Byte
The byte (pronounced /ˈbaɪt/) is a unit of digital information in computing and telecommunications. It is an ordered collection of bits, in which each bit denotes the binary value of 1 or 0. Historically, a byte was the number of bits (typically 5, 6, 7, 8, 9, or 16) used to encode a single character of text in a computer[1][2] and it is for this reason the basic addressable element in many computer architectures. The size of a byte is typically hardware dependent, but the modern de facto standard is 8 bits, as this is a convenient power of 2. Most of the numeric values used by many applications are representable in 8 bits and processor designers optimize for this common usage. Signal processing applications tend to operate on larger values and some digital signal processors have 16 or 40 bits as the smallest unit of addressable storage (on such processors a byte may be defined to contain this number of bits).
The term octet was explicitly defined to denote a sequence of 8 bits because of the ambiguity associated with the term byte and is widely used in communications protocol specifications.
Contents |
History
The term byte was coined by Dr. Werner Buchholz in July 1956, during the early design phase for the IBM Stretch computer.[3][4][5] Originally it was defined in instructions by a 4-bit field, allowing sixteen values and typical I/O equipment of the period used six-bit bytes. A fixed eight-bit byte size was later adopted and promulgated as a standard by the System/360.
Early microprocessors, such as Intel 8008 (the direct predecessor of the 8080, and then 8086) could perform a small number of operations on four bits, such as the DAA (decimal adjust) instruction, and the half carry flag, that were used to implement decimal arithmetic routines. These four-bit quantities were called nibbles, in homage to the then-common 8-bit bytes.
Historical IETF documents cite varying examples of byte sizes. RFC 608 mentions byte sizes for FTP hosts (the FTP-BYTE-SIZE attribute in host tables for the ARPANET) to be 36 bits for PDP-10 computers and 32 bits for IBM 360 systems.[6]
Size
Architectures that did not have eight-bit bytes include the CDC 6000 series scientific mainframes that divided their 60-bit floating-point words into 10 six-bit bytes. These bytes conveniently held character data from punched Hollerith cards, typically the upper-case alphabet and decimal digits. CDC also often referred to 12-bit quantities as bytes, each holding two 6-bit display code characters, due to the 12-bit I/O architecture of the machine. The PDP-10 used assembly instructions LDB and DPB to load and deposit bytes of any width from 1 to 36-bits—these operations survive today in Common Lisp. Bytes of six, seven, or nine bits were used on some computers, for example within the 36-bit word of the PDP-10. The UNIVAC 1100/2200 series computers (now Unisys) addressed in both 6-bit (Fieldata) and nine-bit (ASCII) modes within its 36-bit word. Telex machines used 5 bits to encode a character.
Factors behind the ubiquity of the eight bit byte include the popularity of the IBM System/360 architecture, introduced in the 1960s, and the 8-bit microprocessors, introduced in the 1970s. The term octet unambiguously specifies an eight-bit byte (such as in protocol definitions, for example).
Unit symbol or abbreviation
| Prefixes for bit and byte multiples | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
|
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
IEEE 1541 and the Metric Interchange Format[7]specify B as the symbol for byte (e.g., MB means megabyte), while IEC 60027 seems silent on the subject. B is also the symbol of the bel, a unit of logarithmic power ratios, which is consistent with the convention in the International System of Units (SI) that symbols for units named after persons, in this case Alexander Graham Bell, are capitalized. Usage of a capital B for byte is not consistent with this convention. However, there is little danger of confusion because the bel is a rarely used unit and its common submultiple, the decibel (dB), is used almost exclusively for signal strength and sound pressure level measurements, while the decibyte (one tenth of a byte) is never used.
The unit symbol KB is commonly used for kilobyte, but is often confused with the use of kb to mean kilobit. IEEE 1541 specifies b as the symbol for bit, however, the IEC 60027 and Metric-Interchange-Format specify bit (e.g., Mbit for megabit) for the symbol, achieving maximum disambiguation from byte.
The lowercase letter o for octet is a commonly used symbol in several non-English languages (e.g. French[8] and Romanian), and is also used with metric prefixes (for example, ko and Mo)
Today the harmonized ISO/IEC 80000-13:2008 - Quantities and units -- Part 13: Information science and technology standard cancels and replaces subclauses 3.8 and 3.9 of IEC 60027-2:2005 (those related to Information theory and Prefixes for binary multiples). See Units of Information for detailed discussion on names for derived units.
Unit multiples
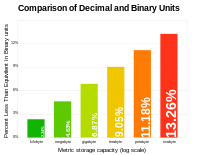
There has been considerable confusion about the meanings of SI (or metric) prefixes used with the unit byte, especially concerning prefixes such as kilo (k or K) and mega (M) as shown in the chart Prefixes for bit and byte. Since computer memory is designed with binary logic, multiples are expressed in powers of 2, rather than 10. The software and computer industries often use binary estimates of the SI-prefixed quantities, while producers of computer storage devices prefer the SI values. This is the reason for specifying computer hard drive capacities of, say, 100 GB, when it contains 93 GiB of storage space.
While the numerical difference between the decimal and binary interpretations is small for the prefixes kilo and mega, it grows to over 20% for prefix yotta, illustrated in the linear-log graph (at right) of difference versus storage size.
Common uses
The byte is also defined as a data type in certain programming languages. The C and C++ programming languages, for example, define byte as an "addressable unit of data large enough to hold any member of the basic character set of the execution environment" (clause 3.6 of the C standard). The C standard requires that the char integral data type is capable of holding at least 255 different values, and is represented by at least 8 bits (clause 5.2.4.2.1). Various implementations of C and C++ define a byte as 8, 9, 16, 32, or 36 bits[9][10]. The actual number of bits in a particular implementation is documented as CHAR_BIT as implemented in the limits.h file. Java's primitive byte data type is always defined as consisting of 8 bits and being a signed data type, holding values from −128 to 127.
In data transmission systems, a contiguous sequence of binary bits in a serial data stream, such as in modem or satellite communications, which is the smallest meaningful unit of data. These bytes might include start bits, stop bits, or parity bits, and thus could vary from 7 to 12 bits to contain a single 7-bit ASCII code.
See also
- Data hierarchy
- Primitive data type
- Nibble
References
- ↑ R.W. Bemer and W. Buchholz (1962). "Planning a Computer System - Project Stretch". In Werner Buchholz. http://archive.computerhistory.org/resources/text/IBM/Stretch/pdfs/Buchholz_102636426.pdf., Chapter 6, Character Set
- ↑ R.W. Bemer, A proposal for a generalized card code of 256 characters, Commun. ACM 2 (9), pp19–23, 1959.
- ↑ Bob Bemer. "Origins of the Term "BYTE"". http://www.trailing-edge.com/~bobbemer/BYTE.HTM. Retrieved 2007-08-12.
- ↑ Werner Buchholz (July 1956). "TIMELINE OF THE IBM STRETCH/HARVEST ERA (1956–1961)". computerhistory.org. http://archive.computerhistory.org/resources/text/IBM/Stretch/102636400.txt.
- ↑ "byte definition". http://catb.org/~esr/jargon/html/B/byte.html.
- ↑ RFC 608, Host Names On-Line, M.D. Kudlick, SRI-ARC (January 10, 1974)
- ↑ Metric-Interchange-Format
- ↑ "When is a kilobyte a kibibyte? And an MB an MiB?". The International System of Units and the IEC. International Electrotechnical Commission. http://www.iec.ch/zone/si/si_bytes.htm. Retrieved August 30, 2010.)
- ↑ [26] Built-in / intrinsic / primitive data types, C++ FAQ Lite
- ↑ Integer Types In C and C++
|
||||||||||||||||||||
|
|||||||||||||||||||||||