Translation (genetics)

This article is part of the series on: Gene expression |
|||
| Introduction to Genetics | |||
| General flow: DNA > RNA > Protein | |||
| special transfers (RNA > RNA, RNA > DNA, Protein > Protein) |
|||
| Genetic code | |||
| Transcription | |||
| Transcription (Transcription factors, RNA Polymerase,promoter) |
|||
| post-transcriptional modification (hnRNA,Splicing) |
|||
| Translation | |||
| Translation (Ribosome,tRNA) | |||
| post-translational modification (functional groups, peptides, structural changes) |
|||
| gene regulation | |||
| epigenetic regulation (Hox genes, Genomic imprinting) |
|||
| transcriptional regulation | |||
| post-transcriptional regulation (sequestration, alternative splicing,miRNA) |
|||
| post-translational regulation (reversible,irrevesible) |
|||
Translation is the first stage of protein biosynthesis (part of the overall process of gene expression). Translation occurs in the cytoplasm where the ribosomes are located. Ribosomes are made of a small and large subunit which surrounds the mRNA. In translation, messenger RNA (mRNA) is decoded to produce a specific polypeptide according to the rules specified by the genetic code. This uses an mRNA sequence as a template to guide the synthesis of a chain of amino acids that form a protein. Many types of transcribed RNA, such as transfer RNA, ribosomal RNA, and small nuclear RNA are not necessarily translated into an amino acid sequence. Translation proceeds in four phases: activation, initiation, elongation and termination (all describing the growth of the amino acid chain, or polypeptide that is the product of translation). Amino acids are brought to ribosomes and assembled into proteins.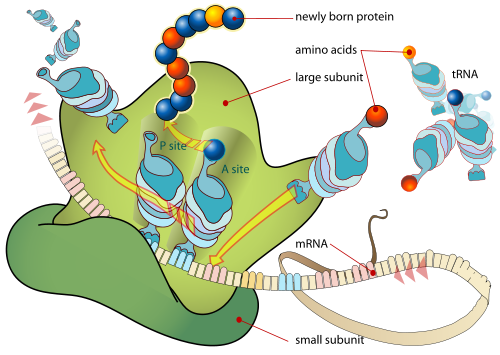
In activation, the correct amino acid is covalently bonded to the correct transfer RNA (tRNA). While this is not technically a step in translation, it is required for translation to proceed. The amino acid is joined by its carboxyl group to the 3' OH of the tRNA by an ester bond. When the tRNA has an amino acid linked to it, it is termed "charged". Initiation involves the small subunit of the ribosome binding to 5' end of mRNA with the help of initiation factors (IF). Termination of the polypeptide happens when the A site of the ribosome faces a stop codon (UAA, UAG, or UGA). When this happens, no tRNA can recognize it, but a releasing factor can recognize nonsense codons and causes the release of the polypeptide chain. The capacity of disabling or inhibiting translation in protein biosynthesis is used by antibiotics such as: anisomycin, cycloheximide, chloramphenicol, tetracycline, streptomycin, erythromycin, puromycin etc.
Contents |
Basic mechanisms
- See articles at prokaryotic translation and eukaryotic translation
The mRNA carries genetic information encoded as a ribonucleotide sequence from the chromosomes to the ribosomes. The ribonucleotides are "read" by translational machinery in a sequence of nucleotide triplets called codons. Each of those triplets codes for a specific amino acid.
The ribosome and tRNA molecules translate this code to a specific sequence of amino acids. The ribosome is a multisubunit structure containing rRNA and proteins. It is the "factory" where amino acids are assembled into proteins. tRNAs are small noncoding RNA chains (74-93 nucleotides) that transport amino acids to the ribosome. tRNAs have a site for amino acid attachment, and a site called an anticodon. The anticodon is an RNA triplet complementary to the mRNA triplet that codes for their cargo amino acid.
Aminoacyl tRNA synthetase (an enzyme) catalyzes the bonding between specific tRNAs and the amino acids that their anticodons sequences call for. The product of this reaction is an aminoacyl-tRNA molecule. This aminoacyl-tRNA travels inside the ribosome, where mRNA codons are matched through complementary base pairing to specific tRNA anticodons. The amino acids that the tRNAs carry are then used to assemble a protein. The energy required for translation of proteins is significant. For a protein containing n amino acids, the number of high-energy Phosphate bonds required to translate it is 4n-1.
Translation by hand
It is also possible to translate either by hand (for short sequences) or by computer (after first programming one appropriately, see section below), this allows biologists and chemists to draw out the chemical structure of the encoded protein on paper.
First, convert each template DNA base to its RNA complement (note that the complement of A is now U), as shown below. Note that the template strand of the DNA is the one the RNA is polymerized against; the other DNA strand would be the same as the RNA, but with thymine instead of uracil.
DNA -> RNA A -> U T -> A G -> C C -> G
Then split the RNA into triplets (groups of three bases). Note that there are 3 translation "windows", or reading frames, depending on where you start reading the code. Finally, use the table at Genetic code to translate the above into a structural formula as used in chemistry.
This will give you the primary structure of the protein. However, proteins tend to fold, depending in part on hydrophilic and hydrophobic segments along the chain. Secondary structure can often still be guessed at, but the proper tertiary structure is often very hard to determine.
This approach may not give the correct amino acid composition of the protein, in particular if unconventional amino acids such as selenocysteine are incorporated into the protein, which is coded for by a conventional stop codon in combination with a downstream hairpin (SElenoCysteine Insertion Sequence, or SECIS).
Translation by computer
Many computer programs capable of translating a DNA/RNA sequence into protein sequence exist. Normally this is performed using the Standard Genetic Code; many bioinformaticians have written at least one such program at some point in their education. However, few programs can handle all the "special" cases, such as the use of the alternative initiation codons. For example, the rare alternative start codon TTG codes for Methionine when used as a start codon, and for Leucine in all other positions.
Example: Condensed translation table for the Standard Genetic Code (from the NCBI Taxonomy webpage).
AAs = FFLLSSSSYY**CC*WLLLLPPPPHHQQRRRRIIIMTTTTNNKKSSRRVVVVAAAADDEEGGGG Starts = ---M---------------M---------------M---------------------------- Base1 = TTTTTTTTTTTTTTTTCCCCCCCCCCCCCCCCAAAAAAAAAAAAAAAAGGGGGGGGGGGGGGGG Base2 = TTTTCCCCAAAAGGGGTTTTCCCCAAAAGGGGTTTTCCCCAAAAGGGGTTTTCCCCAAAAGGGG Base3 = TCAGTCAGTCAGTCAGTCAGTCAGTCAGTCAGTCAGTCAGTCAGTCAGTCAGTCAGTCAGTCAG
Translation tables
Even when working with ordinary Eukaryotic sequences such as the Yeast genome, it is often desired to be able to use alternative translation tables -- namely for translation of the mitochondrial genes. Currently the following translation tables are defined by the NCBI Taxonomy Group for the translation of the sequences in GenBank:
1: The Standard 2: The Vertebrate Mitochondrial Code 3: The Yeast Mitochondrial Code 4: The Mold, Protozoan, and Coelenterate Mitochondrial Code and the Mycoplasma/Spiroplasma Code 5: The Invertebrate Mitochondrial Code 6: The Ciliate, Dasycladacean and Hexamita Nuclear Code 9: The Echinoderm and Flatworm Mitochondrial Code 10: The Euplotid Nuclear Code 11: The Bacterial and Plant Plastid Code 12: The Alternative Yeast Nuclear Code 13: The Ascidian Mitochondrial Code 14: The Alternative Flatworm Mitochondrial Code 15: Blepharisma Nuclear Code 16: Chlorophycean Mitochondrial Code 21: Trematode Mitochondrial Code 22: Scenedesmus obliquus mitochondrial Code 23: Thraustochytrium Mitochondrial Code
Software examples
- ApE (Mac, Windows, Unix)
- DNA Strider (Mac)
- ExPASy Translate Tool (webserver)
- Virtual Ribosome (webserver, cross-platform command-line)
- DNA to protein translation (webserver, 13 genomic codes or custom ones)
Example of computational translation - notice the indication of (alternative) start-codons:
VIRTUAL RIBOSOME
----
Translation table: Standard SGC0
>Seq1
Reading frame: 1
M V L S A A D K G N V K A A W G K V G G H A A E Y G A E A L
5' ATGGTGCTGTCTGCCGCCGACAAGGGCAATGTCAAGGCCGCCTGGGGCAAGGTTGGCGGCCACGCTGCAGAGTATGGCGCAGAGGCCCTG 90
>>>...)))..............................................................................)))
E R M F L S F P T T K T Y F P H F D L S H G S A Q V K G H G
5' GAGAGGATGTTCCTGAGCTTCCCCACCACCAAGACCTACTTCCCCCACTTCGACCTGAGCCACGGCTCCGCGCAGGTCAAGGGCCACGGC 180
......>>>...))).......................................))).................................
A K V A A A L T K A V E H L D D L P G A L S E L S D L H A H
5' GCGAAGGTGGCCGCCGCGCTGACCAAAGCGGTGGAACACCTGGACGACCTGCCCGGTGCCCTGTCTGAACTGAGTGACCTGCACGCTCAC 270
..................)))..................)))......))).........)))......)))......))).........
K L R V D P V N F K L L S H S L L V T L A S H L P S D F T P
5' AAGCTGCGTGTGGACCCGGTCAACTTCAAGCTTCTGAGCCACTCCCTGCTGGTGACCCTGGCCTCCCACCTCCCCAGTGATTTCACCCCC 360
...)))...........................))).........))))))......)))..............................
A V H A S L D K F L A N V S T V L T S K Y R *
5' GCGGTCCACGCCTCCCTGGACAAGTTCTTGGCCAACGTGAGCACCGTGCTGACCTCCAAATACCGTTAA 429
...............))).........)))..................)))...............***
Annotation key:
>>> : START codon (strict)
))) : START codon (alternative)
*** : STOP
References
- Pamela C Champe, Richard A Harvey and Denise R Ferrier (2005). Lippincott's Illustrated Reviews: Biochemistry (3rd ed.). Lippincott Williams & Wilkins. ISBN 0-7817-2265-9.
- David L. Nelson and Michael M. Cox (2005). Lehninger Principles of Biochemistry (4th ed.). W.H. Freeman. ISBN 0-7167-4339-6.
|
|||||||||||
|
||||||||