Degrees of freedom (statistics)
- For other senses of these terms, see degrees of freedom or degree.
In statistics, the phrase degrees of freedom is used to describe the number of values in the final calculation of a statistic that are free to vary.[1]
Estimates of statistical parameters can be based upon different amounts of information or data. The number of independent pieces of information that go into the estimate of a parameter is called the degrees of freedom (df). In general, the degrees of freedom of an estimate is equal to the number of independent scores that go into the estimate minus the number of parameters estimated as intermediate steps in the estimation of the parameter itself.[2]
Mathematically, degrees of freedom is the dimension of the domain of a random vector, or essentially the number of 'free' components: how many components need to be known before the vector is fully determined.
The term is most often used in the context of linear models (linear regression, Analysis of Variance), where certain random vectors are constrained to lie in linear subspaces, and the degrees of freedom is the dimension of the subspace. The degrees-of-freedom are also commonly associated with the squared lengths (or “Sum of Squares”) of such vectors, and the parameters of chi-squared and other distributions that arise in associated statistical testing problems.
While introductory texts may introduce degrees of freedom as distribution parameters or through hypothesis testing, it is the underlying geometry that defines degrees of freedom, and is critical to a proper understanding of the concept. Walker (1940)[3] has stated this succinctly:
- For the person who is unfamiliar with N-dimensional geometry or who knows the contributions to modern sampling theory only from secondhand sources such as textbooks, this concept often seems almost mystical, with no practical meaning.
Contents |
Notation
In equations, the typical symbol for degrees of freedom is  (lowercase Greek letter nu). In text and tables, the abbreviation "d.f." is commonly used. R.A. Fisher used n to symbolize degrees of freedom (writing
(lowercase Greek letter nu). In text and tables, the abbreviation "d.f." is commonly used. R.A. Fisher used n to symbolize degrees of freedom (writing 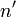 for sample size) but modern usage typically reserves n for sample size.
for sample size) but modern usage typically reserves n for sample size.
Residuals
A common way to think of degrees of freedom is as the number of independent pieces of information available to estimate another piece of information. More concretely, the number of degrees of freedom is the number of independent observations in a sample of data that are available to estimate a parameter of the population from which that sample is drawn. For example, if we have two observations, when calculating the mean we have two independent observations; however, when calculating the variance, we have only one independent observation, since the two observations are equally distant from the mean.
In fitting statistical models to data, the vectors of residuals are constrained to lie in a space of smaller dimension than the number of components in the vector. That smaller dimension is the number of degrees of freedom for error.
Linear regression
Perhaps the simplest example is this. Suppose
are random variables each with expected value μ, and let
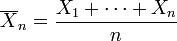
be the "sample mean". Then the quantities
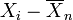
are residuals that may be considered estimates of the errors Xi − μ. The sum of the residuals (unlike the sum of the errors) is necessarily 0. If one knows the values of any n − 1 of the residuals, one can thus find the last one. That means they are constrained to lie in a space of dimension n − 1. One says that "there are n − 1 degrees of freedom for error."
An only slightly less simple example is that of least squares estimation of a and b in the model
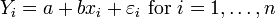
where εi, and hence Yi are random. Let 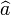 and
and 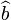 be the least-squares estimates of a and b. Then the residuals
be the least-squares estimates of a and b. Then the residuals
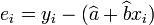
are constrained to lie within the space defined by the two equations
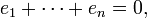
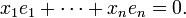
One says that there are n − 2 degrees of freedom for error.
The capital Y is used in specifying the model, and lower-case y in the definition of the residuals. That is because the former are hypothesized random variables and the latter are data.
We can generalise this to multiple regression involving p parameters and covariates (e.g. p − 1 predictors and one mean), in which case the cost in degrees of freedom of the fit is p.
Degrees of freedom of a random vector
Geometrically, the degrees of freedom can be interpreted as the dimension of certain vector subspaces. As a starting point, suppose that we have a sample of n independent normally distributed observations,
 .
.
This can be represented as an n-dimensional random vector:
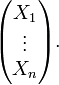
Since this random vector can lie anywhere in n-dimensional space, it has n degrees of freedom.
Now, let 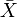 be the sample mean. The random vector can be decomposed as the sum of the sample mean plus a vector of residuals:
be the sample mean. The random vector can be decomposed as the sum of the sample mean plus a vector of residuals:
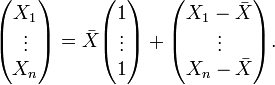
The first vector on the right-hand side is constrained to be a multiple of the vector of 1's, and the only free quantity is . It therefore has 1 degree of freedom.
The second vector is constrained by the relation  . The first n − 1 components of this vector can be anything. However, once you know the first n − 1 components, the constraint tells you the value of the nth component. Therefore, this vector has n − 1 degrees of freedom.
. The first n − 1 components of this vector can be anything. However, once you know the first n − 1 components, the constraint tells you the value of the nth component. Therefore, this vector has n − 1 degrees of freedom.
Mathematically, the first vector is the orthogonal, or least-squares, projection of the data vector onto the subspace spanned by the vector of 1's. The 1 degree of freedom is the dimension of this subspace. The second residual vector is the least-squares projection onto the (n − 1)-dimensional orthogonal complement of this subspace, and has n − 1 degrees of freedom.
In statistical testing applications, often one isn't directly interested in the component vectors, but rather in their squared lengths. In the example above, the residual sum-of-squares is
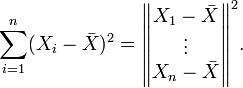
If the data points 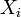 are normally distributed with mean 0 and variance
are normally distributed with mean 0 and variance  , then the residual sum of squares has a scaled chi-squared distribution (scaled by the factor ), with n − 1 degrees of freedom. The degrees-of-freedom, here a parameter of the distribution, can still be interpreted as the dimension of an underlying vector subspace.
, then the residual sum of squares has a scaled chi-squared distribution (scaled by the factor ), with n − 1 degrees of freedom. The degrees-of-freedom, here a parameter of the distribution, can still be interpreted as the dimension of an underlying vector subspace.
Likewise, the one-sample t-test statistic,
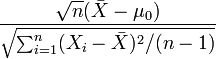
follows a Student's t distribution with n − 1 degrees of freedom when the hypothesized mean 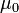 is correct. Again, the degrees-of-freedom arises from the residual vector in the denominator.
is correct. Again, the degrees-of-freedom arises from the residual vector in the denominator.
Degrees of freedom in linear models
The demonstration of the t and chi-squared distributions for one-sample problems above is the simplest example where degrees-of-freedom arise. However, similar geometry and vector decompositions underly much of the theory of linear models, including linear regression and analysis of variance. An explicit example based on comparison of three means is presented here; the geometry of linear models is discussed in more complete detail by Christensen (2002).[4]
Suppose independent observations are made for three populations,  ,
,  and
and 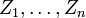 . The restriction to three groups and equal sample sizes simplifies notation, but the ideas are easily generalized.
. The restriction to three groups and equal sample sizes simplifies notation, but the ideas are easily generalized.
The observations can be decomposed as
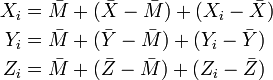
where 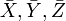 are the means of the individual samples, and
are the means of the individual samples, and 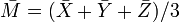 is the mean of all 3n observations. In vector notation this decomposition can be written as
is the mean of all 3n observations. In vector notation this decomposition can be written as
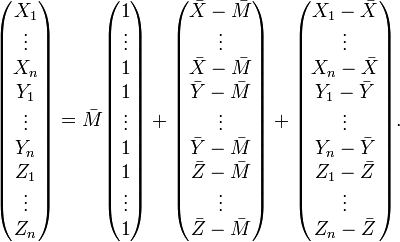
The observation vector, on the left-hand side, has 3n degrees of freedom. On the right-hand side, the first vector has one degree of freedom (or dimension) for the overall mean. The second vector depends on three random variables, 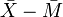 ,
, 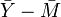 and
and  . However, these must sum to 0 and so are constrained; the vector therefore must lie in a 2-dimensional subspace, and has 2 degrees of freedom. The remaining 3n − 3 degrees of freedom are in the residual vector (made up of n − 1 degrees of freedom within each of the populations).
. However, these must sum to 0 and so are constrained; the vector therefore must lie in a 2-dimensional subspace, and has 2 degrees of freedom. The remaining 3n − 3 degrees of freedom are in the residual vector (made up of n − 1 degrees of freedom within each of the populations).
Sum of squares and degrees of freedom
In statistical testing problems, one usually isn't interested in the component vectors themselves, but rather in their squared lengths, or Sum of Squares. The degrees of freedom associated with a sum-of-squares is the degrees-of-freedom of the corresponding component vectors.
The three-population example above is an example of one-way Analysis of Variance. The model, or treatment, sum-of-squares is the squared length of the second vector,
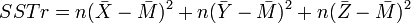
with 2 degrees of freedom. The residual, or error, sum-of-squares is

with 3(n-1) degrees of freedom. Of course, introductory books on ANOVA usually state formulae without showing the vectors, but it is this underlying geometry that gives rise to SS formulae, and shows how to unambiguously determine the degrees of freedom in any given situation.
Under the null hypothesis of no difference between population means (and assuming that standard ANOVA regularity assumptions are satisfied) the sums of squares have scaled chi-squared distributions, with the corresponding degrees of freedom. The F-test statistic is the ratio, after scaling by the degrees of freedom. If there is no difference between population means this ratio follows an F distribution with 2 and 3n − 3 degrees of freedom.
In some complicated settings, such as unbalanced split-plot designs, the sums-of-squares no longer have scaled chi-squared distributions. Comparison of sum-of-squares with degrees-of-freedom is no longer meaningful, and software may report certain fractional 'degrees of freedom' in these cases. Such numbers have no genuine degrees-of-freedom interpretation, but are simply providing an approximate chi-squared distribution for the corresponding sum-of-squares. The details of such approximations are beyond the scope of this page.
Degrees of freedom parameters in probability distributions
Several commonly encountered statistical distributions (Student's t, Chi-Squared, F) have parameters that are commonly referred to as degrees of freedom. This terminology simply reflects that in many applications where these distributions occur, the parameter corresponds to the degrees of freedom of an underlying random vector, as in the preceding ANOVA example. Another simple example is: if 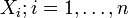 are independent normal
are independent normal  random variables, the statistic
random variables, the statistic
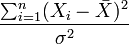
follows a chi-squared distribution with n−1 degrees of freedom. Here, the degrees of freedom arises from the residual sum-of-squares in the numerator, and in turn the n−1 degrees of freedom of the underlying residual vector  .
.
In the application of these distributions to linear models, the degrees of freedom parameters can take only integer values. The underlying families of distributions allow fractional values for the degrees-of-freedom parameters, which can arise in more sophisticated uses. One set of examples is problems where chi-squared approximations based on effective degrees of freedom are used. In other applications, such as modelling heavy-tailed data, a t or F distribution may be used as an empirical model. In these cases, there is no particular degrees of freedom interpretation to the distribution parameters, even though the terminology may continue to be used.
Effective degrees of freedom
Many regression methods, including ridge regression, linear smoothers and smoothing splines are not based on least-squares projections, and so degrees of freedom defined in terms of dimensionality is generally not useful for these procedures. However, these procedures are still linear in the observations, and the fitted values of the regression can be expressed in the form

where 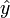 is the vector of fitted values at each of the original covariate values from the fitted model, y is the original vector of responses, and H is the hat matrix.
is the vector of fitted values at each of the original covariate values from the fitted model, y is the original vector of responses, and H is the hat matrix.
For statistical inference, sums-of-squares can still be formed: the model sum-of-squares is 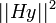 ; the residual sum-or-squares is
; the residual sum-or-squares is 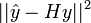 . However, because H does not correspond to a least-squares fit (i.e. is not an orthogonal projection), these sums-of-squares no longer have (scaled, non-central) chi-squared distributions, and geometrically-defined degrees-of-freedom are not useful.
. However, because H does not correspond to a least-squares fit (i.e. is not an orthogonal projection), these sums-of-squares no longer have (scaled, non-central) chi-squared distributions, and geometrically-defined degrees-of-freedom are not useful.
The effective degrees of freedom of the fit can be defined in various ways to implement goodness-of-fit tests, cross-validation and other inferential procedures. Depending on the procedure, appropriate definitions can include the trace of the 'hat' matrix, tr(H)), tr(H'H), or the Satterthwaite Approximation degrees of freedom,  . In the case of linear regression, the hat matrix X(X'X)-1X' , and all these definitions reduce to the usual degrees of freedom.
. In the case of linear regression, the hat matrix X(X'X)-1X' , and all these definitions reduce to the usual degrees of freedom.
There are corresponding definitions of residual effective degrees-of-freedom, with H replaced by I − H. For example, if the goal is to estimate error variance, the rdf would be defined as tr((I − H)'(I − H)), and the unbiased estimate is
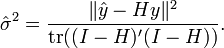
Note that unlike in the original case, we allow non-integer degrees of freedom, though the value must usually still be constrained between 0 and n.
Consider, as an example, the k-nearest neighbour smoother, which is the average of the k nearest measured values to the given point. Then, at each of the n measured points, the weight of the original value on the linear combination that makes up the predicted value is just 1/k. Thus, the trace of the hat matrix is n/k. Thus the smooth costs n/k effective degrees of freedom.
See also
- True variance
- Sample size
- Replication (statistics)
External links
- Walker, HW (1940) "Degrees of Freedom" Journal of Educational Psychology 31(4) 253-269. Transcription by C Olsen with errata
- Good, IJ (1973). "What Are Degrees of Freedom?". The American Statistician 27 (5): 227–228.
- Yu, Chong-ho (1997) Illustrating degrees of freedom in terms of sample size and dimensionality
- Dallal, GE. (2003) Degrees of Freedom
References
- ↑ ""Glossary of Statistical Terms"". Animated Software. Retrieved on 2008-08-21.
- ↑ ""HyperStat Online"". Statistics Solutions. Retrieved on 2008-08-21.
- ↑ Walker, H. M. (1940). "Degrees of Freedom". Journal of Educational Psychology 31 (4): 253-269.
- ↑ Christensen, Ronald (2002). Plane Answers to Complex Questions (Third Edition ed.). Springer. ISBN 0-387-93561-2.
|
|||||||||||||||||||||||||||||||||||||||||||||||||||