Characteristic function (probability theory)
In probability theory, the characteristic function of any random variable completely defines its probability distribution. On the real line it is given by the following formula, where X is any random variable with the distribution in question:
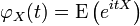
where t is a real number, i is the imaginary unit, and E denotes the expected value.
If FX is the cumulative distribution function, then the characteristic function is given by the Riemann-Stieltjes integral
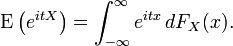
In cases in which there is a probability density function, fX, this becomes
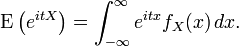
If X is a vector-valued random variable, one takes the argument t to be a vector and tX to be a dot product.
Every probability distribution on R or on Rn has a characteristic function, because one is integrating a bounded function over a space whose measure is finite, and for every characteristic function there is exactly one probability distribution.
The characteristic function of a symmetric PDF (that is, one with 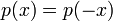 ) is real, because the imaginary components obtained from
) is real, because the imaginary components obtained from 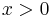 cancel those from
cancel those from 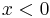 .
.
Contents |
Lévy continuity theorem
The core of the Lévy continuity theorem states that a sequence of random variables 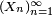 where each
where each 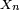 has a characteristic function
has a characteristic function 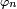 will converge in distribution towards a random variable
will converge in distribution towards a random variable 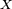 ,
,
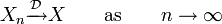
if
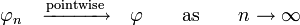
and 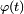 continuous in
continuous in 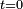 and
and  is the characteristic function of .
is the characteristic function of .
The Lévy continuity theorem can be used to prove the weak law of large numbers, see the proof using convergence of characteristic functions.
The inversion theorem
There is a bijection between cumulative probability distribution functions and characteristic functions. In other words, two distinct probability distributions never share the same characteristic function.
Given a characteristic function φ, it is possible to reconstruct the corresponding cumulative probability distribution function F:
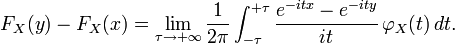
In general this is an improper integral; the function being integrated may be only conditionally integrable rather than Lebesgue integrable, i.e. the integral of its absolute value may be infinite.
Reference: see (P. Levy, Calcul des probabilites, Gauthier-Villars, Paris, 1925. p166)
Bochner-Khinchin theorem
An arbitrary function is a characteristic function corresponding to some probability law 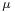 if and only if the following three conditions are satisfied:
if and only if the following three conditions are satisfied:
(1)  is continuous
is continuous
(2) 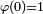
(3) is a positive definite function (note that this is a complicated condition which is not equivalent to 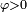 ).
).
Uses of characteristic functions
Because of the continuity theorem, characteristic functions are used in the most frequently seen proof of the central limit theorem. The main trick involved in making calculations with a characteristic function is recognizing the function as the characteristic function of a particular distribution.
Basic properties
Characteristic functions are particularly useful for dealing with functions of independent random variables. For example, if X1, X2, ..., Xn is a sequence of independent (and not necessarily identically distributed) random variables, and
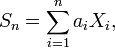
where the ai are constants, then the characteristic function for Sn is given by
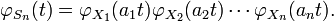
In particular, 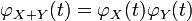 . To see this, write out the definition of characteristic function:
. To see this, write out the definition of characteristic function:
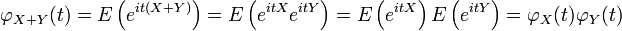 .
.
Observe that the independence of 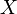 and
and 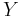 is required to establish the equality of the third and fourth expressions.
is required to establish the equality of the third and fourth expressions.
Another special case of interest is when 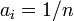 and then
and then 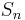 is the sample mean. In this case, writing
is the sample mean. In this case, writing 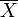 for the mean,
for the mean,
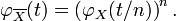
Moments
Characteristic functions can also be used to find moments of a random variable. Provided that the nth moment exists, characteristic function can be differentiated n times and
![\operatorname{E}\left(X^n\right) = i^{-n}\, \varphi_X^{(n)}(0)
= i^{-n}\, \left[\frac{d^n}{dt^n} \varphi_X(t)\right]_{t=0}. \,\!](/2009-wikipedia_en_wp1-0.7_2009-05/I/0929044f781ef542046f3b9f94862a0c.png)
For example, suppose has a standard Cauchy distribution. Then 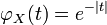 . See how this is not differentiable at
. See how this is not differentiable at  , showing that the Cauchy distribution has no expectation. Also see that the characteristic function of the sample mean of
, showing that the Cauchy distribution has no expectation. Also see that the characteristic function of the sample mean of 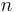 independent observations has characteristic function
independent observations has characteristic function 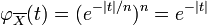 , using the result from the previous section. This is the characteristic function of the standard Cauchy distribution: thus, the sample mean has the same distribution as the population itself.
, using the result from the previous section. This is the characteristic function of the standard Cauchy distribution: thus, the sample mean has the same distribution as the population itself.
The logarithm of a characteristic function is a cumulant generating function, which is useful for finding cumulants.
An example
The Gamma distribution with scale parameter θ and a shape parameter k has the characteristic function
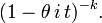
Now suppose that we have
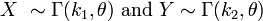
with X and Y independent from each other, and we wish to know what the distribution of X + Y is. The characteristic functions are

which by independence and the basic properties of characteristic function leads to
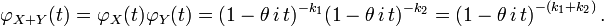
This is the characteristic function of the gamma distribution scale parameter θ and shape parameter k1 + k2, and we therefore conclude
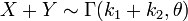
The result can be expanded to n independent gamma distributed random variables with the same scale parameter and we get
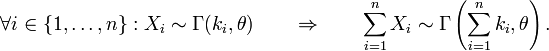
Multivariate characteristic functions
If is a multivariate PDF, then its characteristic function is defined as
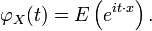
Here, the dot signifies vector dot product (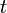 is in the dual space of
is in the dual space of 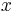 ).
).
Example
If 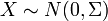 is a multivariate Gaussian with zero mean, then
is a multivariate Gaussian with zero mean, then
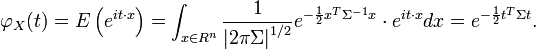
Matrix-valued random variables
If is a matrix-valued PDF, then the characteristic function is
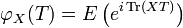
Here 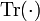 is the trace function and matrix multiplication (of
is the trace function and matrix multiplication (of  and ) is used. Note that the order of the multiplication is immaterial (
and ) is used. Note that the order of the multiplication is immaterial (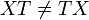 but
but 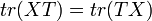 ).
).
Examples of matrix-valued PDFs include the Wishart distribution.
Related concepts
Related concepts include the moment-generating function and the probability-generating function. The characteristic function exists for all probability distributions. However this is not the case for moment generating function.
The characteristic function is closely related to the Fourier transform: the characteristic function of a probability density function 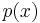 is the complex conjugate of the continuous Fourier transform of (according to the usual convention; see [1]).
is the complex conjugate of the continuous Fourier transform of (according to the usual convention; see [1]).
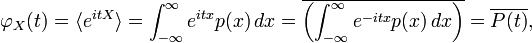
where 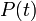 denotes the continuous Fourier transform of the probability density function . Likewise, may be recovered from
denotes the continuous Fourier transform of the probability density function . Likewise, may be recovered from 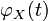 through the inverse Fourier transform:
through the inverse Fourier transform:
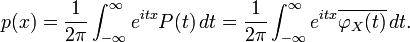
Indeed, even when the random variable does not have a density, the characteristic function may be seen as the Fourier transform of the measure corresponding to the random variable.
References
- Lukacs E. (1970) Characteristic Functions. Griffin, London. pp. 350
- Bisgaard, T. M., Sasvári, Z. (2000) Characteristic Functions and Moment Sequences, Nova Science
|
|||||||||||||