Inverse function

In mathematics, if ƒ is a function from A to B then an inverse function for ƒ is a function in the opposite direction, from B to A, with the property that a round trip (a composition) from A to B to A (or from B to A to B) returns each element of the initial set to itself. Thus, if an input x into the function ƒ produces an output y, then inputting y into the inverse function ƒ–1 (read f inverse, not to be confused with exponentiation) produces the output x. Not every function has an inverse; those that do are called invertible.
For example, let ƒ be the function that converts a temperature in degrees Celsius to a temperature in degrees Fahrenheit:
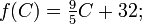
then its inverse function converts degrees Fahrenheit to degrees Celsius:
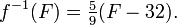
Or, suppose ƒ assigns each child in a family of three the year of its birth. An inverse function would tell us which child was born in a given year. However, if the family has twins (or triplets) then we cannot know which to name for their common birth year. As well, if we are given a year in which no child was born then we cannot name a child. But if each child was born in a separate year, and if we restrict attention to the three years in which a child was born, then we do have an inverse function. For example,

Contents |
Definitions

Let ƒ be a function whose domain is the set X, and whose range is the set Y. Then, if it exists, the inverse of ƒ is the function ƒ–1 with domain Y and range X, defined by the following rule:

Stated otherwise, a function is invertible if and only if its inverse relation is a function, in which case the inverse relation is the inverse function: the inverse relation is the relation obtained by switching x and y everywhere.
Thus, an inverse function uniquely identifies the input x of another function based only on its output y, for all y ∈ Y. A function is invertible if and only if this rule defines a function. Not all functions have an inverse. For this rule to be applicable, each element y ∈ Y must correspond to exactly one element x ∈ X. This is generally stated as two conditions:
- Every
 corresponds to no more than one
corresponds to no more than one 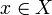 ; a function ƒ with this property is called one-to-one, or information-preserving, or an injection.
; a function ƒ with this property is called one-to-one, or information-preserving, or an injection. - Every corresponds to at least one ; a function ƒ with this property is called onto, or a surjection.
In elementary mathematics, the domain is often assumed to be the real numbers, if not otherwise specified, and the range is assumed to be the image.
Most functions encountered in elementary calculus do not have an inverse.[1]
Example: square root
The function ƒ(x) = y = x2 may or may not be invertible, depending on the domain and codomain.
If the domain is the real numbers, then each element in Y would correspond to two different elements in X (±x), and therefore ƒ would not be invertible. More precisely, the square of x is not invertible because it is impossible to deduce from its output the sign of its input. Such a function is called non-injective or information-losing. Notice that neither the square root nor the principal square root function is the inverse of x2 because the first is not single-valued, and the second returns -x when x is negative.
If the domain and codomain are both the non-negative numbers, then it is invertible, by the principal square root.
If the domain is the non-negative numbers, but the codomain is all reals, then again, it is not invertible, because negative numbers are not squares of a real number.
Inverses in higher mathematics
The definition given above is commonly adopted in calculus. In higher mathematics, the notation
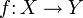
means "ƒ is a function mapping elements of a set X to elements of a set Y". The source, X, is called the domain of ƒ, and the target, Y, is called the codomain. The codomain contains the range of ƒ as a subset, and is considered part of the definition of ƒ.
When using codomains, the inverse of a function ƒ: X → Y is required to have domain Y and codomain X. For the inverse to be defined on all of Y, every element of Y must lie in the range of the function ƒ. A function with this property is called onto or a surjection. Thus, a function with a codomain is invertible if and only if it is both one-to-one and onto. Such a function is called a one-to-one correspondence or a bijection, and has the property that every element y ∈ Y corresponds to exactly one element x ∈ X.
Inverses and composition
If ƒ is an invertible function with domain X and range Y, then

This statement is equivalent to the first of the above-given definitions of the inverse, and it becomes equivalent to the second definition if Y coincides with the codomain of ƒ. Using the composition of functions we can rewrite this statement as follows:

where idX is the identity function on the set X. In category theory, this statement is used as the definition of an inverse morphism.
If we think of composition as a kind of multiplication of functions, this identity says that the inverse of a function is analogous to a multiplicative inverse. This explains the origin of the notation ƒ–1.
Note on notation
The superscript notation for inverses can sometimes be confused with other uses of superscripts, especially when dealing with trigonometric and hyperbolic functions.
It is important to realize that ƒ–1(x) is not the same as ƒ(x)–1. In ƒ−1(x), the superscript "−1" is not an exponent. A similar notation is used in dynamical systems for iterated functions. For example, ƒ2 denotes two iterations of the function ƒ; if ƒ(x) = x + 1, then ƒ2(x) = (x + 1) + 1, or x + 2. In symbols:

In calculus, ƒ(n), with parentheses, denotes the nth derivative of a function ƒ. For instance:
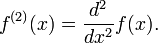
In trigonometry, for historical reasons, sin2(x) usually does mean the square of sin(x):
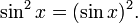
However, the expression sin-1(x) does not represent the multiplicative inverse to sin(x):
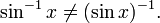
It denotes the inverse function for sin(x) (actually a partial inverse; see below). To avoid confusion, an inverse trigonometric function is often indicated by the prefix "arc". For instance the inverse sine is typically called the arcsine:
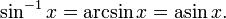
The function (sin x)–1 is the multiplicative inverse to the sine, and is called the cosecant. It is usually denoted csc x:
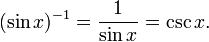
Properties
Uniqueness
If an inverse function exists for a given function ƒ, it is unique: it must be the inverse relation.
Symmetry
There is a symmetry between a function and its inverse. Specifically, if the inverse of ƒ is ƒ–1, then the inverse of ƒ–1 is the original function ƒ. In symbols:

This follows because invertion of relations is an involution: if you repeat it, you get back to where you started.
This statement is an obvious consequence of the above-explained deduction that, for ƒ to be invertible, it must be injective (first definition of the inverse) or bijective (second definition). The property of symmetry can be concisely expressed by the following formula:
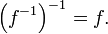
Inverse of a composition

The inverse of a composition of functions is given by the formula

Notice that the order of ƒ and g have been reversed; to undo g followed by ƒ, we must first undo ƒ and then undo g.
For example, let ƒ(x) = x + 5, and let g(x) = 3x. Then the composition ƒ o g is the function that first multiplies by three and then adds five:
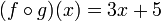
To reverse this process, we must first subtract five, and then divide by three:
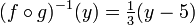
This is the composition (g–1 o ƒ–1) (y).
Self-inverses
If X is a set, then the identity function on X is its own inverse:
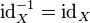
More generally, a function ƒ: X → X is equal to its own inverse if and only if the composition ƒ o ƒ is equal to idx. Such a function is called an involution.
Inverses in calculus
Single-variable calculus is primarily concerned with functions that map real numbers to real numbers. Such functions are often defined through formulas, such as:
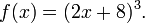
A function ƒ from the real numbers to the real numbers possesses an inverse as long as it is one-to-one, i.e. as long as the graph of the function passes the horizontal line test.
The following table shows several standard functions and their inverses:
-
Function ƒ(x) Inverse ƒ–1(y) Notes x + a y – a a – x a – y mx y / m m ≠ 0 1 / x 1 / y x, y ≠ 0 x2 
x, y ≥ 0 only x3 ![\sqrt[3]{y}](/2009-wikipedia_en_wp1-0.7_2009-05/I/f618f2509ef261b8ef52b213392a7f43.png)
no restriction on x and y xp y1/p (i.e. ![\sqrt[p]{y}](/2009-wikipedia_en_wp1-0.7_2009-05/I/11d051d6c0c42d663c040eeb85ed6e65.png) )
)x, y ≥ 0 in general, p ≠ 0 ex ln y y > 0 ax loga y y > 0 and a > 0 trigonometric functions inverse trigonometric functions various restrictions (see table below)
Formula for the inverse
One approach to finding a formula for ƒ–1, if it exists, is to solve the equation y = ƒ(x) for x. For example, if ƒ is the function
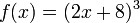
then we must solve the equation y = (2x + 8)3 for x:
![\begin{align}
y & = (2x+8)^3 \\
\sqrt[3]{y} & = 2x + 8 \\
\sqrt[3]{y} - 8 & = 2x \\
\dfrac{\sqrt[3]{y} - 8}{2} & = x .
\end{align}](/2009-wikipedia_en_wp1-0.7_2009-05/I/ed59e6fab74420ddb7abe1b3d39e3c25.png)
Thus the inverse function ƒ–1 is given by the formula
![f^{-1}(y) = \dfrac{\sqrt[3]{y} - 8}{2} . \,\!](/2009-wikipedia_en_wp1-0.7_2009-05/I/aa2a8fea953c0bf7437ab677eda3cf92.png)
Sometimes the inverse of a function cannot be expressed by a formula. For example, if ƒ is the function
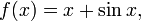
then ƒ is one-to-one, and therefore possesses an inverse function ƒ–1. There is no simple formula for this inverse, since the equation y = x + sin x cannot be solved algebraically for x.
Graph of the inverse

If ƒ and ƒ–1 are inverses, then the graph of the function
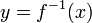
is the same as the graph of the equation
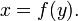
This is identical to the equation y = ƒ(x) that defines the graph of ƒ, except that the roles of x and y have been reversed. Thus the graph of ƒ–1 can be obtained from the graph of ƒ by switching the positions of the x and y axes. This is equivalent to reflecting the graph across the line y = x.
Inverses and derivatives
A continuous function ƒ is one-to-one (and hence invertible) if and only if it is either strictly increasing or decreasing (with no local maxima or minima). For example, the function
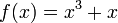
is invertible, since the derivative ƒ′(x) = 3x2 + 1 is always positive.
If the function ƒ is differentiable, then the inverse ƒ–1 will be differentiable as long as ƒ′(x) ≠ 0. The derivative of the inverse is given by the inverse function theorem:
![\frac{d}{dy}\left[ f^{-1}(y) \right] = \frac{1}{f'\left(f^{-1}(y)\right)} .](/2009-wikipedia_en_wp1-0.7_2009-05/I/58f263cb5573d01d1083bd75faec9bf4.png)
If we set x = ƒ–1(y), then the formula above can be written

This result follows from the chain rule (see the article on inverse functions and differentiation).
The inverse function theorem can be generalized to functions of several variables. Specifically, a differentiable function ƒ: Rn → Rn is invertible in a neighborhood of a point p as long as the Jacobian matrix of ƒ at p is invertible. In this case, the Jacobian of ƒ–1 at ƒ(p) is the matrix inverse of the Jacobian of ƒ at p.
Generalizations
Partial inverses

Even if a function ƒ is not one-to-one, it may be possible to define a partial inverse of ƒ by restricting the domain. For example, the function

is not one-to-one, since x2 = (–x)2. However, the function becomes one-to-one if we restrict to the domain x ≥ 0, in which case
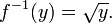
(If we instead restrict to the domain x ≤ 0, then the inverse is the negative of the square root of x.) Alternatively, there is no need to restrict the domain if we are content with the inverse being a multivalued function:


Sometimes this multivalued inverse is called the full inverse of ƒ, and the portions (such as √x and −√x) are called branches. The most important branch of a multivalued function (e.g. the positive square root) is called the principal branch, and its value at y is called the principal value of ƒ–1(y).
For a continuous function on the real line, one branch is required between each pair of local extrema. For example, the inverse of a cubic function with a local maximum and a local minimum has three branches (see the picture to the right).

These considerations are particularly important for defining the inverses of trigonometric functions. For example, the sine function is not one-to-one, since
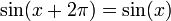
for every real x (and more generally sin(x + 2πn) = sin(x) for every integer n). However, the sine is one-to-one on the interval [–π⁄2, π⁄2], and the corresponding partial inverse is called the arcsine. This is considered the principal branch of the inverse sine, so the principal value of the inverse sine is always between –π⁄2 and π⁄2. The following table describes the principal branch of each inverse trigonometric function:
-
function Range of usual principal value sin–1 –π⁄2 ≤ sin–1(x) ≤ π⁄2 cos–1 0 ≤ cos–1(x) ≤π tan–1 –π⁄2 < tan–1(x) < π⁄2 cot–1 0 < cot–1(x) < π sec–1 0 < sec–1(x) < π csc–1 −π⁄2 ≤ csc–1(x) < π⁄2
Left and right inverses
If ƒ: X → Y, a left inverse for ƒ (or retraction of ƒ) is a function g: Y → X such that
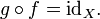
That is, the function g satisfies the rule
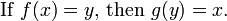
Thus, g must equal the inverse of ƒ on the range of ƒ, but may take any values for elements of Y not in the range. A function ƒ has a left inverse if and only if it is injective.
A right inverse for ƒ (or section of ƒ) is a function h: Y → X such that
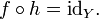
That is, the function h satisfies the rule
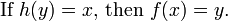
Thus, h(y) may be any of the elements of x that map to y under ƒ. A function ƒ has a right inverse if and only if it is surjective (though constructing such an inverse in general requires the axiom of choice).
An inverse which is both a left and right inverse must be unique; otherwise not. Likewise, if g is a left inverse for ƒ then ƒ may not be a right inverse for g; and if ƒ is a right inverse for g then g is not necessarily a left inverse for ƒ.
Preimages
If ƒ: X → Y is any function (not necessarily invertible), the preimage (or inverse image) of an element y ∈ Y is the set of all elements of X that map to y:
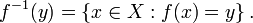
The preimage of y can be thought of as the image of y under the (multivalued) full inverse of the function f.
Similarly, if S is any subset of Y, the preimage of S is the set of all elements of X that map to S:

The preimage of a single element y ∈ Y is sometimes called the fiber of y. When Y is the set of real numbers, it is common to refer to ƒ–1(y) as a level set.
See also
- Inverse trigonometric function
- Logarithm
- Inverse function theorem
- Inverse functions and differentiation
- Inverse relation
- Inverse element
References
- ↑ Smith, William K. Inverse Functions, MacMillan, 1966 (p. 60).
Bibliography
- Stewart, James (2002), Calculus (5th ed.), Brooks Cole, ISBN 978-0534393397