Insertion sort
| Insertion sort | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|
 |
||||||||||
| General Data | ||||||||||
|
Insertion sort is a simple sorting algorithm, a comparison sort in which the sorted array (or list) is built one entry at a time. It is much less efficient on large lists than more advanced algorithms such as quicksort, heapsort, or merge sort. However, insertion sort provides several advantages:
- simple implementation
- efficient for (quite) small data sets
- efficient for data sets that are already substantially sorted: the time complexity is O(n + d), where d is the number of inversions
- more efficient in practice than most other simple quadratic (i.e., O(n2)) algorithms such as selection sort or bubble sort: the average running time is n2/4, and the running time is linear in the best case
- stable (i.e., does not change the relative order of elements with equal keys)
- in-place (i.e., only requires a constant amount O(1) of additional memory space)
- online (i.e., can sort a list as it receives it)
Most humans when sorting—ordering a deck of cards, for example—use a method that is similar to insertion sort.
Contents |
Algorithm
In abstract terms, every iteration of insertion sort removes an element from the input data, inserting it into the correct position in the already-sorted list, until no input elements remain. The choice of which element to remove from the input is arbitrary, and can be made using almost any choice algorithm.
Sorting is typically done in-place. The resulting array after k iterations has the property where the first k entries are sorted. In each iteration the first remaining entry of the input is removed, inserted into the result at the correct position, thus extending the result:

becomes
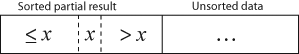
with each element greater than x copied to the right as it is compared against x.
The most common variant of insertion sort, which operates on arrays, can be described as follows:
- Suppose there exists a function called Insert designed to insert a value into a sorted sequence at the beginning of an array. It operates by beginning at the end of the sequence and shifting each element one place to the right until a suitable position is found for the new element. The function has the side effect of overwriting the value stored immediately after the sorted sequence in the array.
- To perform an insertion sort, begin at the left-most element of the array and invoke Insert to insert each element encountered into its correct position. The ordered sequence into which the element is inserted is stored at the beginning of the array in the set of indices already examined. Each insertion overwrites a single value: the value being inserted.
Pseudocode of the complete algorithm follows, where the arrays are zero-based and the for-loop includes both the top and bottom limits (as in Pascal):
insertionSort(array A) begin for i := 1 to length[A]-1 do begin value := A[i]; j := i-1; while j ≥ 0 and A[j] > value do begin A[j + 1] := A[j]; j := j-1; end; A[j+1] := value; end; end;
Best, worst, and average cases
The best case input is an array that is already sorted. In this case insertion sort has a linear running time (i.e., O(n)). During each iteration, the first remaining element of the input is only compared with the right-most element of the sorted subsection of the array.
The worst case input is an array sorted in reverse order. In this case every iteration of the inner loop will scan and shift the entire sorted subsection of the array before inserting the next element. For this case insertion sort has a quadratic running time (i.e., O(n2)).
The average case is also quadratic, which makes insertion sort impractical for sorting large arrays. However, insertion sort is one of the fastest algorithms for sorting arrays containing less than ten elements.
Comparisons to other sorting algorithms
Insertion sort is very similar to selection sort. As in selection sort, after k passes through the array, the first k elements are in sorted order. For selection sort these are the k smallest elements, while in insertion sort they are whatever the first k elements were in the unsorted array. Insertion sort's advantage is that it only scans as many elements as needed to determine the correct location of the k+1th element, while selection sort must scan all remaining elements to find the absolute smallest element.
Calculations show that insertion sort will usually perform about half as many comparisons as selection sort. Assuming the k+1th element's rank is random, insertion sort will on average require shifting half of the previous k elements, while selection sort always requires scanning all unplaced elements. If the input array is reverse-sorted, insertion sort performs as many comparisons as selection sort. If the input array is already sorted, insertion sort performs as few as n-1 comparisons, thus making insertion sort more efficient when given sorted or "nearly-sorted" arrays.
While insertion sort typically makes fewer comparisons than selection sort, it requires more writes because the inner loop can require shifting large sections of the sorted portion of the array. In general, insertion sort will write to the array O(n2) times, whereas selection sort will write only O(n) times. For this reason selection sort may be preferable in cases where writing to memory is significantly more expensive than reading, such as with EEPROM or flash memory.
Some divide-and-conquer algorithms such as quicksort and mergesort sort by recursively dividing the list into smaller sublists which are then sorted. A useful optimization in practice for these algorithms is to use insertion sort for sorting small sublists, as insertion sort outperforms these more complex algorithms. The size of list for which insertion sort has the advantage varies by environment and implementation, but is typically between eight and twenty elements.
Variants
D.L. Shell made substantial improvements to the algorithm; the modified version is called Shell sort. The sorting algorithm compares elements separated by a distance that decreases on each pass. Shell sort has distinctly improved running times in practical work, with two simple variants requiring O(n3/2) and O(n4/3) running time.
If the cost of comparisons exceeds the cost of swaps, as is the case for example with string keys stored by reference or with human interaction (such as choosing one of a pair displayed side-by-side), then using binary insertion sort may yield better performance. Binary insertion sort employs a binary search to determine the correct location to insert new elements, and therefore performs 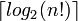 comparisons in the worst case, which is Θ(n log n). The algorithm as a whole still has a running time of Θ(n2) on average because of the series of swaps required for each insertion the use of a binary search. The best-case running time is is no longer Ω(n), but Ω(n log n).
comparisons in the worst case, which is Θ(n log n). The algorithm as a whole still has a running time of Θ(n2) on average because of the series of swaps required for each insertion the use of a binary search. The best-case running time is is no longer Ω(n), but Ω(n log n).
To avoid having to make a series of swaps for each insertion, the input could be stored in a linked list, which allows elements to be inserted and deleted in constant-time. However, performing a binary search on a linked list is impossible because a linked list does not support random access to its elements; therefore, the running time required for searching is O(n2). If a more sophisticated data structure (e.g., heap or binary tree) is used, the time required for searching and insertion can be reduced significantly; this is the essence of heap sort and binary tree sort.
In 2004 Bender, Farach-Colton, and Mosteiro published a new variant of insertion sort called library sort or gapped insertion sort that leaves a small number of unused spaces (i.e., "gaps") spread throughout the array. The benefit is that insertions need only shift elements over until a gap is reached. The authors show that this sorting algorithm runs with high probability in O(n log n) time. [1]
External links
- Animated Sorting Algorithms: Insertion Sort – graphical demonstration and discussion of insertion sort
- Category:Insertion Sort - LiteratePrograms – implementations of insertion sort in various programming languages
- InsertionSort – colored, graphical Java applet that allows experimentation with the initial input and provides statistics
- Insertion Sort Demonstration – an animated Java applet showing a step-by-step insertion sort
- Sorting Algorithms Demo – visual demonstrations of sorting algorithms (implemented in Java)
- TIDE 2.0 beta – analyze insertion sort in an online Javascript IDE
- Sorting Algorithms in Turkish
References
- Donald Knuth. The Art of Computer Programming, Volume 3: Sorting and Searching, Second Edition. Addison-Wesley, 1998. ISBN 0-201-89685-0. Section 5.2.1: Sorting by Insertion, pp.80–105.
- Thomas H. Cormen, Charles E. Leiserson, Ronald L. Rivest, and Clifford Stein. Introduction to Algorithms, Second Edition. MIT Press and McGraw-Hill, 2001. ISBN 0-262-03293-7. Section 2.1: Insertion sort, pp.15–21.
|
||||||||||||||||||||||||||||