Sorting algorithm
In computer science and mathematics, a sorting algorithm is an algorithm that puts elements of a list in a certain order. The most-used orders are numerical order and lexicographical order. Efficient sorting is important to optimizing the use of other algorithms (such as search and merge algorithms) that require sorted lists to work correctly; it is also often useful for canonicalizing data and for producing human-readable output. More formally, the output must satisfy two conditions:
- The output is in nondecreasing order (each element is no smaller than the previous element according to the desired total order);
- The output is a permutation, or reordering, of the input.
Since the dawn of computing, the sorting problem has attracted a great deal of research, perhaps due to the complexity of solving it efficiently despite its simple, familiar statement. For example, bubble sort was analyzed as early as 1956.[1] Although many consider it a solved problem, useful new sorting algorithms are still being invented (for example, library sort was first published in 2004). Sorting algorithms are prevalent in introductory computer science classes, where the abundance of algorithms for the problem provides a gentle introduction to a variety of core algorithm concepts, such as big O notation, divide and conquer algorithms, data structures, randomized algorithms, best, worst and average case analysis, time-space tradeoffs, and lower bounds.
Contents |
Classification
Sorting algorithms used in computer science are often classified by:
- Computational complexity (worst, average and best behaviour) of element comparisons in terms of the size of the list
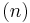 . For typical sorting algorithms good behavior is
. For typical sorting algorithms good behavior is 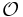
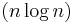 and bad behavior is
and bad behavior is 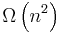 . (See Big O notation) Ideal behavior for a sort is
. (See Big O notation) Ideal behavior for a sort is 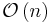 . Comparison sorts, sort algorithms which only access the list via an abstract key comparison operation, always need
. Comparison sorts, sort algorithms which only access the list via an abstract key comparison operation, always need 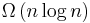 comparisons in the worst case.
comparisons in the worst case. - Computational complexity of swaps (for "in place" algorithms).
- Memory usage (and use of other computer resources). In particular, some sorting algorithms are "in place", such that only
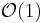 or
or 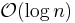 memory is needed beyond the items being sorted, while others need to create auxiliary locations for data to be temporarily stored.
memory is needed beyond the items being sorted, while others need to create auxiliary locations for data to be temporarily stored. - Recursion. Some algorithms are either recursive or non recursive, while others may be both (e.g., merge sort).
- Stability: stable sorting algorithms maintain the relative order of records with equal keys (i.e., values). See below for more information.
- Whether or not they are a comparison sort. A comparison sort examines the data only by comparing two elements with a comparison operator.
- General method: insertion, exchange, selection, merging, etc. Exchange sorts include bubble sort and quicksort. Selection sorts include shaker sort and heapsort.
Stability
Stable sorting algorithms maintain the relative order of records with equal keys (i.e., sort key values). That is, a sorting algorithm is stable if whenever there are two records R and S with the same key and with R appearing before S in the original list, R will appear before S in the sorted list.
When equal elements are indistinguishable, such as with integers, or more generally, any data where the entire element is the key, stability is not an issue. However, assume that the following pairs of numbers are to be sorted by their first component:
(4, 2) (3, 7) (3, 1) (5, 6)
In this case, two different results are possible, one which maintains the relative order of records with equal keys, and one which does not:
(3, 7) (3, 1) (4, 2) (5, 6) (order maintained) (3, 1) (3, 7) (4, 2) (5, 6) (order changed)
Unstable sorting algorithms may change the relative order of records with equal keys, but stable sorting algorithms never do so. Unstable sorting algorithms can be specially implemented to be stable. One way of doing this is to artificially extend the key comparison, so that comparisons between two objects with otherwise equal keys are decided using the order of the entries in the original data order as a tie-breaker. Remembering this order, however, often involves an additional space cost.
Sorting based on a primary, secondary, tertiary, etc. sort key can be done by any sorting method, taking all sort keys into account in comparisons (in other words, using a single composite sort key). If a sorting method is stable, it is also possible to sort multiple times, each time with one sort key. In that case the keys need to be applied in order of increasing priority.
Example: sorting pairs of numbers as above by first, then second component:
(4, 2) (3, 7) (3, 1) (4, 6) (original)
(3, 1) (4, 2) (4, 6) (3, 7) (after sorting by second component) (3, 1) (3, 7) (4, 2) (4, 6) (after sorting by first component)
On the other hand:
(3, 7) (3, 1) (4, 2) (4, 6) (after sorting by first component)
(3, 1) (4, 2) (4, 6) (3, 7) (after sorting by second component,
order by first component is disrupted).
List of sorting algorithms
In this table, n is the number of records to be sorted. The columns "Average" and "Worst" give the time complexity in each case, under the assumption that the length of each key is constant, and that therefore all comparisons, swaps, and other needed operations can proceed in constant time. "Memory" denotes the amount of auxiliary storage needed beyond that used by the list itself, under the same assumption. These are all comparison sorts.
| Name | Average | Worst | Memory | Stable | Method | Other notes |
|---|---|---|---|---|---|---|
| Bubble sort | 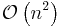 |
|
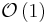 |
Yes | Exchanging | |
| Cocktail sort | — | |
|
Yes | Exchanging | |
| Comb sort | — | — | |
No | Exchanging | Small code size |
| Gnome sort | — | |
|
Yes | Exchanging | Tiny code size |
| Selection sort | |
|
|
No | Selection | Can be implemented as a stable sort |
| Insertion sort | |
|
|
Yes | Insertion | Average case is also 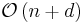 , where d is the number of inversions , where d is the number of inversions |
| Shell sort | — | 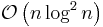 |
|
No | Insertion | |
| Binary tree sort | 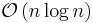 |
|
|
Yes | Insertion | When using a self-balancing binary search tree |
| Library sort | |
|
|
Yes | Insertion | |
| Merge sort | |
|
|
Yes | Merging | |
| In-place merge sort | |
|
|
No | Merging | Example implementation here: [1] |
| Heapsort | |
|
|
No | Selection | |
| Smoothsort | — | |
|
No | Selection | |
| Quicksort | |
|
|
No | Partitioning | Naïve variants use space; can be 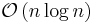 worst case if median pivot is used worst case if median pivot is used |
| Introsort | |
|
|
No | Hybrid | Used in SGI STL implementations |
| Patience sorting | — | 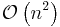 |
|
No | Insertion & Selection | Finds all the longest increasing subsequences within O(n log n) |
| Strand sort | |
|
|
Yes | Selection |
The following table describes sorting algorithms that are not comparison sorts. As such, they are not limited by a lower bound. Complexities below are in terms of n, the number of items to be sorted, k, the size of each key, and s, the chunk size used by the implementation. Many of them are based on the assumption that the key size is large enough that all entries have unique key values, and hence that n << 2k, where << means "much less than."
| Name | Average | Worst | Memory | Stable | n << 2k | Notes |
|---|---|---|---|---|---|---|
| Pigeonhole sort | 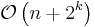 |
|
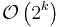 |
Yes | Yes | |
| Bucket sort | 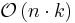 |
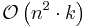 |
|
Yes | No | Assumes uniform distribution of elements from the domain in the array. |
| Counting sort | |
|
|
Yes | Yes | |
| LSD Radix sort | 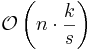 |
|
|
Yes | No | |
| MSD Radix sort | |
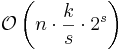 |
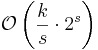 |
No | No | |
| Spreadsort | |
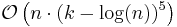 |
|
No | No | Asymptotics are based on the assumption that n << 2k, but the algorithm does not require this. |
The following table describes some sorting algorithms that are impractical for real-life use due to extremely poor performance or a requirement for specialized hardware.
| Name | Average | Worst | Memory | Stable | Comparison | Other notes |
|---|---|---|---|---|---|---|
| Bogosort | 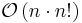 |
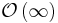 |
|
No | Yes | Average time using Fisher-Yates shuffle |
| Bozo sort | |
|
|
No | Yes | Average time is asymptotically half that of bogosort |
| Stooge sort |  |
|
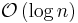 |
No | Yes | |
| Bead sort | N/A | N/A | — | N/A | No | Requires specialized hardware |
| Simple pancake sort | |
|
|
No | Yes | Count is number of flips. |
| Sorting networks | |
|
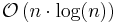 |
Yes | No | Requires a custom circuit of size 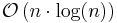 |
Additionally, theoretical computer scientists have detailed other sorting algorithms that provide better than time complexity with additional constraints, including:
- Han's algorithm, a deterministic algorithm for sorting keys from a domain of finite size, taking
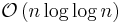 time and
time and 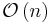 space.[2]
space.[2] - Thorup's algorithm, a randomized algorithm for sorting keys from a domain of finite size, taking time and space.[3]
- An integer sorting algorithm taking
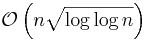 time and space.[4]
time and space.[4]
While theoretically interesting, to date these algorithms have seen little use in practice.
Summaries of popular sorting algorithms
Bubble sort
Bubble sort is a straightforward and simplistic method of sorting data that is used in computer science education. The algorithm starts at the beginning of the data set. It compares the first two elements, and if the first is greater than the second, it swaps them. It continues doing this for each pair of adjacent elements to the end of the data set. It then starts again with the first two elements, repeating until no swaps have occurred on the last pass. While simple, this algorithm is highly inefficient and is rarely used except in education. For example, if we have 100 elements then the total number of comparisons will be 10000. A slightly better variant, cocktail sort, works by inverting the ordering criteria and the pass direction on alternating passes. Its average case and worst case are both O(n²).
Selection sort
Selection sort is a simple sorting algorithm that improves on the performance of bubble sort. It works by first finding the smallest element using a linear scan and swapping it into the first position in the list, then finding the second smallest element by scanning the remaining elements, and so on. Selection sort is unique compared to almost any other algorithm in that its running time is not affected by the prior ordering of the list: it performs the same number of operations because of its simple structure. Selection sort requires (n - 1) swaps and hence Θ(n) memory writes. However, Selection sort requires (n - 1) + (n - 2) + ... + 2 + 1 = n(n - 1) / 2 = Θ(n2) comparisons. Thus selection sort can be very attractive if writes are the most expensive operation, but otherwise it will usually be outperformed by insertion sort or the more complicated algorithms.
Insertion sort
Insertion sort is a simple sorting algorithm that is relatively efficient for small lists and mostly-sorted lists, and often is used as part of more sophisticated algorithms. It works by taking elements from the list one by one and inserting them in their correct position into a new sorted list. In arrays, the new list and the remaining elements can share the array's space, but insertion is expensive, requiring shifting all following elements over by one. The insertion sort works just like its name suggests - it inserts each item into its proper place in the final list. The simplest implementation of this requires two list structures - the source list and the list into which sorted items are inserted. To save memory, most implementations use an in-place sort that works by moving the current item past the already sorted items and repeatedly swapping it with the preceding item until it is in place. Shell sort (see below) is a variant of insertion sort that is more efficient for larger lists. This method is much more efficient than the bubble sort, though it has more constraints.
Shell sort
Shell sort was invented by Donald Shell in 1959. It improves upon bubble sort and insertion sort by moving out of order elements more than one position at a time. One implementation can be described as arranging the data sequence in a two-dimensional array and then sorting the columns of the array using insertion sort. Although this method is inefficient for large data sets, it is one of the fastest algorithms for sorting small numbers of elements (sets with fewer than 1000 or so elements). Another advantage of this algorithm is that it requires relatively small amounts of memory.
Merge sort
Merge sort takes advantage of the ease of merging already sorted lists into a new sorted list. It starts by comparing every two elements (i.e., 1 with 2, then 3 with 4...) and swapping them if the first should come after the second. It then merges each of the resulting lists of two into lists of four, then merges those lists of four, and so on; until at last two lists are merged into the final sorted list. Of the algorithms described here, this is the first that scales well to very large lists, because its worst-case running time is O(n log n).
Heapsort
Heapsort is a much more efficient version of selection sort. It also works by determining the largest (or smallest) element of the list, placing that at the end (or beginning) of the list, then continuing with the rest of the list, but accomplishes this task efficiently by using a data structure called a heap, a special type of binary tree. Once the data list has been made into a heap, the root node is guaranteed to be the largest element. When it is removed and placed at the end of the list, the heap is rearranged so the largest element remaining moves to the root. Using the heap, finding the next largest element takes O(log n) time, instead of O(n) for a linear scan as in simple selection sort. This allows Heapsort to run in O(n log n) time.
Quicksort
Quicksort is a divide and conquer algorithm which relies on a partition operation: to partition an array, we choose an element, called a pivot, move all smaller elements before the pivot, and move all greater elements after it. This can be done efficiently in linear time and in-place. We then recursively sort the lesser and greater sublists. Efficient implementations of quicksort (with in-place partitioning) are typically unstable sorts and somewhat complex, but are among the fastest sorting algorithms in practice. Together with its modest O(log n) space usage, this makes quicksort one of the most popular sorting algorithms, available in many standard libraries. The most complex issue in quicksort is choosing a good pivot element; consistently poor choices of pivots can result in drastically slower O(n²) performance, but if at each step we choose the median as the pivot then it works in O(n log n).
Bucket sort
Bucket sort is a sorting algorithm that works by partitioning an array into a finite number of buckets. Each bucket is then sorted individually, either using a different sorting algorithm, or by recursively applying the bucket sorting algorithm. A variation of this method called the single buffered count sort is faster than the quick sort and takes about the same time to run on any set of data.
Radix sort
Radix sort is an algorithm that sorts a list of fixed-size numbers of length k in O(n · k) time by treating them as bit strings. We first sort the list by the least significant bit while preserving their relative order using a stable sort. Then we sort them by the next bit, and so on from right to left, and the list will end up sorted. Most often, the counting sort algorithm is used to accomplish the bitwise sorting, since the number of values a bit can have is small.
Memory usage patterns and index sorting
When the size of the array to be sorted approaches or exceeds the available primary memory, so that (much slower) disk or swap space must be employed, the memory usage pattern of a sorting algorithm becomes important, and an algorithm that might have been fairly efficient when the array fit easily in RAM may become impractical. In this scenario, the total number of comparisons becomes (relatively) less important, and the number of times sections of memory must be copied or swapped to and from the disk can dominate the performance characteristics of an algorithm. Thus, the number of passes and the localization of comparisons can be more important than the raw number of comparisons, since comparisons of nearby elements to one another happen at system bus speed (or, with caching, even at CPU speed), which, compared to disk speed, is virtually instantaneous.
For example, the popular recursive quicksort algorithm provides quite reasonable performance with adequate RAM, but due to the recursive way that it copies portions of the array it becomes much less practical when the array does not fit in RAM, because it may cause a number of slow copy or move operations to and from disk. In that scenario, another algorithm may be preferable even if it requires more total comparisons.
One way to work around this problem, which works well when complex records (such as in a relational database) are being sorted by a relatively small key field, is to create an index into the array and then sort the index, rather than the entire array. (A sorted version of the entire array can then be produced with one pass, reading from the index, but often even that is unnecessary, as having the sorted index is adequate.) Because the index is much smaller than the entire array, it may fit easily in memory where the entire array would not, effectively eliminating the disk-swapping problem. This procedure is sometimes called "tag sort".[5]
Another technique for overcoming the memory-size problem is to combine two algorithms in a way that takes advantages of the strength of each to improve overall performance. For instance, the array might be subdivided into chunks of a size that will fit easily in RAM (say, a few thousand elements), the chunks sorted using an efficient algorithm (such as quicksort or heapsort), and the results merged as per mergesort. This is less efficient than just doing mergesort in the first place, but it requires less physical RAM (to be practical) than a full quicksort on the whole array.
Techniques can also be combined. For sorting very large sets of data that vastly exceed system memory, even the index may need to be sorted using an algorithm or combination of algorithms designed to perform reasonably with virtual memory, i.e., to reduce the amount of swapping required.
Graphical representations
- A graphical demonstration and thorough discussion of 8 standard sorting algorithms on 4 common initial conditions.
- Hobart and William Smith Colleges has a graphical demonstration of various sorting algorithms. It includes explanations of each step in the sort, plus a timing test. Thus is a good tool for the novice computer science student.
- University of Linköping has a graphical demonstration in their course material.
- The sort algorithm visualizer provides graphical animation of 11 comparison-based sorts in a variety of initial configurations.
- A Java applet visually demonstrates several sorting algorithms.
- Some Java applets showing common comparison-based sorts with colored elements and allowing experimenting with initial conditions. Also calculates some statistics and describes the algorithms.
Microsoft's "Quick" programming languages (such as QuickBASIC and QuickPascal) have a file named "sortdemo" (with extension BAS and PAS for QB and QP, respectively) in the examples folder that provides a graphical representation of several of the various sort procedures described here, as well as performance ratings of each.
See also
- External sorting
- Sorting networks (compare)
- Collation
- Schwartzian transform
- Shuffling algorithms
- Search algorithms
- Wikibooks: Algorithms: Uses sorting a deck of cards with many sorting algorithms as an example
Notes
- ↑ http://www.cs.duke.edu/~ola/papers/bubble.pdf
- ↑ Y. Han. Deterministic sorting in time and linear space. Proceedings of the thiry-fourth annual ACM symposium on Theory of computing, Montreal, Quebec, Canada, 2002,p.602-608.
- ↑ M. Thorup. Randomized Sorting in Time and Linear Space Using Addition, Shift, and Bit-wise Boolean Operations. Journal of Algorithms, Volume 42, Number 2, February 2002 , pp. 205-230(26)
- ↑ Y. Han, M. Thorup, Integer Sorting in Time and Linear Space. Proceedings of the 43rd Symposium on Foundations of Computer Science, 2002, p. 135-144.
- ↑ tag sort Definition
References
- D. E. Knuth, The Art of Computer Programming, Volume 3: Sorting and Searching.
External links
- Sequential and parallel sorting algorithms - has explanations and analyses of many of these algorithms.
- Ricardo Baeza-Yates' sorting algorithms on the Web
- 'Dictionary of Algorithms, Data Structures, and Problems'
- Slightly Skeptical View on Sorting Algorithms Softpanorama page that discusses several classic algorithms and promotes alternatives to quicksort.
- Sorting Revisited
- For a repository of algorithms with source code and lectures, see The Stony Brook Algorithm Repository
- Graphical Java illustrations of the Bubble sort, Insertion sort, Quicksort, and Selection sort
- xSortLab - An interactive Java demonstration of Bubble, Insertion, Quick, Select and Merge sorts, which displays the data as a bar graph with commentary on the workings of the algorithm printed below the graph.
- Sorting contest - An applet visually demonstrating a contest between a number of different sorting algorithms
- (Italian) Java Applet that show some sorting algorithms
- The Three Dimensional Bubble Sort- A method of sorting in three or more dimensions (of questionable merit)
- Sort huge amounts of data by doing a multi-phase sorting on temporary file
- AniSort - Java applet visualizing 6 different sorting algorithms
- Pointers to sorting visualizations
- Monkey Sort discussion (another name for Bozo-sort)
- Extensive collection of animated sorting algorithms with source code.
- Several sorting algorithms demonstrated in Java
- OPL booklet of the main sorting algorithms by Michael Lamont
- QiSort - A new O(n log n) algorithm for 2007
- Sorting algorithm demonstrations with source code "tracing"
|
||||||||||||||||||||||||||||