution methods using FFT for long signals
- Spectral music (involves application of FFT analysis to musical composition)
- Spectrum analyzers - Devices that perform an FFT
- FFTW "Fastest Fourier Transform in the West" - 'C' library for the discrete Fourier transform (DFT) in one or more dimensions.
- Time Series
- Math Kernel Library
References
- N. Brenner and C. Rader, 1976, A New Principle for Fast Fourier Transformation, IEEE Acoustics, Speech & Signal Processing 24: 264-266.
- Brigham, E.O. (2002), The Fast Fourier Transform, New York: Prentice-Hall
- Cooley, James W., and John W. Tukey, 1965, "An algorithm for the machine calculation of complex Fourier series," Math. Comput. 19: 297–301.
- Thomas H. Cormen, Charles E. Leiserson, Ronald L. Rivest, and Clifford Stein, 2001. Introduction to Algorithms, 2nd. ed. MIT Press and McGraw-Hill. ISBN 0-262-03293-7. Especially chapter 30, "Polynomials and the FFT."
- Pierre Duhamel, 1990, Algorithms meeting the lower bounds on the multiplicative complexity of length-
 DFTs and their connection with practical algorithms, IEEE Trans. Acoust. Speech. Sig. Proc. 38: 1504-151.
DFTs and their connection with practical algorithms, IEEE Trans. Acoust. Speech. Sig. Proc. 38: 1504-151. - P. Duhamel and M. Vetterli, 1990, Fast Fourier transforms: a tutorial review and a state of the art, Signal Processing 19: 259–299.
- A. Edelman, P. McCorquodale, and S. Toledo, 1999, The Future Fast Fourier Transform?, SIAM J. Sci. Computing 20: 1094–1114.
- Funda Ergün, 1995, Testing multivariate linear functions: Overcoming the generator bottleneck, Proc. 27th ACM Symposium on the Theory of Computing: 407–416.
- M. Frigo and S. G. Johnson, 2005, "The Design and Implementation of FFTW3," Proceedings of the IEEE 93: 216–231.
- Carl Friedrich Gauss, 1866. "Nachlass: Theoria interpolationis methodo nova tractata," Werke band 3, 265–327. Göttingen: Königliche Gesellschaft der Wissenschaften.
- W. M. Gentleman and G. Sande, 1966, "Fast Fourier transforms—for fun and profit," Proc. AFIPS 29: 563–578.
- H. Guo and C. S. Burrus, 1996, Fast approximate Fourier transform via wavelets transform, Proc. SPIE Intl. Soc. Opt. Eng. 2825: 250–259.
- H. Guo, G. A. Sitton, C. S. Burrus, 1994, The Quick Discrete Fourier Transform, Proc. IEEE Conf. Acoust. Speech and Sig. Processing (ICASSP) 3: 445–448.
- Heideman, M. T., D. H. Johnson, and C. S. Burrus, "Gauss and the history of the fast Fourier transform," IEEE ASSP Magazine, 1, (4), 14–21 (1984).
- Michael T. Heideman and C. Sidney Burrus, 1986, On the number of multiplications necessary to compute a length- DFT, IEEE Trans. Acoust. Speech. Sig. Proc. 34: 91-95.
- S. G. Johnson and M. Frigo, 2007. "A modified split-radix FFT with fewer arithmetic operations," IEEE Trans. Signal Processing 55 (1): 111–119.
- T. Lundy and J. Van Buskirk, 2007. "A new matrix approach to real FFTs and convolutions of length 2k," Computing 80 (1): 23-45.
- Jacques Morgenstern, 1973, Note on a lower bound of the linear complexity of the fast Fourier transform, J. ACM 20: 305-306.
- M. J. Mohlenkamp, 1999, "A fast transform for spherical harmonics", J. Fourier Anal. Appl. 5, 159–184. (preprint)
- H. J. Nussbaumer, 1977, Digital filtering using polynomial transforms, Electronics Lett. 13: 386-387.
- V. Pan, 1986, The trade-off between the additive complexity and the asyncronicity of linear and bilinear algorithms, Information Proc. Lett. 22: 11-14.
- Christos H. Papadimitriou, 1979, Optimality of the fast Fourier transform, J. ACM 26: 95-102.
- D. Potts, G. Steidl, and M. Tasche, 2001. "Fast Fourier transforms for nonequispaced data: A tutorial", in: J.J. Benedetto and P. Ferreira (Eds.), Modern Sampling Theory: Mathematics and Applications (Birkhauser).
- Vladimir Rokhlin and Mark Tygert, 2006, "Fast algorithms for spherical harmonic expansions," SIAM J. Sci. Computing 27 (6): 1903-1928.
- James C. Schatzman, 1996, Accuracy of the discrete Fourier transform and the fast Fourier transform, SIAM J. Sci. Comput. 17: 1150–1166.
- O. V. Shentov, S. K. Mitra, U. Heute, and A. N. Hossen, 1995, Subband DFT. I. Definition, interpretations and extensions, Signal Processing 41: 261–277.
- H. V. Sorensen, D. L. Jones, M. T. Heideman, and C. S. Burrus, 1987, Real-valued fast Fourier transform algorithms, IEEE Trans. Acoust. Speech Sig. Processing ASSP-35: 849–863. See also Corrections to "Real-valued fast Fourier transform algorithms"
- Peter D. Welch, 1969, A fixed-point fast Fourier transform error analysis, IEEE Trans. Audio Electroacoustics 17: 151–157.
- S. Winograd, 1978, On computing the discrete Fourier transform, Math. Computation 32: 175-199.
External links
- Fast Fourier Transforms, Connexions online book edited by C. Sidney Burrus, with chapters by C. Sidney Burrus, Ivan Selesnick, Markus Pueschel, Matteo Frigo, and Steven G. Johnson (2008).
- Links to FFT code and information online.
- National Taiwan University - FFT
- FFT programming in C++ — Cooley–Tukey algorithm.
- Online documentation, links, book, and code.
- Using FFT to construct aggregate probability distributions
- Sri Welaratna, "30 years of FFT Analyzers", Sound and Vibration (January 1997, 30th anniversary issue). A historical review of hardware FFT devices.
- FFT Basics and Case Study Using Multi-Instrument
- FFT Textbook notes, PPTs at Holistic Numerical Methods Institute.
- ALGLIB FFT Code GPL Licensed multilanguage (VBA, C++, Pascal, etc.) numerical analysis and data processing library.